数据处理方法、装置、电子设备、介质及产品与流程
本公开涉及大数据,可应用于金融科技,特别涉及一种数据处理方法、装置、电子设备、介质及产品。
背景技术:
1、对于商业银行来说,高资产个人客群是最优质的资源之一,其投资、消费和信贷活动为商业银行带来巨大的中间业务收入和利润。随着银行间竞争的日趋白热化,大量优质个人客户选择不把资产放在某一家银行。由于信息不对称,这些客户的潜在价值往往难以被发现,导致商业银行的营销活动缺失了很多“靶点”,造成一段时间内收益增速难以提升。而如何从本行中与客户关联的数据中精确地提取有价值的信息是准确挖掘潜在客户的关键。
2、在实现本公开的过程中,申请人发现:现有的数据处理方法从本行中与客户关联的数据中提取有价值的信息的精度偏低,并且,需要耗费大量的计算资源,增加了算力成本。
技术实现思路
1、有鉴于此,本公开的主要目的是提供一种数据处理方法、装置、电子设备、介质及产品,旨在至少部分解决现有数据处理方法提取数据精度低,耗费资源高的技术问题。
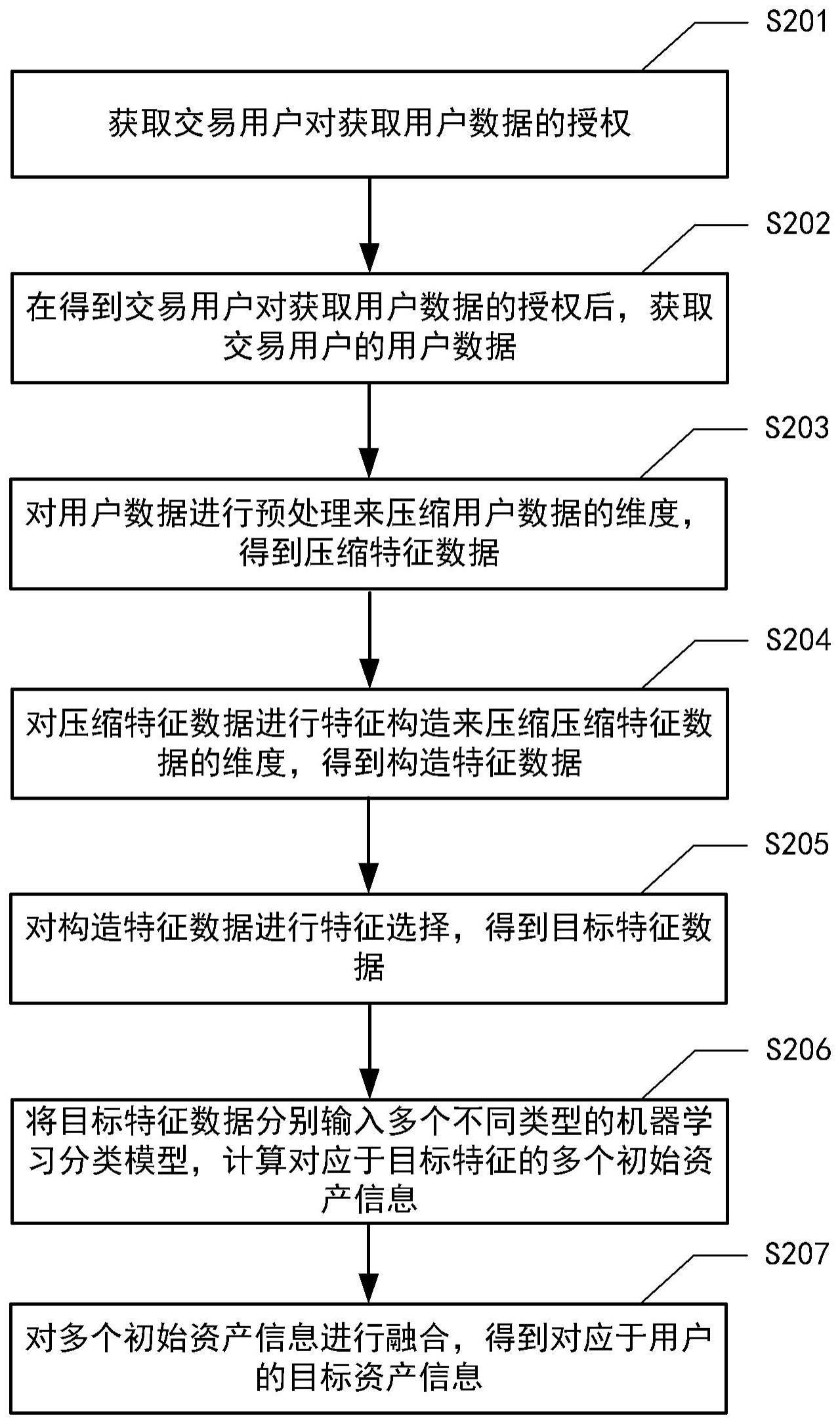
2、为实现上述目的,本公开实施例第一方面提供一种数据处理方法,包括:获取用户对获取用户数据的授权;在得到用户对获取用户数据的授权后,获取用户的用户数据;对所述用户数据进行预处理来压缩所述用户数据的维度,得到压缩特征数据;对所述压缩特征数据进行特征构造来压缩所述压缩特征数据的维度,得到构造特征数据;对所述构造特征数据进行特征选择,得到目标特征数据,其中,所述目标特征数据的重要程度值大于第一预设阈值;将所述目标特征数据分别输入多个不同类型的机器学习分类模型,计算对应于所述目标特征的多个初始资产信息;对所述多个初始资产信息进行融合,得到对应于所述用户的目标资产信息。
3、根据本公开的实施例,所述获取用户的用户数据包括:从所述用户中确定目标用户;获取所述目标用户的所述用户数据。
4、根据本公开的实施例,所述从所述用户中确定目标用户包括:对于每一用户,获取该用户的消费数据、资产数据和缴费数据;根据所述消费数据、所述资产数据和所述缴费数据构建对应于该用户的目标函数;响应于对应于该用户的目标函数满足第一预设条件,将该用户确定为所述目标用户。
