一种融合对话上下文信息的自然语言理解方法与装置与流程
本发明属于人工智能技术人机对话系统中的自然语言理解领域,具体是涉及一种融合对话上下文信息的自然语言理解方法与装置。
背景技术:
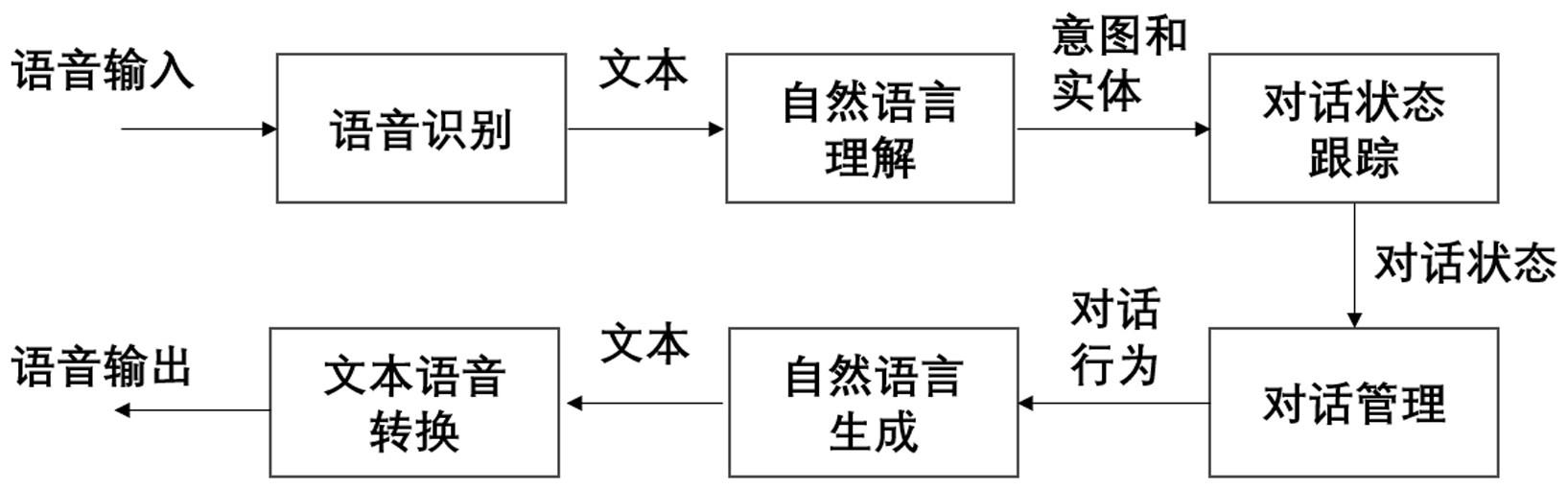
1、现有的人机对话系统通常采用如图所示的单向管道架构,由语音识别、自然语言理解、对话状态跟踪、对话管理、自然语言生成、文本语音转换六大模块组成,信息在各个模块之间单向序贯地流动。其中自然语言理解、对话状态跟踪和对话管理三大模块起着最核心的作用。自然语言理解模块负责理解和提取用户输入语言中所包含的对话意图与关键信息,对话状态跟踪模块将自然语言理解对每句话的处理结果进行整理和保存,对话管理模块根据对话状态跟踪模块所维护的信息进行对话规划和决策。在现有的技术中,自然语言理解模块只根据当前的输入语句来理解其意图和提取信息,而不能利用对话状态跟踪和对话管理模块中所记录和预测的对话上下文信息来更准确地分析理解当前语句。
2、与本发明最相似的现有技术实现方案,以及现有技术的缺点:
3、其它相关专利的对比说明。
4、随着人工智能技术与人机对话系统的发展与推广,出现了多个对话系统中的意图识别应用等,具体如下:
5、专利cn202010250336《对话意图类型识别方法、多轮对话方法、装置及计算设备》将当前轮的文本进行实体和意图识别,并与历史对话的文本的实体与意图识别结果拼接得到一个综合的向量输入至分类器来对当前轮的意图进行识别。此发明虽然利用了部分的历史对话数据,但没有利用其它对对话任务和意图理解非常关键的信息,包括结构化的对话状态数据和系统在之前对话中对用户输出的行为。此外,该发明只是将每个文本上得到的结果做简单拼接,而没有采用transformer编码器等先进的序列模型来处理对话的历史信息。
6、专利cn202210163464《用户对话意图的识别方法、装置、存储介质和电子设备》根据预设的置信度和规则来确定本轮对话的当前句子对应的对话意图,其意图判断规则可以结合前文中的意图来判断当前的意图,但是这种通过人工设定的规则来判断的方式缺乏灵活性和可迁移性,也没有严格的数学原理。
7、专利cn201810521599《一种基于记忆网络的多轮对话下的意图识别方法》使用循环神经网络对对话的历史记录进行编码并用注意力机制来选择跟当前相关的内容来辅助识别当前的对话意图,此发明只利用了基本的文本信息,没有利用文本词向量之外的其它可用特征,也没有利用结构化的对话状态等信息。
8、专利cn201910588106《一种任务型多轮对话中的复杂意图识别方法》使用循环神经网络来对对话的历史语句进行建模并用于预测当前的意图,同时还采用了一个基于马尔科夫模型的意图转移矩阵来预测用户下一个可能的意图。此发明对对话历史的建模仍然只是基于句子文本本身的信息,没有利用结构化的对话状态信息和系统的输出信息,基于马尔科夫模型的意图预测也只能根据前一轮次的意图来预测下一轮意图,不能很好的利用完整的对话历史信息来对后续意图做出更准确的预测。
9、专利cn202110458561《多轮对话的意图分类方法及装置》使用循环神经网络来对对话的历史语句进行建模并预测每一轮对话语句的意图,此发明仍然只是使用了文本本身的信息来对意图进行分类,循环神经网络对较长序列的建模表征能力也不及基于自注意力机制的transformer网络模型。
10、专利cn202110909637《对话意图识别、用于识别对话意图的模型的训练方法》使用图神经网络来对对话历史中的任意两句话之间的关系进行建模分析并辅助用于预测每句话的对话意图,但是图神经网络对于任意长度的序列的建模能力通常不及基于自注意力机制的transformer网络,采用transformer网络来对多轮对话进行建模分析是更加灵活和高效的手段。
