基于损伤驱动和多模态多任务学习的结构巡检智能体导航方法
本发明直接所属的研究领域包括结构健康监测、计算机视觉、深度学习,可以直接应用的包括智能建造、智慧基础设施、智慧运维等,尤其涉及基于损伤驱动和多模态多任务学习的结构巡检智能体导航方法。
背景技术:
1、地震给土木工程结构带来了不同程度的损伤,对在地震中受损的建筑结构进行损伤检测具有重要的意义,可以进一步评估建筑结构的受损状态和安全性、评估经济损失以及为后续的恢复和重建提供重要依据。对于震后的建筑结构内侧的损伤状态评估,传统的基于计算机视觉的检测方法依赖于人工采集图像信息,这样的采集方法缺乏安全性且成本昂贵。
2、本发明的研究目的是提供解决建筑结构内部损伤扫描式检测智能体导航方案,进而实现安全、智能化的结构健康巡检。智能体和机器人涵盖了环境感知、路径规划、机械结构、运动控制等等核心技术,智能体和机器人可以实现感知、决策、运动、执行任务,近年来与多种学科交叉,尤其是在医学、自动驾驶、航空航天等领域,取得了显著成就。例如,波士顿动力公司研发的机器人“spotmini”具有强大的感知能力、运动能力,最大负重15kg,可以完成一般的巡逻任务和货物搬运工作。特斯拉公司研发的人形机器人teslabot,通过力反馈实现机身平衡,依据计算机视觉进行环境感知、人机交互。智能体和机器人带来人们生活的巨大改变,也在逐渐改变了未来的工业发展,与土木工程行业的交叉发展是必然趋势。然而,现有的土木工程巡检智能体或机器人视觉导航方法存在以下难题:
3、(1)目前普遍采用的智能体导航虚拟环境之中缺乏土木工程结构的损伤信息,难以实现虚拟环境与所收集的结构损伤图像数据集之间的交互建模。
4、(2)深度强化学习方法需要的训练回合数往往在数百万甚至千万量级,在真实系统上采集如此庞大体量的交互信息是几乎无法实现的,亟需创建适用于土木工程结构智能巡检导航的虚拟环境。
5、(3)基于传统深度强化学习的视觉导航方法缺乏长期记忆功能,难以在陌生环境下保证泛化能力。
6、(4)传统视觉导航方法大都仅仅依赖于视觉感知信息,而缺乏深度信息等多模态信息融合,在视觉表象干扰场景下的模型稳定性有待提高。
技术实现思路
1、针对现有技术的技术问题或改进需求,本发明提出了基于损伤驱动和多模态多任务学习的结构巡检智能体导航方法。
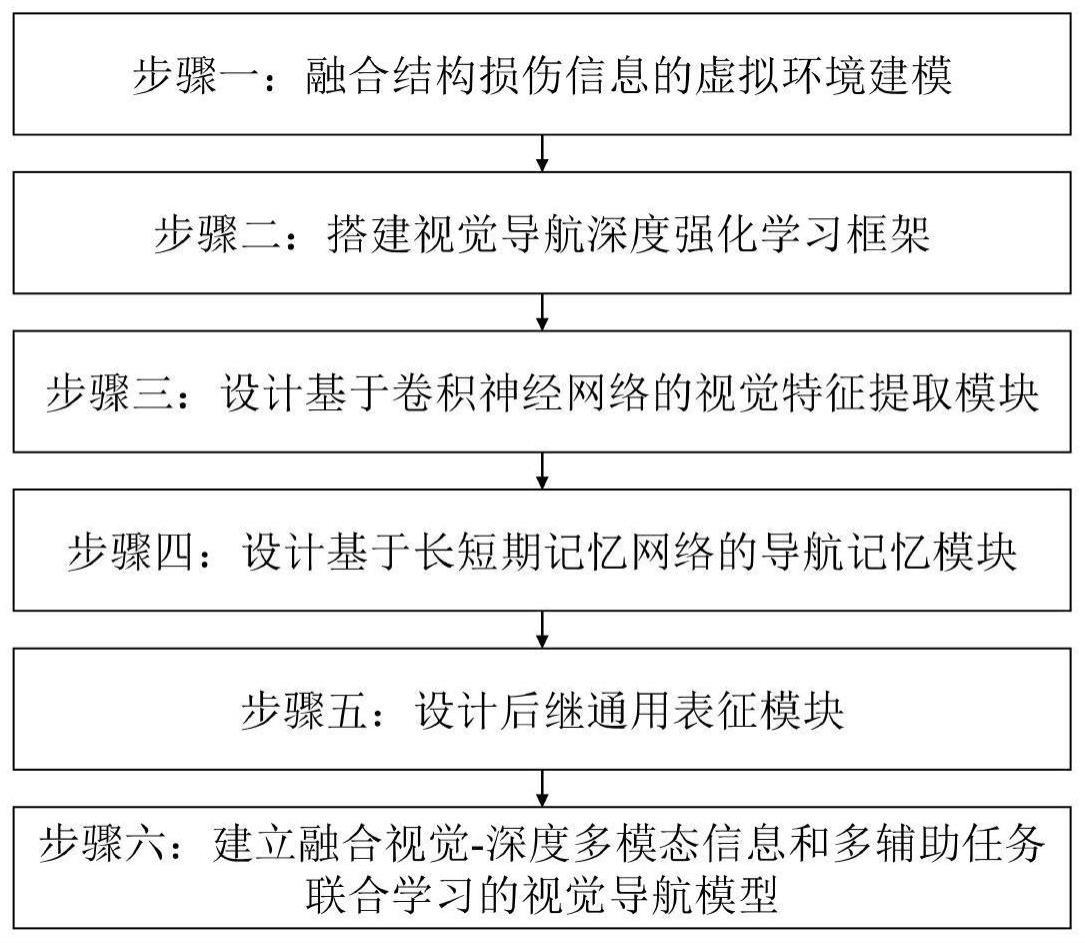
2、本发明是通过以下技术方案实现的,本发明提出基于损伤驱动和多模态多任务学习的结构巡检智能体导航方法,所述方法包括以下步骤:
3、步骤一:融合结构损伤信息的虚拟环境建模:在ai2thor实验环境中设计适用于实际场景结构损伤驱动视觉导航任务的训练环境,通过收集实际场景中震后建筑结构的损伤图像信息,将损伤图像融合到ai2thor的3d环境中,构建带有不同类型结构表观损伤的建筑室内环境;
4、步骤二:搭建视觉导航深度强化学习框架:搭建结构损伤驱动的视觉导航任务深度强化学习框架,建立结构损伤驱动的深度强化学习视觉导航模型;
5、步骤三:设计基于卷积神经网络的视觉特征提取模块:所述视觉特征提取模块由预训练深度残差神经网络和基于注意力机制改进的孪生神经网络组成,获得损伤目标图像和智能体观测图像特征;
6、步骤四:设计基于长短期记忆网络的导航记忆模块,增强对损伤目标和状态信息融合特征的记忆能力;
7、步骤五:设计后继通用表征模块,对值网络进行解耦,提高泛化能力;
