用于Transformer类模型训练的矩阵乘法器
本发明涉及用于transformer类模型训练的矩阵乘法器。
背景技术:
1、transformer是google的团队在2017年提出的一种应用于nlp(naturallanguageprocessing,自然语言处理)的经典模型,transformer模型使用了self-attention(自注意力)机制,使得模型可以并行化训练,而且能够拥有样本的全局信息。现在比较流行的bert和gpt等也是基于transformer基础结构实现的模型。
2、近几年来,基于transformer的深度神经网络(dnn)在自然语言处理(nlp)、计算机视觉(cv)和语音处理等领域取得了优异的成绩。基于transformer的模型通常是在大规模数据集上预训练,然后针对下游任务进行微调。随着transformer类模型应用场景的不断拓展,考虑到数据隐私和实时处理的要求,在边缘平台上训练(微调)此类模型变得十分重要。然而由于transformer类模型的参数量巨大,计算复杂度较高,将微调的训练过程部署在资源有限的边缘平台上面临着诸多挑战。transformer类模型的绝大部分计算由矩阵乘法构成,由于自然语言处理任务中样本长度的变化以及训练不同阶段的矩阵转置特点,模型训练过程中的矩阵乘法计算呈现出不规则特性。将这些计算部署到传统的矩阵计算架构上时,会出现资源利用率和计算吞吐量低的问题。
技术实现思路
1、发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供用于transformer类模型训练的矩阵乘法器,包括m行n列个脉动阵列,所述脉动阵列是二维的,通过r行c列个相互连接的处理单元pe(processing element,处理单元)构成,m,n,r,c均为正整数,m通常设置为2的整数幂;
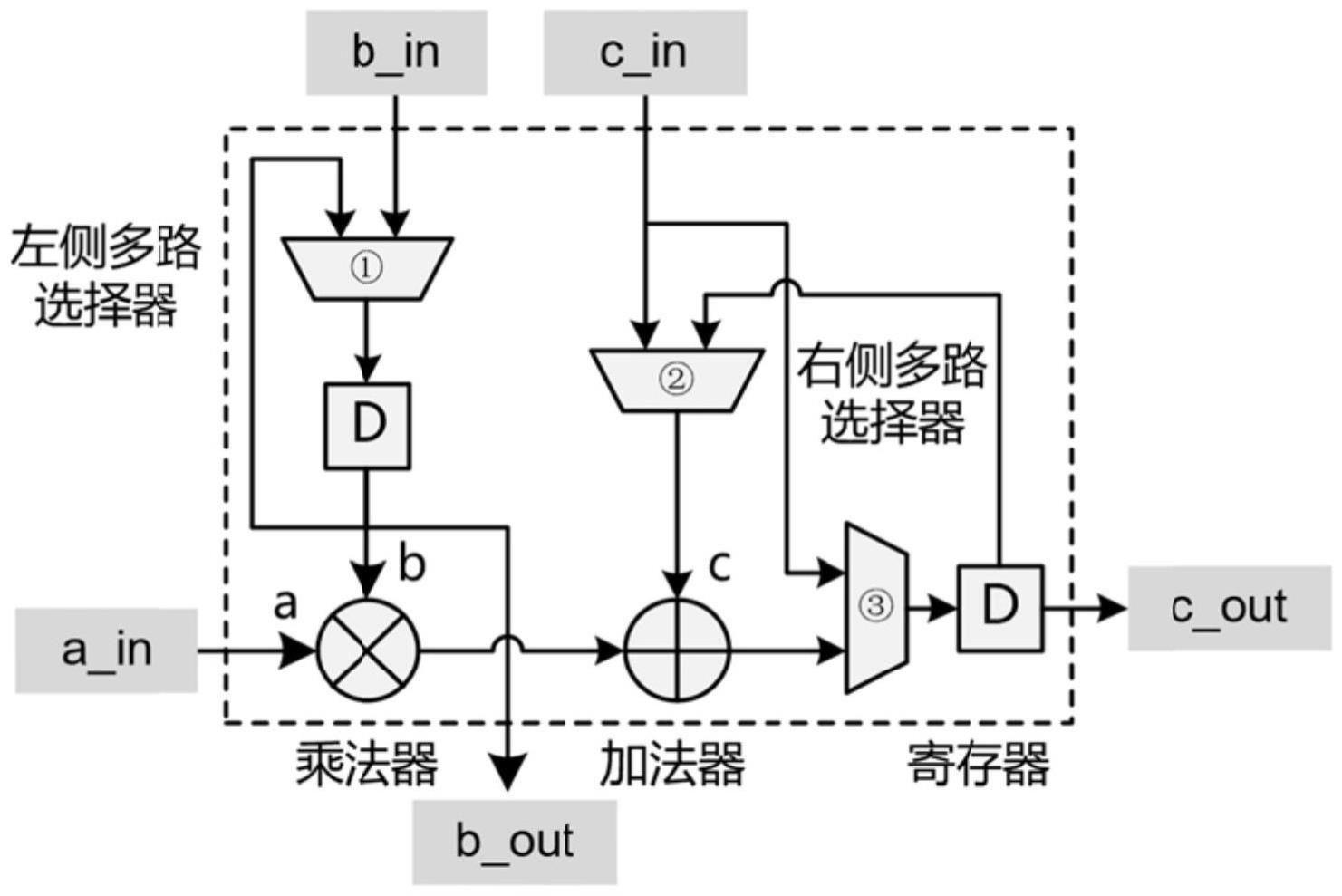
2、每个处理单元pe均包括1个乘法器、1个加法器、2个内部寄存器、1个左侧多路选择器,以及2个右侧多路选择器;
3、通过所述左侧多路选择器,能够选择乘法器的输入b是来自处理单元pe外部或是保持上一周期的输入,当选择保持上一周期的输入时,处理单元pe以权重保持ws数据流工作;
4、通过所述右侧多路选择器,能够选择加法器的输入c是来自其他处理单元pe或是本处理单元pe上一周期加法器的输出,当选择本处理单元pe上一周期加法器的输出时,处理单元pe以输出保持os数据流工作。
5、所述处理单元pe内的右侧多路选择器用于将计算结果在处理单元pe之间传递以输出到脉动阵列外部。
6、所述脉动阵列中同一行的各处理单元pe的a_in输入来自脉动阵列左侧的广播输入,即各处理单元pe的输入端口a_in均连接到脉动阵列左侧的数据输入,各列之间的由输入端口a_in输入的数据不传递;不同行的输入数据来自脉动阵列左侧不同的输入端口,即第一行的各处理单元pe共享一个输入端口a_in输入,第二行的各处理单元pe共享一个输入端口a_in输入,第三行的各处理单元pe共享一个输入端口a_in输入;
