一种基于信息增强的提示学习事件抽取方法及装置
本发明涉及事件抽取领域,尤其涉及一种基于信息增强的提示学习事件抽取方法及装置。
背景技术:
1、随着大数据、云计算、物联网等技术的不断进步,互联网上的数据呈爆发式增长,面对海量的数据,如何从中非结构化的信息中提取出有价值的结构化信息是数据挖掘领域的核心问题。
2、事件抽取旨在从文本中识别和提取出特定类型的事件。事件是指某件具体事情的发生,描述事件的信息包括:事件发生的时间和地点、事件的内容和状态、事件的一个或多个参与者等。一个结构化的事件由事件触发词、事件类型、论元、事件论元角色等信息组成。
3、然而,目前大多数相关研究都忽略了句子中先验知识在事件抽取中的利用,并未意识到句子与触发词之间、句子与论元之间、事件与事件之间的语义关系,导致了事件抽取结果的准确率较低,且在少资源情况下事件抽取的性能和鲁棒性较差。
技术实现思路
1、本发明为克服上述现有技术的缺陷,提供一种基于信息增强的提示学习事件抽取方法及装置,能够提高事件类型识别的准确率,避免分层抽取造成的累计错误,实现低资源下的事件抽取。
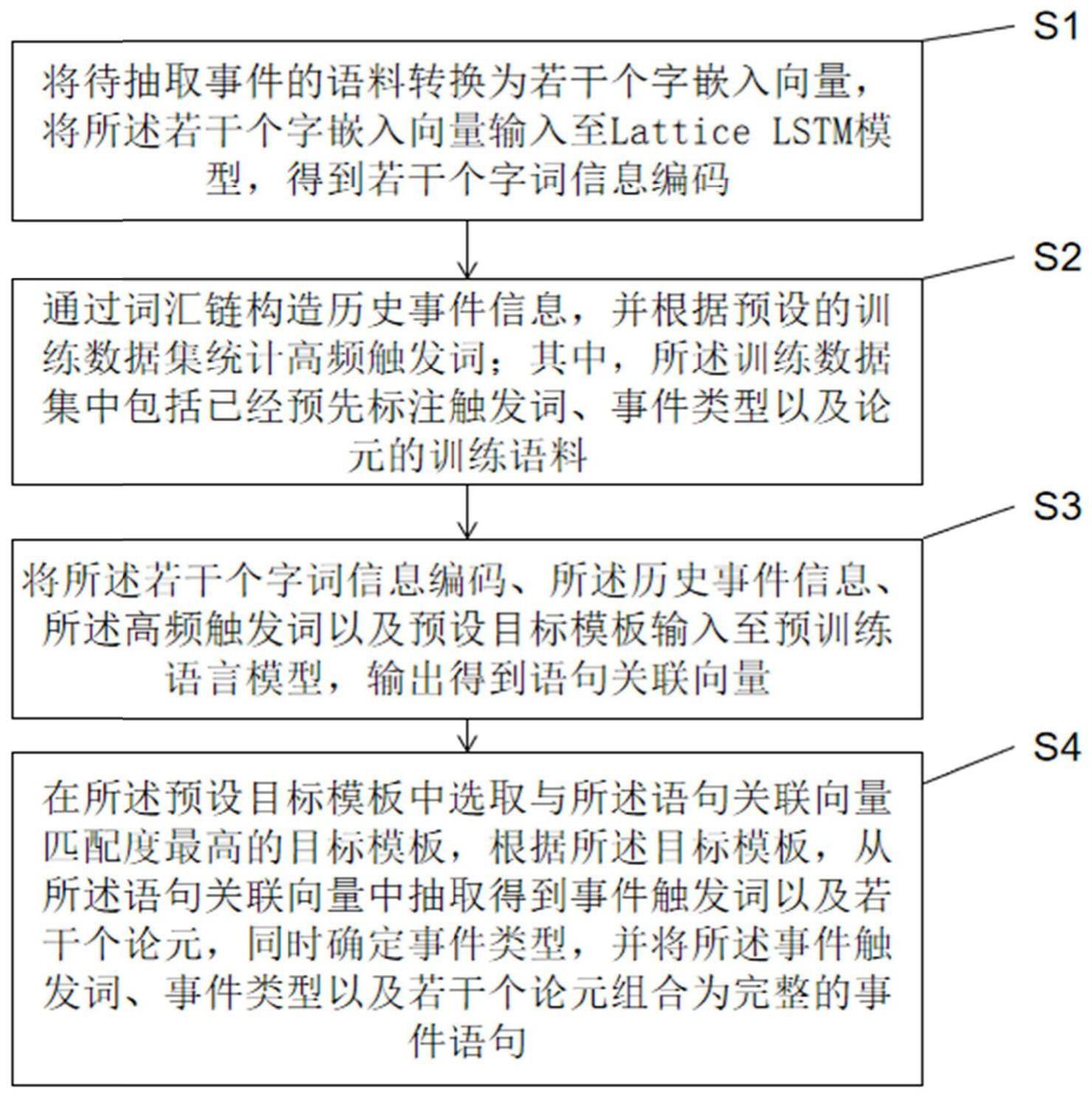
2、本发明一实施例提供一种基于信息增强的提示学习事件抽取方法,包括以下步骤:
3、将待抽取事件的语料转换为若干个字嵌入向量,将所述若干个字嵌入向量输入至lattice lstm模型,得到若干个字词信息编码;
4、通过词汇链构造历史事件信息,并根据预设的训练数据集统计高频触发词;其中,所述训练数据集中包括已经预先标注触发词、事件类型以及论元的训练语料;
5、将所述若干个字词信息编码、所述历史事件信息、所述高频触发词以及预设目标模板输入至预训练语言模型,输出得到语句关联向量;
6、在所述预设目标模板中选取与所述语句关联向量匹配度最高的目标模板,根据所述目标模板,从所述语句关联向量中抽取得到事件触发词以及若干个论元,同时确定事件类型,并将所述事件触发词、事件类型以及若干个论元组合为完整的事件语句。
7、进一步的,所述将待抽取事件的语料转换为若干个字嵌入向量,将所述若干个字嵌入向量输入至lattice lstm模型,得到若干个字词信息编码,具体包括:
8、所述lattice lstm模型包括若干个lattice结构以及主干lstm结构;
9、将所述语料作为输入序列输入至word2vec模型,得到若干个字嵌入向量;其中,一个字嵌入向量对应一个字符;
10、将对应的所述若干个字嵌入向量分别输入至所述主干lstm结构中,对应得到若干个第一输出向量;
11、根据所述语料,在预设字词库中检索所述语料中的若干个潜在词,并将检索到的潜在词对应的词嵌入向量一一输入至所述lattice结构中,分别对应得到若干个第二输出向量;其中,所述潜在词由所述语料中的若干个连续字符组成;
12、根据所述潜在词,将所述潜在词的尾字对应的第一输出向量与该潜在词对应的第二输出向量进行归一计算,得到若干个第三输出向量;其中,一个所述第三输出向量对应一个所述潜在词的尾字;
13、当所述语料中的字符不为所述潜在词的尾字时,将该字符对应的所述第一输出向量输入至所述主干lstm结构的输出门,得到对应的所述字词信息编码;
14、当所述语料中的字符为所述潜在词的尾字时,将该字符对应的所述第三输出向量输入至所述主干lstm结构的输出门,得到对应的所述字词信息编码。
15、进一步的,所述通过词汇链构造历史事件信息,具体包括:
16、根据语料中已经抽取得到的事件类型,依次将所述已经抽取得到的事件类型与已有的词汇链作词汇相似度计算,分别对应得到若干个相似度数值;
