对话回复生成方法、装置、电子设备和存储介质与流程
本公开涉及人机对话,尤其涉及一种对话回复生成方法、对话回复生成装置、电子设备和存储介质。
背景技术:
1、目前,在人机对话中,主要通过两种方式生成对话回复数据。一种方式是基于答案库和规则生成。这种方式可以保证回复的一致性,但千篇一律,无法安抚用户的情绪。另一种方式是采用大批量数据训练得到对话回复模型。这种方式能够提高回复的多样性,但在情绪方面同样不能给到及时的安抚。
技术实现思路
1、本公开提供了一种对话回复生成技术方案。
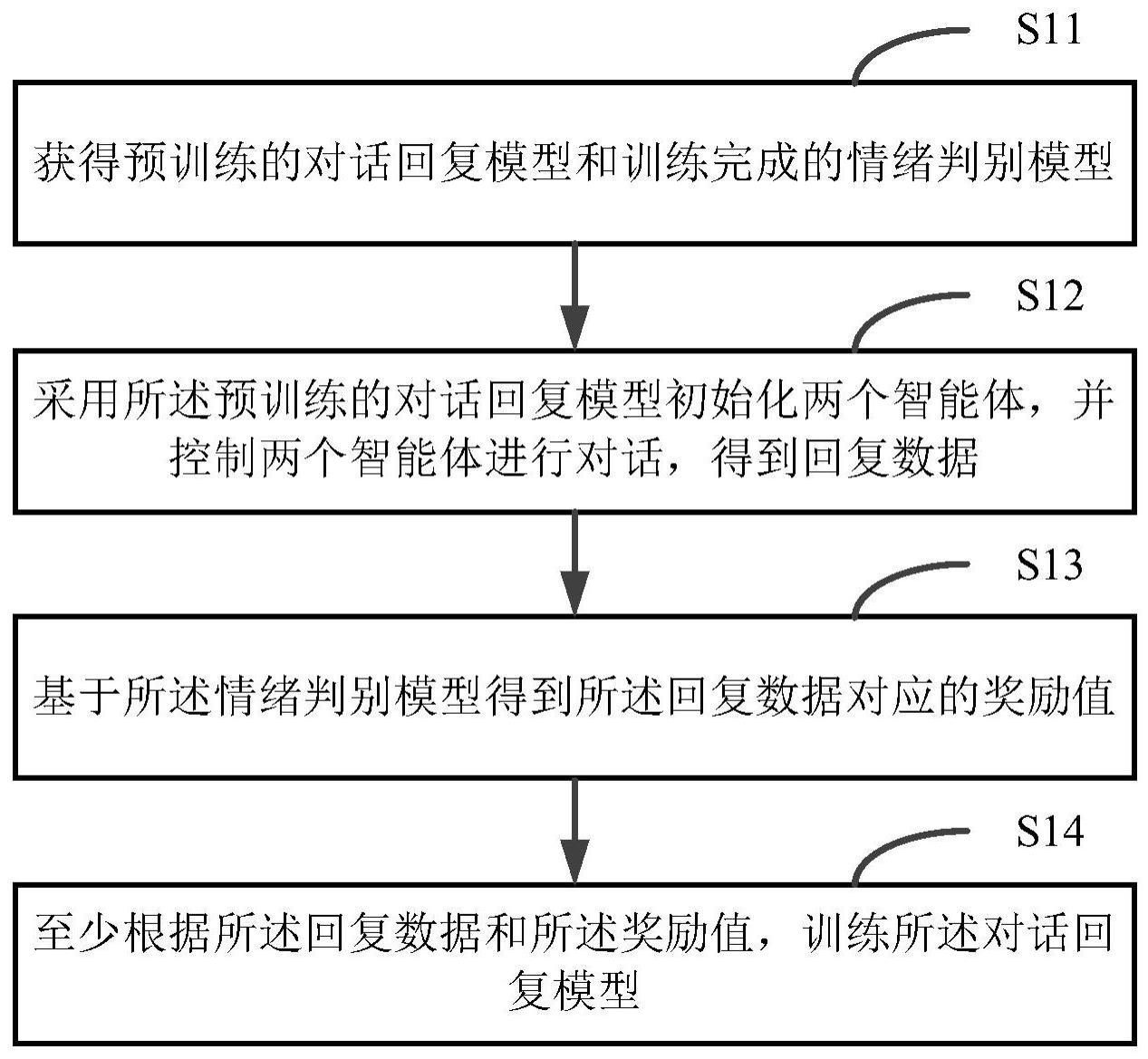
2、根据本公开的一方面,提供了一种对话回复模型的训练方法,包括:
3、获得预训练的对话回复模型和训练完成的情绪判别模型;
4、采用所述预训练的对话回复模型初始化两个智能体,并控制两个智能体进行对话,得到回复数据;
5、基于所述情绪判别模型得到所述回复数据对应的奖励值;
6、至少根据所述回复数据和所述奖励值,更新所述对话回复模型的参数。
7、在一种可能的实现方式中,所述基于所述情绪判别模型得到所述回复数据对应的奖励值,包括:
8、将所述回复数据输入所述情绪判别模型,经由所述情绪判别模型输出所述回复数据属于多个预设情绪类别的概率;
9、根据所述回复数据属于多个预设情绪类别的概率,确定所述回复数据对应的奖励值。
10、在一种可能的实现方式中,所述根据所述回复数据属于多个预设情绪类别的概率,确定所述回复数据对应的奖励值,包括:
11、根据所述回复数据属于多个预设情绪类别中的至少一个指定情绪类别的概率,确定所述回复数据对应的奖励值。
12、在一种可能的实现方式中,所述至少根据所述回复数据和所述奖励值,更新所述对话回复模型的参数,包括:
13、获取所述回复数据的上文;
14、根据所述回复数据、所述回复数据的上文和所述奖励值,更新所述对话回复模型的参数。
15、在一种可能的实现方式中,所述获得预训练的对话回复模型,包括:
16、采用第一对话样本集训练所述对话回复模型,得到预训练的对话回复模型,其中,所述第一对话样本集包括多个第一对话样本,所述多个第一对话样本中的任一第一对话样本包括对话上文和真实对话下文。
17、在一种可能的实现方式中,所述采用第一对话样本集训练所述对话回复模型,包括:
18、对于第一对话样本集的任一第一对话样本,将所述第一对话样本的对话上文输入所述对话回复模型,经由所述对话回复模型得到预测对话下文;
19、根据所述预测对话下文与所述真实对话下文之间的差异信息,训练所述对话回复模型。
20、在一种可能的实现方式中,获得训练完成的情绪判别模型,包括:
21、采用第二对话样本集训练所述情绪判别模型,得到训练完成的情绪判别模型,其中,所述第二对话样本集包括多个第二对话样本,所述多个第二对话样本中的任一第二对话样本包括单个语句以及情绪标签。
