一种面向边缘服务器的长尾数据保护方法
本发明属于边缘计算数据存储,具体涉及一种面向边缘服务器的长尾数据保护方法。
背景技术:
1、边缘计算是一种新型的计算模式,它将计算和存储资源部署在网络边缘,靠近数据的产生和消费地,以提供低延迟、高带宽、环境感知等服务功能,车联网、智慧城市、工业物联网等应用场景中常常使用边缘计算技术。边缘计算通过就近提供计算资源和存储资源,使计算和服务更接近用户,降低了用户时延,给用户带来了更好的使用体验;但比起云计算,移动边缘计算的环境更加复杂且不稳定,软件错误、硬件缺陷、恶意攻击等事件都可能导致缓存在边缘服务器上的数据副本发生损坏。
2、文献[ateniese,giuseppe,et al."provable data possession at untrustedstores."proceedings of the 14th acm conference on computer and communicationssecurity.2007.],[juels,ari,and burton s.kaliski jr."pors:proofs ofretrievability for large files."proceedings of the 14th acm conference oncomputer and communications security.2007]分别提出了两种云计算中使用的数据完整性保护方案,可证明数据占有(pdp)和可检索性证明(por)。pdp的核心思想是在上传数据之前,对数据进行预处理,生成元数据,并将它们与数据一起发送给云端;然后,用户可以向云端发出请求,要求它提供与某些数据分片对应的元数据,用户通过验证云端返回的元数据是否与用户本地存储的一致,就可以判断云端是否真正存储了完整的数据副本。por则是在上传数据前,对数据进行编码,生成冗余信息,用户同样可以要求云端返回某些数据分片及冗余信息,以此判断云端存储的数据是否完整。但以上两个方案都不适合边缘计算的场景,首先在边缘计算场景下不存在云计算中云端这一中心化的结构;其次pdp和por技术在数据预处理和数据验证时需要消耗大量的时间;最后,大多数的边缘服务器的计算能力较弱,存储资源有限,而这两个方案都需要进行大量的计算并存储数据。
3、文献[li,bo,et al."cooperative assurance of cache data integrity formobile edge computing."ieee transactions on information forensics andsecurity 16(2021):4648-4662]提出了cooperedi方案,在此方案中大量的边缘服务器构建一个自我管理的数据系统,在该系统中边缘服务器相互协作保护数据完整性;边缘服务器通过广播自身存储数据的摘要,利用一致性共识算法,使得与其他个边缘服务器存储数据相同的服务器成为管理服务器,再由其对其余边缘服务器进行数据检查和修复。但此方案也存在一些缺陷:如果整个系统中n个数据d的副本分别存储在n个边缘服务器上,那么在选择管理服务器的过程中,必须有至少个边缘服务器参与,否则无法找到一个管理服务器也就就无法进行后续的数据检查和修复;其次,每个边缘服务器都需要存储数据d的完整备份,需要消耗大量的存储空间;最后,为了能找到存有正确数据的边缘服务器,coopedi使用了一致性共识算法,该算法流程复杂且需要o(n2)轮通讯,时间和流量消耗过大。