17、当所述相似度数值大于预设相似阈值时,则将对应的所述已经抽取得到的事件类型加入已有的词汇链;
18、当所述相似度数值小于预设相似阈值时,将对应的所述已经抽取得到的时间类型设为一条新增词汇链,并将所述新增词汇链加入到所述已有的词汇链中,继续与所述已经抽取得到的事件类型进行词汇相似度计算;
19、将所有所述已有的词汇链组合为历史事件信息。
20、进一步的,所述根据预设的训练数据集统计高频触发词,具体包括:
21、根据预设的训练数据集,在所述训练语料中分别统计各个词语出现的频率,得到对应的若干个第一触发频率;
22、在所述训练数据集的所有事件类型中选取一个作为特定事件类型,在所述训练语料中分别统计各个词语作为所述特定事件类型的事件触发词的频率,得到对应的若干个第二触发频率;
23、分别令所有所述第二触发频率除以对应的所述第一触发频率,对应得到若干个选择概率;
24、当触发词的所述选择概率大于预设概率阈值时,确定为所述特定事件类型的高频触发词;
25、依次选取所述训练数据集中的各事件类型作为所述特定事件类型,统计所有事件类型的高频触发词。
26、进一步的,所述将所述若干个字词信息编码、所述历史事件信息、所述高频触发词以及预设目标模板输入至预训练语言模型,输出得到语句关联向量,具体包括:
27、所述预训练语言模型为bart模型,包括encoder层以及decoder层;
28、将所述若干个字词信息编码、所述历史事件信息、所述高频触发词以及所述预设目标模板输入至所述encoder层;
29、在所述encoder层中,通过自注意力机制处理所述若干个字词信息编码、所述历史事件信息以及所述高频触发词,得到语句关联向量,并把所述语句关联向量发送至所述decoder层。
30、进一步的,所述所述在所述预设目标模板中选取与所述语句关联向量匹配度最高的目标模板,根据所述目标模板,从所述语句关联向量中抽取得到事件触发词以及若干个论元,并确定事件类型,最后将所述事件触发词、事件类型以及若干个论元组合为完整的事件语句,具体包括:
31、所述预设目标模板为预定义的输出格式,一个所述预设目标模板对应一个事件类型;其中,所述预设目标模板中包括若干个占位符,所述占位符的类别包括事件触发词占位符以及论元占位符,一个所述事件触发词占位符对应一个事件触发词,一个所述论元占位符对应一个论元;
32、将所有的所述预设目标模板输入至所述预训练语言模型的decoder层,并依次与所述语句关联向量进行匹配,选取所述预设目标模板中与所述语句关联向量匹配度最高的目标模板作为事件语句模板;
33、根据所述事件语句模板,执行替换操作以使所述预训练语言模型从所述语句关联向量中抽取所述事件触发词以及论元,同时确定事件类型,并将所述事件语句模板中的一个所述占位符被替换为所述事件触发词或所述若干个论元之一;
34、重复所述替换操作直至所述若干个占位符全部替换完成后,得到抽取完成的事件语句;其中,在每一次重复所述替换操作前,将上一次替换得到的目标模板重新输入至所述预训练语言模型的decoder层。
35、作为一个优选的实施例,所述替换操作具体包括:
36、当所述decoder层接收到所述语句关联向量以及所述目标模板后,通过建立条件概率模型选择需要被替换的占位符;其中,所述条件概率模型具体为:
37、
38、其中,为所述占位符,为所述语句关联向量;
39、当根据所述条件概率模型计算得到各占位符的被替换概率后,选取所述被替换概率最大的占位符作为替换符;