7、位于同一列的各处理单元pe,其输入b_in来自脉动阵列上方的广播输入,或者来自上方处理单元pe的b_out输出,由处理单元pe之间的多路选择器控制;
8、当选择脉动阵列上方的广播输入时,脉动阵列以输出保持os数据流工作,当选择来自上方处理单元pe的b_out输出时,脉动阵列用于输入数据预加载,以进行权重保持ws数据流的后续计算;
9、位于同一列的各处理单元pe,除了第一行的处理单元pe,其余行的处理单元pe的输入c_in来自其上方处理单元pe的c_out输出,第一行的输入c_in来自脉动阵列外部,各行之间数据c的传输能够用于权重保持ws数据流下的部分和传递和输出保持os数据流下的结果传递。
10、第一行处理单元pe的c_in输入来自脉动阵列上方。
11、当脉动阵列以权重保持ws数据流工作时,包括权重数据预加载和权重保持阶段;
12、权重数据预加载阶段:当计算处于权重数据预加载阶段时,脉动阵列内部的结构和连接方式按照下面的方式组织:来自脉动阵列上方的权重数据输入到第一行处理单元pe的b_in输入端口,其余行的处理单元pe的b_in输入来自上方处理单元pe上一周期的b_in输入,当前周期的b_out输出;权重加载到所有处理单元pe需要n个时钟周期。设定输入矩阵表示4行3列的实数矩阵,权重矩阵输出矩阵在权重加载阶段,权重矩阵的元素逐行加载到脉动阵列中对应的处理单元pe,则权重加载到所有处理单元pe需要3个时钟周期。
13、权重保持阶段:当权重矩阵的元素加载到脉动阵列中对应的处理单元pe后,进入权重保持阶段,此时,脉动阵列内部的结构和连接方式按照下面的方式组织:处理单元pe内乘法器的b输入端口一直保持为对应的权重数据;输入矩阵沿着脉动阵列的每一行广播输入,各行之间的输入数据有一个周期的时间差;部分和沿着c_in和c_out端口在各行之间传播,计算结果沿着脉动阵列下方的处理单元pe输出;设定输入矩阵权重矩阵经过各行之间部分和的累加,最终结果y11=x11w11+x12w21+x13w31,从左下角pe3的c_out端口输出,pe31表示第3行第1列的处理单元pe;x13是输入矩阵x中第1行第3列的元素,w31是权重矩阵w中第3行第1列的元素。
14、当脉动阵列以输出保持os数据流工作时,包括处理单元pe内乘累加和结果传出阶段;
15、处理单元pe内乘累加阶段:在输出保持os数据流的处理单元pe内乘累加阶段,脉动阵列内部的结构和连接方式按照下面的方式组织:来自脉动阵列上方的权重数据同时广播到一列的所有处理单元pe的b_in输入,来自脉动阵列左侧的输入数据同时广播到同一行所有处理单元pe的a_in输入;处理单元pe内部加法器的c输入连接到上一周期加法器的输出,形成一个累加器;权重数据和输入数据每个周期更新,权重数据和输入