5、根据本公开的实施例,所述对所述用户数据进行预处理来压缩所述用户数据的维度包括:对所述用户数据执行第一操作,得到第一特征数据;对所述第一特征数据进行预测来补充所述第一特征数据中的缺失数据,得到第二特征数据;分析所述第二特征数据中每一维度数据的统计信息和分布信息,确定第三特征数据,其中,所述第三特征数据包括异常值大于第二预设阈值的第二特征数据;对所述第三特征数据进行转化,得到第四特征数据,其中,所述第四特征数据包括异常值不大于第二预设阈值的第二特征数据和转化后的第三特征数据;对所述第四特征数据进行标准化来压缩所述第四特征数据的特征值空间,得到所述压缩特征数据。
6、根据本公开的实施例,所述对所述用户数据执行第一操作包括以下操作的至少之一:对所述用户数据中的非数值型数据进行量化;删除不能量化的非数值型数据;将所述用户数据中的分类型数据和/或枚举型数据编码成整型数据;将所述用户数据中的连续性型数据转化为离散型数据。
7、根据本公开的实施例,所述将所述用户数据中的分类型数据和/或枚举型数据编码成整型数据包括:采用一位有效编码将所述分类型数据和/或枚举型数据编码成所述整型数据。
8、根据本公开的实施例,所述将所述用户数据中的连续性型数据转化为离散型数据包括:采用决策树分箱方法将所述连续性型数据转化为所述离散型数据。
9、根据本公开的实施例,对所述第一特征数据进行预测来补充所述第一特征数据中的缺失数据,得到第二特征数据包括:基于机器学习预测模型拟合对应于所述缺失数据所在维度中有值的数据部分和非缺失数据所在维度的所述第一特征数据,得到待填充数据;采用待填充数据补充所述缺失数据,得到所述第二特征数据。
10、根据本公开的实施例,所述分析所述第二特征数据中每一维度数据的统计信息和分布信息包括:采用数据包络分析方法分析所述第二特征数据中每一维度数据的统计信息和分布信息。
11、根据本公开的实施例,所述对所述压缩特征数据进行特征构造来压缩所述压缩特征数据的维度,得到构造特征数据包括:对所述压缩特征数据中具有时空特性的明细数据进行统计和归纳,得到所述构造特征数据。
12、根据本公开的实施例,所述对所述构造特征数据进行特征选择,得到目标特征数据包括:随机置换所述构造特征数据中至少一个维度的子构造特征数据;将置换后的所述构造特征数据输入集成决策树模型,得到对应于集成决策树模型的f1分数和/或接收者操作特征曲线下面积;响应于所述f1分数和/或所述接收者操作特征曲线下面积满足第二预设条件,将所述至少一个维度的子构造特征数据确定为所述目标特征数据。
13、根据本公开的实施例,所述方法还包括:根据所述用户数据和所述目标资产信息生成推荐信息,其中,所述推荐信息包括所述用户的偏好信息和所述用户处理所述偏好信息的位置信息。
14、根据本公开的实施例,所述用户数据包括以下数据中的至少之一:基础数据、资产数据、金融产品持有数据、消费数据、缴费数据以及与所述基础数据、资产数据、金融产品持有数据、消费数据、缴费数据中的至少之一关联的互联网公开数据。