11、专利cn202111564185《一种自然语言对话系统意图深度学习方法》将待解析的对话文本与其语音及情绪信号一起输入深度学习模型进行对话意图的识别,提高了对话意图识别的准确率,但是此发明并未利用任何的对话历史和对话状态信息。
12、在多轮的人机对话中,对话的上下文信息通常会对正确地理解用户的语言起到重要的作用,同样的一句话,放在不同的对话上下文中,往往会导致不同的理解。例如,当用户与一个心理咨询预约系统对话时,用户当前输入语句是“上一次是周老师给我做的咨询”,其对应的意图可能理解为继续预约同一位咨询师(周老师),也可能理解为用户这次想要预约其他不同的咨询师,哪种理解正确取决于之前已发生的对话内容以及之后将要发生的对话。因此,在多轮的人机对话系统中,对用户当前输入语句的准确理解需要结合对话前文的信息以及对后续可能对话的预测。
13、与专利cn 112307774 a的对比:
14、该专利通过将先前对话内容以及预设的对话解析模板共同作为对话理解模型的输入,理解分析当前的对话状态。该方法虽然可以利用对话历史和特定领域信息来提高对话理解准确度,但是需要手工来编写和选取相应的对话解析模板,这一过程依赖于领域专家的知识且费时费力。本专利申请无需手工编写对话解析模板或其它专门信息,充分运用机器学习方法从数据中学习对话理解模型,并且可以利用对话状态追踪模块自动输出的结构化信息,在提高对话理解准确度的同时减少了系统开发和训练对特定领域知识的需求。
15、与专利cn 113692617 a的对比:
16、该专利运用机器学习模型将当前对话输入与先前上下文信息结合来提升对话意图理解准确度。该专利并未明确提出运用何种机器学习模型进行对话上下文的建模以及当前意图理解,且其对话上下文信息仅包含过往的用户意图和实体。本专利申请所利用的对话上下文信息不仅包含用户的过往意图和实体,同时包含系统过往的行为与输出,因此对对话上下文信息的利用更加完整,更加符合对话理解的基本逻辑。本专利申请明确提出运用当前最先进的transformer序列化模型对对话上下文进行建模和预测,同时基于贝叶斯概率理论进行当前语句分析和对话上下文分析的结果融合,具有明确的模型和理论支持。
技术实现思路
1、为了提高多轮人机对话场景中自然语言理解的准确度,本发明将对话的历史信息以及对用户后续可能的对话意图的预测结合到自然语言理解的算法模型中,提出一种结合对话上下文信息的自然语言理解方法与系统。
2、本发明为了实现上述目的采用以下技术方案:
3、本发明提供了一种融合对话上下文信息的自然语言理解方法,包括以下步骤:
4、步骤1、特征提取:将用户输入的当前自然语言文本,即当前语句转化成数字向量表示,将非结构化的自然语言文本所包含的信息转换成计算机可以处理和分析的结构化信息,最终得到每个词语的词特征向量,从而得到词特征向量序列;
5、步骤2、意图识别和实体抽取:运用神经网络transformer编码器模型处理输入自然语言文本中语句的分词的结果和特征提取后得到的词特征向量序列,利用transformer编码器对意图识别和实体抽取,得到当前语句意图的推测概率和当前语句的各个词语的实体标注结果,即得到意图识别结果和实体抽取结果;
6、步骤3、意图融合:将步骤2得到的用户输入的当前语句的意图识别结果和由上一轮得到的基于对话历史记录d对用户可能在当前轮输入意图的预测进行结合后,得到当前用户输入语句的融合意图识别结果,即得到融合意图;