数据的乘积在处理单元pe内部累加直到计算得到最终结果;在输出保持os数据流的处理单元pe内乘累加阶段,各行与各列之间的输入和权重数据没有时间差;设定输入矩阵权重矩阵输出矩阵在乘累加阶段内的各个周期,脉动阵列内部各处理单元pe的有效输入数据和权重数据按照下面的方式组织:每个周期输入和权重数据都会更新并同时广播到其所在行或列的所有处理单元pe单元乘法器的输入,计算结果y11=x11w11+x12w21+x13w31+x14w41,在脉动阵列左上角的pe11内累加得到,pe11表示第1行第1列的处理单元pe;
16、结果传出阶段:当所有输入数据和权重数据传输到脉动阵列之内后,各元素乘积在处理单元pe内部累加得到最终结果,此时进入结果传出阶段,需要将计算结果沿各列处理单元pe的c端口从脉动阵列下方输出,结果传出脉动阵列内部的结构和连接方式按照下面的方式组织:各处理单元pe右半部分c_out输出不再连接到加法器的输出,而是连接到上方处理单元pe上一周期的c_out输出端,从而完成各处理单元pe的计算结果在脉动阵列内的移位输出。以前面所述计算过程为例,其结果沿列从脉动阵列最下面一行的处理单元pe的c_out端口输出。
17、将m行n列的脉动阵列通过片上网络的模式相互连接,组成矩阵乘法模块;所述矩阵乘法模块分别与输入内存块、权重内存块相连接;
18、所述输入内存块用于存储片外dram传输到片上的输入数据,包括m个片上缓存区,用于存储片外dram传输到片上的输入数据;输入内存块中的数据通过输入分配网络传输到各行脉动阵列,并与脉动阵列左侧的a_in输入端口相连接;各行脉动阵列共享同一个输入分配网络;所述输入分配网络是一个包含m个输入端口和m个输出端口的模块,能够实现任意输入端口到任意输出端口的连接,负责将来自不同内存块的输入数据传输到相应的脉动阵列;
19、所述权重内存块用于存储片外dram传输到片上的权重数据,包含n×c个片上缓存区,通过权重分配网络传输到各行脉动阵列,并与脉动阵列上方的b输入端口相连接;同一列的脉动阵列共享一个权重分配网络,不同列的脉动阵列使用不同的权重分配网络;所述权重分配网络是一个包含c个输入端口和c个输出端口的模块,一共有n个,能够实现任意输入端口到任意输出端口的连接,负责将来自不同内存块的权重数据传输到相应的脉动阵列;
20、所述脉动阵列下方的c_out输出端口连接一个结果生成网络,所述结果生成网络用于将脉动阵列的计算结果传输到对应的输出内存块中;
21、所述输出内存块与矩阵乘法模块连接,用于存储计算完成后的结果数据,包括n×c个片上缓存区。
22、所述输入分配网络和权重分配网络负责将来自不同内存块的数据传输到相应的脉动阵列;
23、设定矩阵乘法模块中脉动阵列的行数为m,相应的输入内存的块数也为m,使用一个m输入,m输出的m-m输入分配网络完成输入数据的路由,包含m个m输入的可配置多路选择器;