4、考虑到在现实世界应用场景中,边缘数据常常呈现长尾分布的特点,即只有少部分数据被频繁访问,而其余数据的访问频率极低。以youtube的视频浏览量为例,在该视频网站上只有0.64%的视频浏览量超过10万次,大多数youtube视频(88.4%)的浏览量低于1000次。因此,我们需要设计一个针对边缘长尾数据能实现数据完整性保护的方案。
技术实现思路
1、鉴于上述,本发明提供了一种面向边缘服务器的长尾数据保护方法,其针对边缘计算中边缘服务器缓存数据容易损坏的问题以及边缘计算长尾数据的特点,通过边缘服务器间的协作实现数据完整性的检验和数据修复,实现了边缘长尾数据的完整性保护。
2、一种面向边缘服务器的长尾数据保护方法,包括如下步骤:
3、(1)完成边缘服务网络系统的参数设置以及长尾数据的数据拆分工作;
4、(2)对系统中存有长尾数据副本的边缘服务器进行数据完整性验证;
5、(3)对于存在数据损坏的边缘服务器,其通过与管理服务器交互得到损坏数据块的索引以及数量;
6、(4)对于存在数据损坏的边缘服务器,其根据损坏数据块的索引以及数量与管理服务器或存储有数据分片的边缘服务器交互,完成数据修复。
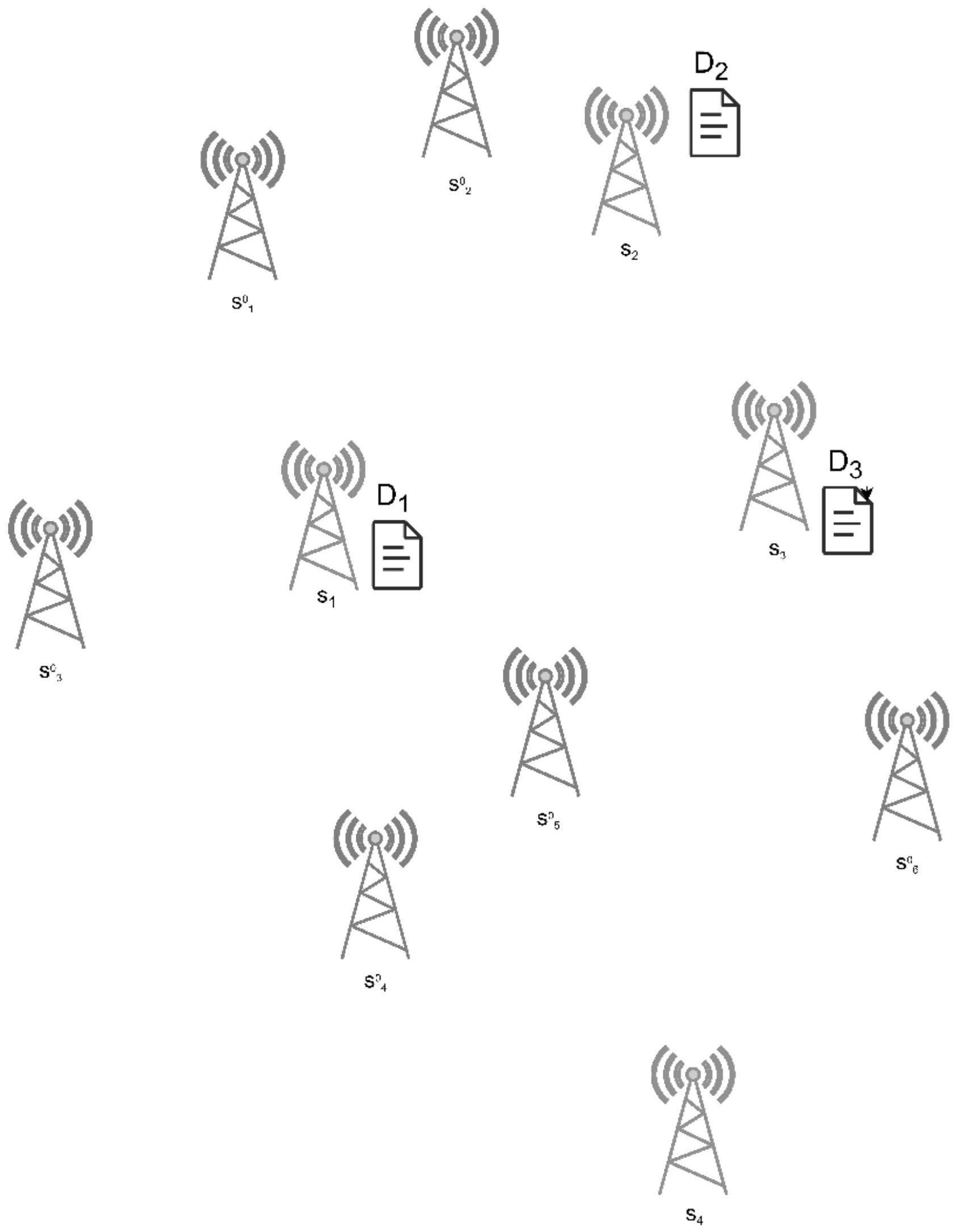
7、进一步地,所述边缘服务网络系统包含有需要进行存储的长尾数据以及一系列边缘服务器,这些边缘服务器分为两类集群s和k,集群s中的边缘服务器存储有长尾数据副本,集群k中的边缘服务器则用于存储长尾数据经过reed solomon算法处理后的数据分片。
8、进一步地,所述步骤(1)中的系统参数设置包括设置时间阈值t、选择具体的哈希算法、设置reed solomon算法的参数m和n、设置损坏块数阈值k,其中时间阈值t与边缘服务器进行数据完整性校验的频率有关,t值越小则校验越频繁;选择包括sha-1、sha-2、sha-256在内的哈希算法用于数据完整性校验中数据哈希的生成以及数据损坏定位中数据块哈希的生成;reed solomon算法需保证任意选取m个经处理后的数据分片都能恢复原始长尾数据,n决定了reed solomon算法的容错能力,即冗余数据分片的数量;损坏块数阈值k决定了出现数据损坏后以何种方式进行数据修复,若实际损坏数小于阈值k,出现数据损坏的边缘服务器与管理服务器交互进行数据修复;若实际损坏块数超出阈值k,出现数据损坏的边缘服务器则与集群k中的边缘服务器交互进行数据修复。
9、进一步地,所述步骤(1)中的数据拆分工作为:首先从集群s中任意选择一个边缘服务器s,其使用reed solomon算法将本地存储的长尾数据副本d分成m+n个数据分片d1,d2,…,dm+n,并计算出长尾数据副本d及其数据分片的哈希;然后边缘服务器s从集群k中随机选择m+n个边缘服务器来分别存储数据分片d1,d2,…,dm+n,具体地s先向这m+n个边缘服务器发送对应的数据存储请求,该请求包含有长尾数据副本d的哈希h以及对应的数据分片,收到请求的边缘服务器会存储对应的数据分片,完成存储后向s发送存储成功响应,当s收到m+n个响应后,即认为数据拆分完成,s会将存储数据分片的边缘服务器名单发送给集群s中的其他服务器。
