一种基于边缘计算的视频分析系统和方法与流程
本发明属于视频目标、行为分析与计算机视觉人工智能领域,特别是涉及一种基于边缘计算的视频分析系统和方法。
背景技术:
1、随着城市化的发展,传统调取式监控方式已经无法满足人们日益增长的安全和效率需求,一方面,传统监管方式主要是对监管人员进行简单培训,然后依靠监管人员进行提醒和记录违规人员信息,最后通过调取监控摄像搜集证据。有着监督效率不稳定、受监管人员精力和主观意愿影响大等缺点;另一方面,随着人工智能的发展,视觉识别在现代监控技术中有一定运用,这种技术具有反应速度快、全时段无休、监测成本低等优点。但现有的视频检测技术较多在集中式服务器,这种方式不利于检测范围较广区域,这种区域网络节点数较多、网路有效长度较大,导致网络延迟较高,无法做到及时提醒,在检测速率和准确性方面难以满足复杂、开放场景下的需求。
2、因此,为了实现现代智能化视频检测分析、提高视频分析速度,本发明提出一种基于边缘计算的智能视频分析方法及装置。采用边缘端计算的方式降低从场景变化到得出结果的传输和计算延迟,边缘终端在现场完成对视频的解码、传输、采集、目标检测推理分析、编码、转发等操作,将结果直接传输至数据中心进行反馈记录,从结构上提升计算速度。
3、如今也出现了一些基于边缘终端的视频分析方法专利,例如,中国专利申请号为202210741957.6,申请公开日为2022年9月30日的专利申请文件公开了一种基于边缘终端的智能视频分析方法及系统。该方法包括获取视频数据,基于视频数据,获取待分析图像数据;构建ai模型,通过层间融合技术对所述ai模型进行优化,通过优化后的ai模型对所述待分析样本数据进行推理,得到目标分析结果,对所述目标分析结果进行后处理,得到目标特征信息,以实现智能视频分析。该方法的不足之处在于只是使用边缘终端对视频信息进行简单分析,未考虑到计算压力骤增的情况,一般来说边缘终端的计算能力有限,需要对硬件资源进行调度或增加硬件预算。在硬件预算固定的前提下,使用算法对资源进行调度无疑是更好的选择。很明显,该方法缺少灵活性,单点设备故障率较高,容易发生宕机现象。
4、再如,中国专利申请号为202010315164.9,申请公开日为2020年7月28日的专利申请文件公开了一种结合边缘计算与深度学习的智能终端视频分析算法。该方法结合边缘计算与深度学习的智能终端视频分析算法,在边缘端设备搭载运动目标检测模型,实时处理原始视频数据,分析视频中的运动目标,有效地降低网络的延迟问题。但该方法的不足之处在于为对算法采取分时处理,实时检测视频画面使得机器一直处于满负载运行,浪费了大量可调度资源,增加功耗并缩短了硬件使用寿命。应在做到实时监测目标不漏检的前提下,增加分时检测,增加硬件可调度资源量。
5、因此,亟需开发一种基于边缘计算的视频分析系统和方法,能够快速对现场做出反应。
技术实现思路
1、1.要解决的问题
2、针对现有视频分析系统设备故障率较高且响应速度不够的问题,本发明提供一种基于边缘计算的视频分析系统,能够提升企业智能化改造时间和经济成本,提升改造效率。
3、2.技术方案
4、为了解决上述问题,本发明所采用的技术方案如下:
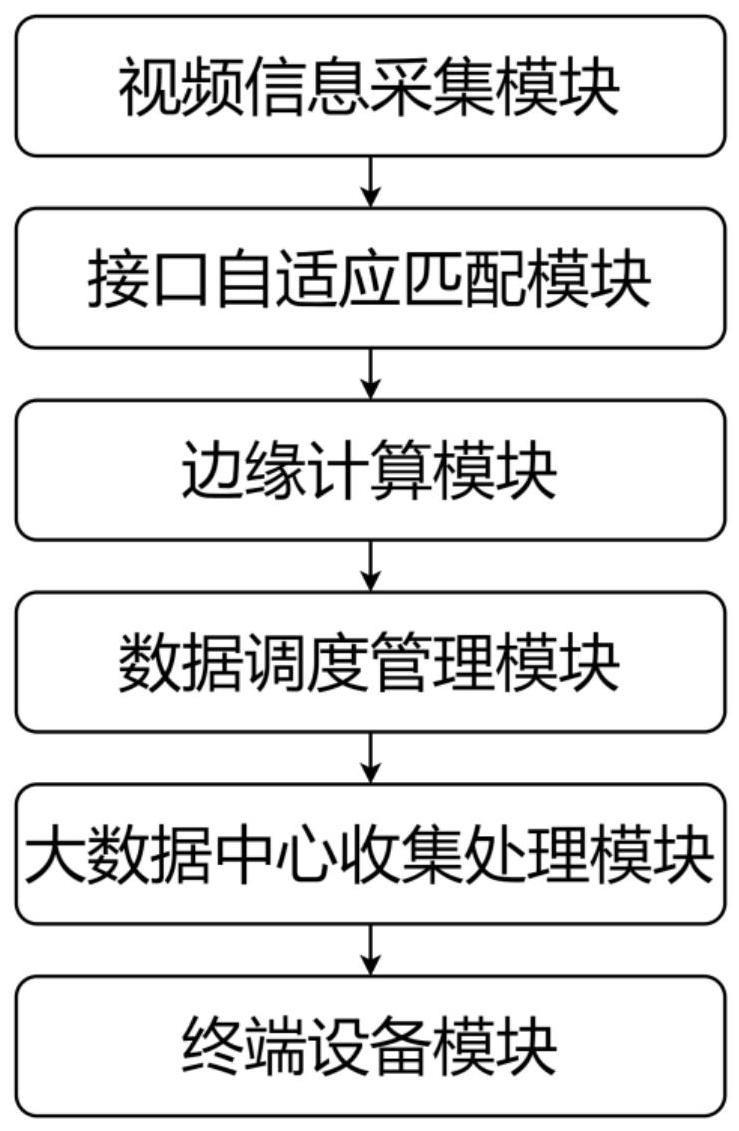