40、根据所述替换符的类别,从所述语句关联向量中提取对应的所述事件触发词或论元,并将所述替换符对应替换为所述事件触发词或论元,完成替换操作。
41、作为一个优选的实施例,所述确定事件类型,具体包括:
42、当得到所述事件触发词后,根据预设的事件类型对应表,确定所述事件触发词对应的事件类型;其中,所述事件类型对应表包括触发词与事件类型间的对应关系,一个触发词对应一个事件类型。
43、本发明另一实施例提供一种基于信息增强的提示学习事件抽取装置,所述事件抽取装置应用如上述发明实施例提供的基于信息增强的提示学习事件抽取方法,所述事件抽取装置包括:字词信息编码获取模块、提示模板构造模块、输入模块、输出模块以及事件语句获取模块;其中,
44、所述字词信息编码获取模块用于将待抽取事件的语料转换为若干个字嵌入向量,将所述若干个字嵌入向量输入至lattice lstm模型,得到若干个字词信息编码;
45、所述提示模板构造模块用于通过词汇链构造历史事件信息,并根据预设的训练数据集统计高频触发词;其中,所述训练数据集中包括已经预先标注触发词、事件类型以及论元的训练语料;
46、所述输入模块用于将所述若干个字词信息编码、所述历史事件信息、所述高频触发词以及预设目标模板输入至预训练语言模型,输出得到语句关联向量;
47、所述事件语句获取模块用于在所述预设目标模板中选取与所述语句关联向量匹配度最高的目标模板,根据所述目标模板,从所述语句关联向量中抽取得到事件触发词以及若干个论元,同时确定事件类型,并将所述事件触发词、事件类型以及若干个论元组合为完整的事件语句。
48、进一步的,所述字词信息编码获取模块用于将待抽取事件的语料转换为若干个字嵌入向量,将所述若干个字嵌入向量输入至lattice lstm模型,得到若干个字词信息编码,具体包括:
49、所述lattice lstm模型包括若干个lattice结构以及主干lstm结构;
50、将所述语料作为输入序列输入至word2vec模型,得到若干个字嵌入向量;其中,一个字嵌入向量对应一个字符;
51、将对应的所述若干个字嵌入向量分别输入至所述主干lstm结构中,对应得到若干个第一输出向量;
52、根据所述语料,在预设字词库中检索所述语料中的若干个潜在词,并将检索到的潜在词对应的词嵌入向量一一输入至所述lattice结构中,分别对应得到若干个第二输出向量;其中,所述潜在词由所述语料中的若干个连续字符组成;
53、根据所述潜在词,将所述潜在词的尾字对应的第一输出向量与该潜在词对应的第二输出向量进行归一计算,得到若干个第三输出向量;其中,一个所述第三输出向量对应一个所述潜在词的尾字;
54、当所述语料中的字符不为所述潜在词的尾字时,将该字符对应的所述第一输出向量输入至所述主干lstm结构的输出门,得到对应的所述字词信息编码;
55、当所述语料中的字符为所述潜在词的尾字时,将该字符对应的所述第三输出向量输入至所述主干lstm结构的输出门,得到对应的所述字词信息编码。
56、与现有技术相比,本发明技术方案的有益效果是:
57、引入lattice lstm结构,在不同路径上进行推理和学习,根据上下文信息自适应地融合潜在的词汇,利用上下文信息和潜在的词汇建模来提供更准确和鲁棒的事件抽取结果,避免以往模型输入前因分词而导致的累计错误。
58、基于提示学习的思想,设计一个显示的提示模板,使得模型更好地利用先验知识的共享和依赖关系,与以往的模型相比,能在少资源的情况下,具有更好的事件抽取能力。
- 还没有人留言评论。精彩留言会获得点赞!