8、步骤六:建立融合视觉-深度多模态信息和多辅助任务联合学习的视觉导航模型,进一步提高模型的泛化能力和导航性能。
9、进一步地,步骤一进行融合结构损伤信息的虚拟环境建模,具体包括以下步骤:
10、步骤一一:建立初始虚拟实验环境;基于ai2thor的交互式视觉环境,采用unity3d的室内环境与tensorflow交互进行智能体训练;
11、步骤一二:结构损伤信息融合;基于ai2thor初始室内导航环境,融合建筑损伤信息,适应土木工程结构损伤场景的导航任务需求,将建筑损伤信息添加到3d环境中;
12、步骤一三:以结构损伤图像作为目标,采集智能体在虚拟环境运动过程中的第一视角图像,为完成结构损伤信息驱动的视觉导航任务奠定数据基础。
13、进一步地,步骤二搭建视觉导航深度强化学习框架,具体包括以下步骤:
14、步骤二一:建立损伤驱动的结构巡检智能体视觉导航数学模型;
15、将智能体在损伤建筑结构内部的运动过程看成是一个部分可观测马尔可夫过程,在损伤驱动视觉导航模型中,智能体获取的是观测图像st和损伤目标的图像信息dg,通过深度学强化学习训练一种导航策略,使得智能体可以获取最大化收益,即能以相对短的路径从起点运动到损伤目标处,并避开环境中的所有障碍物,这个过程的目标是训练一个策略网络:
16、a~π(st,dg|θ) (1)
17、式中,a为观测图像st和损伤目标的图像信息dg通过神经网络映射得到的智能体动作,π表示策略网络,θ表示网络参数;
18、步骤二二:基于a3c网络架构作为深度强化学习的极限模型,训练得到一个值函数网络,用来指导策略网络π的更新;
19、观测图像st和损伤目标的图像信息dg作为整个网络结构的输入,观测图像st是随着智能体在环境中运动不断变化的实时观测信息,输入图像经过以卷积神经网络为基础的深度学习网络提取高维特征,高维特征输入深度强化学习网络drl学习智能体的运动策略。
20、进一步地,步骤三设计基于卷积神经网络的视觉特征提取模块,具体包括以下步骤:
21、步骤三一:智能体观测图像的位移噪声和转角噪声设置;
22、为模拟现实世界的观测误差,对在虚拟环境中智能体观测到的第一视角图像进行预处理,获得在同一位置、视角出现轻微偏差时的采样图像;首先对原始观测图像进行等比例放缩,采用224×224的窗口滑动截取k组不同角度观测图像,分辨率即为224×224×3,随机选取作为后续视觉特征提取模块的输入,从而表示实际智能体运动时不可避免产生的误差,在观测的位置上产生位移噪声和转角噪声,增强进一步泛化到现实场景中的导航能力;
23、步骤三二:采用预训练深度残差网络resnet50进行视觉特征提取;采用在imagenet数据集上预训练获得的resnet50网络参数,截断最后的全局平均池化层,参数在训练过程中固定,减少训练时间;
24、步骤三三:根据孪生神经网络架构,提取损伤目标和智能体第一视角观测的rgb图像特征;当智能体与损伤环境交互时,将损伤目标以及观测图像输入网络,通过预训练resnet50计算出损伤目标和智能体观测图像的特征向量,再输入到后续的孪生网络层;
25、步骤三四:融合注意力机制建立视觉特征提取模块;
26、损伤目标图像和第一视角观测图像通过预训练resnet50后得到高维特征,输入中间的孪生层,所述孪生层由注意力层和两个全连接层组成;在上下层之间共享训练参数,有效减少了待学习的参数量,提高模型训练速度,在得到2048维特征向量后,将损伤目标特征向量与观测特征向量沿通道方向进行拼接,作为后续强化学习网络的输入。