5、一种基于边缘计算的视频分析系统,包括多个视频分析装置、数据调度管理模块、大数据中心收集模块和终端设备模块,所述视频分析装置的内部集成有依次连接的视频信息采集模块、接口自适应匹配模块和边缘计算模块;其中,接口自适应匹配模块可选rj45接口适配器,能够自动识别对应接口所连设备,即自动识别视频信息采集模块设备接口并分配ip地址,视频信息采集模块获取视频数据传输至边缘计算模块,边缘计算模块可选边缘计算核心板,对视频数据进行计算处理,识别目标信息传输至数据调度管理模块,数据调度管理模块对各个边缘计算模块进行动态调整资源策略,根据目标信息的大小分配给相应的边缘计算模块计算目标信息的锚框,最终将计算后的目标信息上传至大数据中心收集模块,大数据中心收集模块筛选计算后的目标信息后将其传输至终端设备模块,以供查阅。
6、一种基于边缘计算的视频分析方法,包括多个视频分析装置、数据调度管理模块、大数据中心收集模块和终端设备模块,其中,视频分析装置的内部集成有依次连接的视频信息采集模块、接口自适应匹配模块和边缘计算模块;视频分析系统的视频分析方法步骤为:
7、(1)首次通电后,接口自适应匹配模块进行设备初始化,即接口自适应匹配模块能够自动识别所连视频信息采集模块中的连接设备种类是摄像头、ip音柱或是其他rj45接口设备,并为其分配好ip地址;接口统一使用rj45接口,可随意对设备进行接口切换和数量的改变。所述接口自适应匹配模块介于视频信息采集模块和边缘计算模块之间,实时对两者之间的通信进行适应转换。
8、(2)初始化完成后,视频信息采集模块实时采集现场视频,并对视频画面进行rtsp流媒体,以视频流的方式转发至边缘计算模块;
9、(3)边缘计算模块为能够运行深度学习算法、使用网络进行通信的核心边缘计算板;边缘计算模块接收视频信息之后自动对视频流进行取帧处理(2帧/s),使用深度学习算法,对所取帧图像进行轻度卷积计算,判断当前视频场景是否存在目标,若不存在,则停止本次卷积,进入微待机状态等待下一次计算;若存在,则继续进行深度卷积,定位目标位置,进一步计算目标类别并将结果传输至数据调度管理模块。其中,轻度卷积为对视频流每秒取两帧图像进行卷积运算,同时在卷积过程中选取二分之一图像大小的卷积核进行计算(卷积核越大计算压力越小,但准确度越低),以此进行轻量化的卷积。深度卷积为对视频流全25帧画面进行实时卷积,同时卷积核大小为图像的四分之一。以此增加目标检测的准确度。
10、进一步地,所述深度学习算法包括ssd算法、yolo系列算法、r-cnn系列算法、ssp算法等基于tensorflow或pytorch算法。
11、(4)数据调度管理模块对各个边缘计算模块进行动态调整资源策略,根据边缘计算模块当前gpu和cpu的综合使用率计算综合压力值p,通过p取值进行权重和资源调度分配,自动选择计算模型权重s,l并联合其余设备资源进行计算。即根据p值选择运行l权重或s权重的边缘计算模块对视频流进行计算,其中,l权重比s权重大,l权重的速度小于s权重的速度,l权重的计算准确率高于s权重;
12、若当前边缘计算模块对视频流计算压力p:p<p1,则采用精准模式,使用运行l权重的边缘计算模块;
13、若当前边缘计算模块对视频流计算压力p:p1<p<p2,则采用快速识别模式,使用运行s权重的边缘计算模块;
14、若某单个边缘计算模块场景中突然并入大量待检测目标,即p>p2,为防止宕机,视频信息采集模块将此点的视频流同步转发至数据调度管理模块,数据调度管理模块对该视频流进行转发至其余运行l权重的边缘计算模块,并将该运行l权重的边缘计算模块的权重转为s,计算完成后,将计算结果通过数据调度管理模块返回转发至原边缘计算模块,原边缘计算模块对结果进行整合之后,完成后续操作,最终将有关目标信息上传至大数据中心收集模块供后续查看、管理;