24、设定矩阵乘法模块中脉动阵列的列数为n,脉动阵列内处理单元pe的列数为c,相应的权重内存的块数为n×c,一共有n个权重分配网络,每个权重分配网络均为一个包含c个输入端口和c个输出端口的c-c网络,权重分配网络用于完成权重数据的路由,包含c个c输入的可配置多路选择器。
25、当m=4时,一个4-4输入分配网络包含4个可配置的多路选择器,送往不同行的数据来自任意一个内存块输入,由多路选择器的控制信号确定。
26、所述结果生成网络能够对脉动阵列的计算结果进行后处理,当矩阵乘法模块中的脉动阵列处于输出保持os数据流时,脉动阵列能够得到矩阵乘法计算的最终结果,并使用结果生成网络直接传输到输出内存中;当脉动阵列处于权重保持ws数据流时,结果生成网络通过一个可配置的加法树,实现任意组合的输入数据相加并输出结果。
27、所述结果生成网络的基础单元包含一种带有旁路的加法器,所述加法器使用一个基础加法器和一个多路选择器,有两个输入端口和两个输出端口;当加法器以第一种状态工作时,能够将输入的两个数据原封不动地传递到两个输出端口;当加法器以第二种状态工作时,加法器上方端口输出两个输入值的和,下方端口输出其中一个输入值;将第二种状态的加法器垂直翻转,得到加法器的第三种状态工作,加法器下方端口输出两个输入值的和,上方端口输出其中一个输入值。
28、基于所述带有旁路的加法器,构建可配置的结果生成网络,用于实现任意组合的输入值相加;
29、所述结果生成网络的输入为m时,结果生成网络的左侧有m个输入端口,分别连接到第一列的m/2个带有旁路的加法器,后面各级加法器和多路选择器均为常规结构,各级的输入端口连接到前一级结构的输出端口,各级模块之间插入寄存器形成流水线结构以提高频率和计算吞吐量,网络的输出可以来自任意内部模块的输出端口,由运行时的控制信号确定。
30、本发明针对transformer类模型训练过程中的不规则矩阵乘法计算,提出了一种灵活可重构的硬件架构,基于专门设计的处理单元以及灵活的数据分配和合成网络,可以根据计算负载的特点灵活地调整数据流和映射方案,从而更好地利用计算资源,在训练的各个阶段以实现更高的性能和能效。该发明提出的解决方法是目前首次提出、且有效的方案。
31、本发明具有如下有益效果:
32、(1)设计了一种可重构的处理单元(pe),可以在训练的不同阶段和不同周期灵活地支持多种数据流,并根据需求选择数据来源。
33、(2)基于可重构处理单元提出了一种可以灵活支持多种数据流的脉动阵列,并采用了输入数据的广播结构,以减少输入数据的传输时间和内部寄存器的资源开销。
34、(3)使用向外拓展的方式将多个脉动阵列集成到一个矩阵乘法模块中,在提高计算能力的同时保持高水平的硬件资源利用率。
35、(4)在矩阵乘法模块和数据存储模块之间设计了输入/权重分配网络和结果生成网络。数据分配网络可以根据计算负载特征将数据灵活地映射到脉动阵列之中。结果生成网络可以对计算结果进行后处理并将结果传递到输出缓存之中。
- 还没有人留言评论。精彩留言会获得点赞!