7、步骤4、对话状态跟踪:基于步骤3得到用户当前输入语句的融合意图识别结果和步骤2得到的实体抽取结果来填写一系列预先设定的对话状态属性的值,其中对话状态是{属性 : 值,……,属性 : 值} 构成的集合,对话状态跟踪的结果最后通过one-hot编码方式转换成一个二值化的对话状态特征向量,即得到对话状态 ,对话状态作为接下来的用户意图预测和下一轮对话中意图识别的输入;
8、步骤5、用户意图预测:使用transformer解码器模型根据对话过程的对话历史记录d与步骤3得到的融合意图结合实现对用户接下来最可能输入的意图预测,为下一轮次步骤2中的意图识别提供参考的基准;下一次轮次的意图识别将根据用户输入语句本身的信息和根据对话历史已作出的意图预测来综合判断用户最可能的意图。
9、上述技术方案中,步骤1具体包括以下步骤:
10、步骤1.1、中文分词:
11、分词操作通过序列标注方法将用户输入的自然语言文本中的各个词语识别并分离开,使得语句从一个字序列变成一个词序列表示,得到分词的结果;
12、步骤1.2、构建稀疏向量特征:
13、运用词典匹配或者正则表达式匹配方法,首先识别出输入的自然语言文本的关键词、短语、特殊形式这些特征信息,将得到的特征信息表示为一系列的“one-hot”稀疏向量并拼接在一起,得到输入语句的稀疏向量特征表示,从而得到稀疏向量特征;
14、步骤1.3、获取词嵌入向量特征:
15、基于分词的结果,从预训练的中文词嵌入词表中获取每个词语的词嵌入向量表示,从而得到词嵌入向量特征;
16、步骤1.4、特征融合:
17、稀疏向量特征包含了与任务相关的语言信息,而词嵌入向量特征则是表征了通用的语法语义信息,特征融合将两者结合在一起形成最终的特征向量,其操作为通过训练一个前馈神经网络将稀疏向量特征转换为一个稠密向量再与词嵌入向量特征拼接得到每个词语最终的词特征向量表示 :
18、
19、上式中 ffn()指前馈神经网络。
20、上述技术方案中,步骤2具体包括以下步骤:
21、步骤2.1、意图识别
22、根据语句的步骤1得到的词语特征向量和当前的对话状态向量来识别当前用户输入语句所包含的意图,具体的为,
23、根据对话系统要完成的任务预先设定所有用户可能对系统说出的用户意图,意图识别成为一个文本分类问题,即语句的识别意图:
24、
25、这里表示意图识别结果,i表示intent,表示词特征向量序列,表示当前的对话状态向量,()求取使得目标函数得到最大值的;
26、是由深度学习模型计算得到的条件概率,即综合了语句文本特征和对话状态特征对当前语句意图的识别概率,其具体计算步骤如下:
27、先运用transformer编码器对词特征向量序列进行编码,编码时加入特殊的cls标识符并运用transformer的自注意力机制将语句中每个词语的特征以及词语之间的相互关联特征汇总到cls标识符的编码中输出,得到语句编码向量;
28、将状态向量通过一个前馈神经网络转换成稠密的特征向量,与cls标识符输出的语句编码向量拼接,最后再通过一个前馈神经网络和归一化层得到输出的意图推测概率;
29、步骤2.2、实体抽取
30、实体抽取被建模为一个序列标注问题,即搜索一个实体标注序列使得联合概率最大化,这里的 对应输入自然语言文本中每一个词的实体标注结果;
31、实体抽取也通过transformer编码器对输入语句中的每个词进行编码,每个词语的特征向量通过一个前馈网络输入transformer编码器,transformer编码器使用自注意力机制将每个词语与语句中其它词语的特征融合,最后再通过一个条件随机场模型计算得到各个词语的实体标注结果,即得到实体抽取结果;
32、对意图识别和实体抽取联合建模与训练