15、例如,以a边缘计算模块场景中突然并入大量待检测目标(p>p2),为防止机器宕机,则将a点视频流同步转发至数据调度管理模块,数据调度模块将对视频流进行转发至其余运行l权重计算核心(b集群),并将b集群核心权重转为s,节省更多资源供分担a计算使用。计算完成后b集群将计算结果通过数据调度管理模块返回转发至a,a对结果进行整合之后,完成后续操作。最终数据交换模块将有关目标信息上传至大数据处理模块供后续查看、管理。
16、其中,p1、p2为设定阈值,p1<p2;
17、(5)大数据中心收集模块对所有接收信息均采取保留态度,根据用户需求,筛选信息后,将用户感兴趣信息传输至终端设备模块,供用户查阅,同时配合自研管理系统能够实时查看当前现场识别画面、现场对讲、历史违规信息查验、流量统计、数据自动导出和图像下载的功能,并将结果传输至终端设备模块。
18、进一步地,所述视频信息采集模块包括摄像机和现场播放的ip音柱,彼此通过接口自适应匹配模块相连,可实现上下行全双工通信;其中,所述摄像机采用rtsp协议推流方式,视频采用h.265视频编码格式。
19、进一步地,所述接口自适应匹配模块包含四个rj45接口,与边缘计算模块相连,接口自适应匹配模块将使用可读介质信息通过udp通信协议向接口所连视频信息采集模块的设备发送校对信息,并根据设备回复信息确定设备类型并分配ip。
20、进一步地,所述可读介质信息存储在边缘计算模块的rom中,可读介质信息存储识别文件和相关计算机指令,对用户透明且不可更改,只允许系统自动读取。
21、进一步地,所述边缘计算模块板载有一块arm架构64位cpu,一块nvidia gpu用于cuda加速,一块板载rom,内存为4g,一块64g存储卡,用于运行深度学习算法。
22、进一步地,步骤(3)中,所述微待机状态并非进入传统意义上的待机状态,而是保持最低功率和最小cpu、gpu资源运行,一旦监测到场景中出现目标,可在0.5s内恢复全功率运行,摆脱传统全时段全功率运行策略。
23、进一步地,步骤(4)中,计算综合压力值p的方法为:
24、p=usagecpu*50%+usagegpu*50%,usagecpu为cpu使用率,usagegpu为gpu使用率;
25、usagecpu=(runtimecpu/totaltimecpu)*(use_imfcpu/capcpu),runtimecpu为cpu执行时长,totaltimecpu为cpu总时长,use_imfcpu为cpu使用信息,capcpu为cpu最大处理能力,其中:
26、runtimecpu=tnow-tlast
27、totaltimecpu=(tnow-tlast)*numcore
28、use_imfcpu=∑i∈core∑f∈freqf*runtimei*weighti
29、capcpu=∑i∈core mas_f(i)*totaltimecpu*weighti;
30、tnow为当前采样时刻,tlast为最近一次采样时刻,numcore为可用核心数,i为核心序号,core为所有核心集合,f为第i个频点的频率,runtimei为第i个频点运行时长,weighti为i的核心权重,mas_f(i)为i核心的最大频率;
31、usagegpu=(runtimegpu/totaltimegpu)*(use_imfgpu/capgpu),runtimegpu为gpu执行时长,totaltimegpu为gpu总时长,use_imfgpu为gpu使用信息,capgpu为gpu最大处理能力,其中:
32、runtimegpu=tnow′-tlast′