27、进一步地,步骤四设计基于长短期记忆网络的导航记忆模块,具体包括以下步骤:
28、步骤四一:建立损伤驱动的改进a3c模型架构;
29、将视觉特征提取模块提取的目标图像和观测图像融合的高维特征作为状态,基于损伤驱动的改进a3c模型进行异步多线程训练,来更新决策所需要的策略网络和价值网络;智能体通过状态信息进行决策,选择最佳的动作策略,执行动作后获得打分以及实时奖励,并更新智能体第一视角观测图像,从而计算新的视觉特征状态,直至导航结束;a3c模型由一个全局网络和并行线程的局部网络组成;
30、步骤四二:更新损伤驱动的改进a3c模型;
31、每个线程在独立的导航视觉环境中与环境交互,且局部网络的actor网络和critic网络与全局网络相同;每个独立线程中,局部网络中的智能体称为worker,worker从环境中接收状态st,actor网络会根据当前的状态从离散的动作中选择出最合适的动作at,为worker提供在当前环境中探索的动作,同时critic网络会根据worker当前步的状态st和动作at给出相应的打分q值,来评判当前动作的优劣;a3c模型采用在线学习的方式,不依赖于经验池,每个线程独立的与当前环境完成一次交互后,同时更新局部网络和全局网络;
32、步骤四三:设计基于长短期记忆网络的导航记忆储存器;
33、视觉特征提取模型对损伤目标图像和智能体观测图像进行了特征提取与融合,得到一个包含目标信息和当前状态信息的高维特征,输入改进的a3c网络;将过去n个时刻的状态信息高维特征融合成一个状态序列,作为融合特征输入到actor网络,最终得到选择动作的策略;actor网络由一个长矩期记忆层和全连接层组成;n个时刻的状态序列通过1层特定场景层的全连接层后,输入1层注意力层、1层全连接层和softmax激活层,输出智能体所采取的离散动作的概率,并在训练过程中根据最大概率选择出相应的最佳动作。
34、进一步地,所述步骤四二具体为:
35、步骤四二一:共有n个平行线程,每个线程中都有一个worker智能体,在特定的场景导航到特定的损伤目标;
36、步骤四二二:在某一时刻异步更新的线程中,workerm完成了一个批次的训练,形成了一条完整的导航到目标损伤图像处的轨迹,并用这个轨迹来计算actor网络和critic网络的损失值,计算其梯度并更新到全局网络中;
37、步骤四二三:全局网络通过梯度下降计算新的参数,完成了一次全局网络的更新,并将更新的参数传递给workerm;
38、步骤四二四:workerm用更新后的策略选择动作,再次完成新批次的导航任务;
39、步骤四二五:在workerm更新全局网络参数、并更新自身的actor网络和critic网络时,其它线程的worker仍然用旧的策略来完成导航任务直至该批次结束,然后以相同的方式更新参数。
40、进一步地,步骤五中设计后继通用表征模块,具体步骤包括:
41、步骤五一:在每次的参数更新中,actor网络的更新目标是基于状态st、动作at的最优化策略,即在该状态下采取该动作相较于其他动作的优势来调整策略,使得具有优势的动作被选择的概率增大;策略损失函数为:
42、lp=-∑(logπ(a|st)·a(a,st)+β·h(π(a|st)) (2)