33、意图识别和实体抽取是两个紧密关联的任务,不同的意图对应了不同的实体,训练transformer和神经网络相关参数时将意图识别和实体抽取进行联合建模与训练,即在给定的已标注训练数据集上使用以下交叉熵损失函数进行模型参数训练:
34、;
35、其中为交叉熵损失函数。
36、上述技术方案中,步骤3包括以下步骤:
37、意图融合:当前用户输入的语句的识别意图和基于对话历史对用户可能输入意图的预测意图结合后,得到新的当前用户输入语句的融合意图:
38、
39、其中()求取使得目标函数得到最大值的融合意图,表示当前用户输入语句的识别意图,表示当前输入语句分词后的特征向量序列,表示当前的对话状态,表示对话历史记录,其中,
40、
41、其中表示在一个对话轮次中系统输出的行为,表示当前对话的轮次,表示词特征向量序列,表示当前的对话状态, 是基于对话历史记录和当前状态对用户可能输入的意图的预测,是用户在不同对话状态下可能输入的意图的先验概率,先验概率可直接从训练数据中统计获得,即对应的情况在训练数据中出现的频率。
42、上述技术方案中,步骤5中,用户意图预测使用transformer解码器模型根据对话过程的历史记录d对用户接下来最可能输入的意图进行预测,得到预测意图,预测意图为下一轮次的意图识别提供参考的基准,下一次轮次的意图识别将根据用户输入语句本身的信息和根据对话历史已作出的意图预测来综合判断用户最可能的意图。
43、上述技术方案中,预测意图的具体实现如下:
44、对历史记录d中的… …,均采用1-hot向量表示,拼接后通过前馈网络编码输入transformer单向解码器,transformer单向解码器从前向后依次将每一轮次的输入转换为内在状态表示,最后将轮得到的内在状态通过一个前馈网络和softmax归一化后得出对用户在下一轮最有可能输入的意图的预测,即得到当前轮的预测意图。
45、因为本发明采用上述技术方案,因此具备以下有益效果:
46、一、本发明采用该反馈式的系统架构,自然语言理解模块可获取对话上下文相关信息并融合到其算法模型中,主要过程包括通过深度神经网络transformer的编码器模型来将对话状态中维护的结构化信息融合进自然语言理解模型中,同时通过transformer解码器模型来根据对话历史信息预测用户可能的后续意图,最后通过基于贝叶斯概率原理的计算模块将理解与预测的结果结合,最终得到最为符合对话上下文语境信息的理解结果。
47、二、本发明基于当前用户输入的意图识别和基于对话历史对用户可能输入意图的预测进行意图融合,充分利用了输入语句本身和对话历史的信息,对话历史的信息包含了对话从第一轮直到当前的前一轮的关键历史信息,可以进一步提高对当前用户输入意图的准确理解,达到提高多轮对话中意图识别准确度的效果。
48、三、在多轮对话中,用户的输入意图往往受到之前的对话过程,尤其是系统对用户输出过的行为的影响。因此本发明引入一个单独的意图预测步骤,使用transformer解码器模型根据对话过程的历史记录对用户接下来最可能输入的意图进行预测,为下一轮次的意图识别提供参考的基准。下一次轮次的意图识别将根据用户输入语句本身的信息和根据对话历史已作出的意图预测来综合判断用户最可能的意图。
49、四、本发明充分运用深度学习transformer神经网络对文本处理和序列建模的强大能力,使用transformer编码器将稠密的词义向量和稀疏的语言及对话状态向量联合编码,充分利用各种相关信息来提高意图识别的准确率,同时使用transformer解码器来对对话历史进行长序列的建模以及重要信息的筛选,根据对话不断展开的过程来动态预测用户接下来可能的输入意图,进一步提升系统理解和管理对话的能力。
- 还没有人留言评论。精彩留言会获得点赞!