15、根据本公开的实施例,所述机器学习分类模型至少包括:随机森林模型、逻辑回归模型、xgboost模型、lightgbm模型中的至少之一。
16、本公开实施例的第二方面提供一种数据处理装置,包括:授权模块,用于获取用户对获取用户数据的授权;获取模块,用于在得到用户对获取用户数据的授权后,获取用户的用户数据;预处理模块,用于对所述用户数据进行预处理来压缩所述用户数据的维度,得到压缩特征数据;特征构造模块,用于对所述压缩特征数据进行特征构造来压缩所述压缩特征数据的维度,得到构造特征数据;特征选择模块,用于对所述构造特征数据进行特征选择,得到目标特征数据,其中,所述目标特征数据的重要程度值大于第一预设阈值;计算模块,用于将所述目标特征数据分别输入多个不同类型的机器学习分类模型,计算对应于所述目标特征的多个初始资产信息;融合模块,用于对所述多个初始资产信息进行融合,得到对应于所述用户的目标资产信息。
17、本公开实施例第三方面提供一种电子设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器执行根据上述数据处理方法。
18、本公开实施例第四方面提供一种计算机可读存储介质,所述计算机可读存储介质上存储有可执行指令,该指令被处理器执行时使处理器执行根据上述数据处理方法。
19、本公开实施例第五方面提供一种计算机程序产品,包括计算机程序,所述计算机程序被处理器执行时实现根据上述数据处理方法。
20、根据本公开实施例提供的数据处理方法、装置、电子设备、介质及产品,至少具备以下有益效果:
21、通过对用户数据进行预处理,在不改变原始数据分布的前提下,压缩用户数据的维度,一方面,减少数据的计算量,从而提高了数据处理的效率,降低了算力成本,另一方面,增加了后续机器学习分类模型计算的稳定性,提高了计算得到的数据的精度。
22、通过对压缩特征数据进行特征构造,能够进一步降低数据的维度,减少数据的计算量,从而提高了数据处理的效率,降低了算力成本。
23、通过对构造特征数据进行特征选择,以获取重要的构造特征数据作为目标特征数据,从而能够提高了生成的目标资产信息的精度,进而有利于准确地挖掘潜在的用户。
24、通过多个不同类型的机器学习分类模型融合目标资产信息,避免了单一模型计算产生的“偏见”,提高了生成的目标资产信息的精度,进而有利于准确地挖掘潜在的用户。
- 还没有人留言评论。精彩留言会获得点赞!