43、式中,β为权重系数;h(π(a|st)是策略熵、为策略选择的随机性度量,鼓励智能体在训练中随机抽取动作进行探索,避免停滞于局部最优解;a(a,st)为优势函数,近似计算方法为:
44、a(a,st)≈rt+γ·v(st+1)-v(st) (3)
45、式中,rt为t时刻做出的动作、与环境交互得到的真实奖励值,γ为奖励折扣系数,v(st+1)为下一步动作后新的状态下critic网络评估出的q值;
46、步骤五二:critic网络为actor网络提供动作选择的评判依据,通过最小化网络预测值与真实的奖励之间的误差,不断地更新使得评分更接近于真实值;价值损失函数lv采用l2损失:
47、lv=0.5·∑(rt-v(st))2 (4)
48、式中,rt是智能体与环境交互得到的轨迹计算的累计折扣回报,计算方法为:
49、
50、步骤五三:除了actor网络和critic网络,为增强模型在状态空间中的泛化能力,设计了后继通用表征模块,用于表达在当前策略下、从当前状态转移到下一状态的期望分布;后继通用表征模块的损失函数为:
51、lsr=λ·∑(usrt-usr(st))2 (6)
52、式中,λ是lsr项的权重系数,usr(st)为后继通用表征模块输出的通用后继表征,usrt是智能体与环境交互得到的轨迹计算的累计真值,计算方法为:
53、
54、式中,usr为智能体与环境交互得到的轨迹在每一时间步上的真值;
55、步骤五四:基于后继通用表征的价值网络解耦;
56、将损伤驱动的视觉导航问题看作是导航至不同类型损伤的决策行为策略合集,通过将奖励值解耦成状态特征与目标权重来实现目标变化后的策略迁移,奖励解耦计算方法为:
57、rg(st,at,st+1)≈φ(st,at,st+1)twg≈φ(st+1)twg (8)
58、式中,φ(st,at,st+1)为状态特征,wg为与损伤目标有关的权重向量;
59、进一步将状态价值函数解耦:
60、
61、对critic网络拟合的价值函数,解耦为由损伤目标预测的权重向量网络wg(θ)和状态特征预测的网络;由于目标权重向量与导航行程时序无关,因此在lstm之前输出wg,而状态特征与动作前后两个时刻的状态有关,因此与actor网络相同,其在lstm之后输出,并与wg进行矩阵相乘得到critic网络的输出从而完成基于后继通用表征的价值网络解耦,critic网络结构主体上与actor网络结构相同,对n个时刻的状态特征序列,进行attention层和lstm层的处理后,得到后继通用表征的状态特征损伤目标图像经过所述视觉特征提取网络处理后得到其对应的高维特征,再通过三层全连接层,输出wg,最终与相乘得到最终的状态价值输出。
62、进一步地,步骤六建立融合视觉-深度多模态信息和多辅助任务联合学习的视觉导航模型,通过融合深度信息和辅助任务学习,实现视觉导航增强,具体步骤包括:
63、步骤六一:设计深度信息融合模块;
64、对于智能体与损伤环境交互获取的rgb图像,采用midas模型进行单目深度估计mde,对于得到的深度图像,设计了图像输入层融合、resnet50特征层融合以及通过注意力机制融合多种融合方式,通过融合深度信息使得模型同时理解rgb图像和深度信息多模态信息,更好地获得损伤结构环境的空间特征;