33、totaltimegpu=(tnow′-tlast′)*numcore′
34、use_imfgpu=∑j∈core∑f′∈freqf*runtimej*weightj
35、capgpu=∑j∈coremas_f(j)*totaltimegpu*weightj;
36、tnow′为当前采样时刻,tlast′为最近一次采样时刻,numcore′为可用核心数,j为核心序号,core为所有核心集合,f′为第j个频点的频率,runtimej为第j个频点运行时长,weightj为j的核心权重,mas_f(j)为j核心的最大频率。
37、进一步地,所述大数据中心收集模块为高性能服务器集群,将处理前后的数据进行保存,并将处理后的数据进行加密传输。
38、进一步地,所述终端设备模块通过http、tcp、ftp或rtsp协议对数据信息进行接收,并显示在多种终端设备上,所述终端设备可以通过各种形式实施。例如,本发明中提到的各种终端可以包括手机、车载电话、笔记本电脑、广播接收器、pad(平板电脑)和计算机等。
39、进一步地,所述深度学习算法为优化后的深度学习算法,使用动态锚框技术自适应目标锚框大小。优化后的深度学习算法将传统运行在x86 cpu上的算法,通过轻量化调整移植到64位arm架构cpu上;传统深度学习训练锚框的生成是自项而下且固定的,不能进行动态调整,容易产生先验信息不匹配问题;使用动态锚框技术自适应目标锚框大小,有效解决传统固定锚框引起的分类收敛速度慢问题。对于任一非端的特征图点与锚点生成有关数据信息同时来自上下层,能够通过及时接收信息和计算每次的速度损失值,故针对同一帧图像目标大小不一问题,可以自适应地根据对应损失值调整最适合对应目标的锚框,增加了目标检测收敛速度,提高了准确率。
40、优化后的深度学习算法其速度损失值计算为:
41、
42、
43、
44、其中,m表示本帧图像中实际输出的目标类别数,m为其下标序号(取值从1开始),n表示训练集中标识的目标值种类数,n表示人工标注的单帧图像的真实框下标,areamn表示对应检测m和人工标注n的锚框面积差,f为调整函数,flag表示预测框于真实框大小对比情况,flag为-1时,缩小锚框,flag为1时,放大锚框,iou表示交并比:真实框和预测框两者面积的交集与并集的比值。
45、进一步地,所述视频分析装置的外壳上两侧各连接托板,托板上安装ip音柱和摄像头。视频分析装置中还包括显示屏、散热风扇
46、和防尘散热金属盖板;所述显示屏用于显示网络信号、设备连接情况和最新输出信息,优选4.5英寸显示屏;所述散热风扇用于散热,优选功率为4w的散热风扇;视频分析装置的两侧开孔,开孔处设置防尘散热金属盖板将其覆盖,所述防尘散热金属盖板表面开设透气孔,透气孔的直径可以为0.1mm,每两个开孔间隔1mm,透气孔内部涂有疏水材料,提高透气孔疏水能力;同时防尘散热金属盖板的中间嵌有防水透气膜,此膜能够在保证散热的情况下兼顾防尘效果。
47、进一步地,所述防尘散热金属盖板由上防水板和下防水板组合对视频分析装置两侧的开孔进行覆盖,其中上防水板为折弯板,其表面开设透气孔,并且内嵌防水透气膜,下防水板为实心,一端连接视频分析装置的外壳,并与上防水板连接对视频分析装置两侧的开孔进行覆盖。
48、3.有益效果
49、相比于现有技术,本发明的有益效果为:
50、本发明基于边缘计算的视频分析系统和方法可以降低企业智能化转型成本,节约转型时间,同时延迟低、硬件资源利用率高。
- 还没有人留言评论。精彩留言会获得点赞!