10、进一步地,所述步骤(2)的具体实现过程为:对于集群s中的任一边缘服务器si,其通过与集群k中的边缘服务器交互来验证自身存储的长尾数据副本是否完整,具体地:边缘服务器si先计算本地存储的长尾数据副本di的哈希hi,进而向所有存储数据分片的边缘服务器发送数据完整性校验请求,该请求中包含了哈希hi,收到请求的边缘服务器会将哈希hi与数据拆分时收到的哈希h进行比较,如果两者相同,则认为si存储的长尾数据副本di完整并向si发送数据完整的响应,否则认为si存储的长尾数据副本di存在损坏,si会设置一个初始值为0的计数器,每当收到一个数据完整的响应后,该计数器加1,当计数器的值达到时,则判定si存储的长尾数据副本di完整且si会成为管理服务器,否则判定si存在数据损坏。
11、进一步地,当si成为管理服务器后,其会向集群s的其他边缘服务器发送通知,告知对方自己已成为管理服务器,该通知中携带有哈希hi(其已被验证为正确),收到通知的边缘服务器会停止与集群k的边缘服务器交互,进而通过与哈希hi进行比对来验证本地存储的长尾数据副本是否完整。以上操作能够减少剩余服务器完成数据完整性验证的通讯开销和时间开销。
12、进一步地,所述步骤(3)的具体实现过程为:对于存在数据损坏的边缘服务器sj,其本地存储的长尾数据副本dj由m个数据块组成,sj会计算这些数据块对应的哈希然后随机选择一个管理服务器st,向其发送损坏数据定位请求,该请求中包含有哈希收到请求后,st同样会计算本地长尾数据副本所有数据块的哈希,进而通过与哈希逐个进行比对,从而记录下损坏数据块的索引以及数量并发送给sj。
13、进一步地,所述步骤(4)的具体实现过程为:边缘服务器sj会先判断损坏数据块的数量,若小于等于阈值k,则随机选择一个管理服务器st向其发送数据修复请求,该请求包含有损坏数据块的索引以及数量;收到请求后,st会根据索引将正确的数据块传输给sj,sj利用正确的数据块对损坏数据块进行替换,从而完成数据修复;
14、若损坏数据块的数量大于阈值k,sj会向所有存储数据分片的边缘服务器发送数据修复请求,收到请求的边缘服务器会将各自存储的数据分片发送给sj,sj收集到所有数据分片后采用reed solomon算法恢复得到长尾数据。
15、使用reed solomon算法恢复数据需要消耗一定时间,所以损坏数据块数量较少时选择通过管理服务器直接传输正确的数据块恢复数据,损坏数据块较多时,通过管理服务器恢复数据需要传输大量的数据块,因而选择使用服务器存储的数据分片和reed solomon算法恢复数据。
16、本发明使用了reed solomon算法分散存储数据,节省了数据备份的开销,充分利用了边缘服务器碎片化的存储空间;针对长尾数据特性,在数据完整性验证中,本发明设计了管理服务器广播正确数据哈希的机制,减少了数据验证的时间消耗;本发明还设计了根据损坏数据分片数量采用不同修复数据的策略,减少了数据修复的时间消耗和通讯开销。
- 还没有人留言评论。精彩留言会获得点赞!