65、通过midas模型计算损伤目标图像与智能体观测图像的深度图,并将原始图像和深度图一并输入到视觉特征提取模块,在resnet50提取特征后,将rgb特征图与深度特征图融合,得到融合深度信息的损伤目标特征图与观测图像特征图,再通过后续的孪生神经网络计算并融合损伤目标与观测图像的特征向量;此时的特征向量同时包含了图像及其深度信息,有助于学习环境空间中的深度信息,进一步映射到后续的策略网络,帮助智能体选择更优的动作,高效、安全地完成建筑内部导航和损伤智能检测任务;
66、步骤六二:扩展损伤驱动视觉导航经验池,设计碰撞预测、奖励预测辅助任务;
67、在模型训练的同时,动态地将导航经验储存在扩展的经验池中,随机抽取经验来进行辅助任务训练,辅助任务与损伤驱动视觉导航任务同时训练,用于增强模型对环境中的碰撞信息、奖励信号的理解;
68、损伤驱动的视觉导航模型是通过在线学习更新的,即在各个线程中智能体与损伤环境交互时进行学习;而辅助任务的训练需要真值信息,依赖于经验回放,在智能体与环境交互过程中记录产生的经验元组,并通过随机采样打破数据之间的相关性;经验元组的表示方法为:
69、
70、式中,智能体从s0状态开始,直至导航到损伤目标处,所用时间步为l,从当前状态st执行动作at,得到下一时刻的状态st+1与奖励at+1;为满足于辅助任务设计,将经验池结构进行扩充,收集包含碰撞信息、目标信息、终止信息经验数据,扩展的经验元组信息为:
71、
72、式中,g为导航经验中的损伤目标,tet为当前时刻的终止信息,表明导航是否终止,ct为当前时刻的碰撞信息,两者的值用0或1表示;在训练过程中,为每一个线程设置一个经验池,经验池的容量为10000条经验,并随着训练进行,经验池会动态更新,新的经验进入经验池中,会挤出最旧的经验,实现动态更新;在辅助任务的训练过程中,会从经验池中随机的抽取经验数据,作为辅助任务的训练和标签;
73、辅助任务经验池在损伤驱动的导航模型每个线程中收集经验,随着经验池的填充,辅助任务开始随机抽样若干个经验元组进行训练,经验元组作为真值信息监督模型训练,随着主任务的训练进行,经验池更新的经验包含了更准确有效的导航信息,进一步促进辅助任务训练;
74、步骤六三:设计了分段训练策略;
75、对于辅助任务网络,在训练初期采用小的碰撞惩罚,便于智能体正向的探索学习;在训练后期增大损失惩罚的权重,从而增强智能体的避障能力。
76、本发明的有益效果为:
77、1、针对传统智能体视觉导航模拟环境缺乏实际土木工程结构损伤信息的瓶颈,提出了融合结构损伤信息的虚拟环境建模方法,构建了损伤结构巡检智能体视觉导航环境;
78、2、所提出的场景融合方法同样适用于智能体与其他工程学科交叉场景构建;
79、3、针对传统导航方法缺乏陌生场景泛化能力的困难,设计了基于a3c的损伤驱动视觉导航模型,引入resnet50和注意力机制提取损伤图像和观测图像的高维特征,实现了端到端的损伤驱动视觉导航,在陌生场景下具有较高的导航成功率;
80、4、针对传统导航方法缺乏长期记忆能力的困难,设计了基于长短期记忆网络的导航记忆模块和基于后继通用表征的值网络解耦模块,缩短了平均导航距离;
81、5、针对损伤驱动导航模型的多模态信息融合问题,引入了midas模块进行rgb图像的深度估计,并采用不同的深度信息融合方法增强了导航模型性能;
82、6、针对损伤驱动导航模型的多辅助任务融合问题,设计了融合碰撞预测、奖励预测的辅助任务的多任务训练方法,有效提高了导航模型性能,缩短了平均导航距离。
- 还没有人留言评论。精彩留言会获得点赞!