22、在一种可能的实现方式中,所述采用第二对话样本集训练所述情绪判别模型,包括:
23、对于所述第二对话样本集中的任一第二对话样本,将所述第二对话样本输入所述情绪判别模型,经由所述情绪判别模型输出所述第二对话样本属于多个预设情绪类别的概率;
24、根据所述第二对话样本属于多个预设情绪类别的概率,以及所述第二对话样本对应的情绪标签,训练所述情绪判别模型。
25、在一种可能的实现方式中,所述对话回复模型采用transformer结构。
26、在一种可能的实现方式中,所述至少根据所述回复数据和所述奖励值,更新所述对话回复模型的参数,包括:
27、至少根据所述回复数据和所述奖励值,基于策略梯度方法更新所述对话回复模型的参数。
28、根据本公开的一方面,提供了一种对话回复生成方法,所述方法包括:
29、获取由对话回复模型的训练方法训练完成的对话回复模型;
30、将待回复的对话数据输入所述对话回复模型,经由所述对话回复模型得到所述待回复的对话数据对应的回复数据。
31、根据本公开的一方面,提供了一种对话回复模型的训练装置,包括:
32、第一获得模块,用于获得预训练的对话回复模型和训练完成的情绪判别模型;
33、控制模块,用于采用所述预训练的对话回复模型初始化两个智能体,并控制两个智能体进行对话,得到回复数据;
34、第二获得模块,用于基于所述情绪判别模型得到所述回复数据对应的奖励值;
35、训练模块,用于至少根据所述回复数据和所述奖励值,更新所述对话回复模型的参数。
36、在一种可能的实现方式中,所述第二获得模块用于:
37、将所述回复数据输入所述情绪判别模型,经由所述情绪判别模型输出所述回复数据属于多个预设情绪类别的概率;
38、根据所述回复数据属于多个预设情绪类别的概率,确定所述回复数据对应的奖励值。
39、在一种可能的实现方式中,所述第二获得模块用于:
40、根据所述回复数据属于多个预设情绪类别中的至少一个指定情绪类别的概率,确定所述回复数据对应的奖励值。
41、在一种可能的实现方式中,所述训练模块用于:
42、获取所述回复数据的上文;
43、根据所述回复数据、所述回复数据的上文和所述奖励值,更新所述对话回复模型的参数。
44、在一种可能的实现方式中,所述第一获得模块用于:
45、采用第一对话样本集训练所述对话回复模型,得到预训练的对话回复模型,其中,所述第一对话样本集包括多个第一对话样本,所述多个第一对话样本中的任一第一对话样本包括对话上文和真实对话下文。
46、在一种可能的实现方式中,所述第一获得模块用于:
47、对于第一对话样本集的任一第一对话样本,将所述第一对话样本的对话上文输入所述对话回复模型,经由所述对话回复模型得到预测对话下文;
48、根据所述预测对话下文与所述真实对话下文之间的差异信息,训练所述对话回复模型。
49、在一种可能的实现方式中,所述第一获得模块用于:
50、采用第二对话样本集训练所述情绪判别模型,得到训练完成的情绪判别模型,其中,所述第二对话样本集包括多个第二对话样本,所述多个第二对话样本中的任一第二对话样本包括单个语句以及情绪标签。
51、在一种可能的实现方式中,所述第一获得模块用于:
52、对于所述第二对话样本集中的任一第二对话样本,将所述第二对话样本输入所述情绪判别模型,经由所述情绪判别模型输出所述第二对话样本属于多个预设情绪类别的概率;
53、根据所述第二对话样本属于多个预设情绪类别的概率,以及所述第二对话样本对应的情绪标签,训练所述情绪判别模型。
54、在一种可能的实现方式中,所述对话回复模型采用transformer结构。
55、在一种可能的实现方式中,所述训练模块用于:
56、至少根据所述回复数据和所述奖励值,基于策略梯度装置更新所述对话回复模型的参数。
57、根据本公开的一方面,提供了一种对话回复生成装置,包括:
58、获取模块,用于获取由对话回复模型的训练装置训练完成的对话回复模型;
59、生成模块,用于将待回复的对话数据输入所述对话回复模型,经由所述对话回复模型得到所述待回复的对话数据对应的回复数据。
60、根据本公开的一方面,提供了一种电子设备,包括:一个或多个处理器;用于存储可执行指令的存储器;其中,所述一个或多个处理器被配置为调用所述存储器存储的可执行指令,以执行上述方法。
61、根据本公开的一方面,提供了一种计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现上述方法。
62、根据本公开的一方面,提供了一种计算机程序产品,包括计算机可读代码,或者承载有计算机可读代码的非易失性计算机可读存储介质,当所述计算机可读代码在电子设备中运行时,所述电子设备中的处理器执行上述方法。
63、在本公开实施例中,通过获得预训练的对话回复模型和训练完成的情绪判别模型,采用所述预训练的对话回复模型初始化两个智能体,并控制两个智能体进行对话,得到回复数据,基于所述情绪判别模型得到所述回复数据对应的奖励值,并至少根据所述回复数据和所述奖励值,更新所述对话回复模型的参数,由此采用强化学习的方式,基于情绪判别模型训练对话回复模型,使对话回复模型学习到生成情绪合适的回复数据的能力,从而有助于减少人工干预。
64、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,而非限制本公开。
65、根据下面参考附图对示例性实施例的详细说明,本公开的其它特征及方面将变得清楚。
- 还没有人留言评论。精彩留言会获得点赞!