一种驾驶状态图像数据集的增广方法、增广装置与流程
本发明涉及机器视觉,具体涉及一种驾驶状态图像数据集的增广方法、一种驾驶状态图像数据集的增广装置和一种非临时性计算机可读存储介质。
背景技术:
1、随着智能驾驶功能的发展,越来越多的技术应用到智能驾驶功能上,例如,驾驶过程中驾驶员驾驶状态的监督功能,以在驾驶员出现错误驾驶行为时对驾驶员进行提醒,例如,驾驶员手持手机打电话、侧头与乘客交谈等。驾驶过程中驾驶员驾驶状态的监督功能一般通过训练后的机器学习网络实现。可以知道,机器学习网络在训练时需要采集大量的相应的真实图像形成数据集。
2、目前,驾驶员驾驶状态图像数据集通常在驾驶员动作这一维度上多样性较为丰富,而由于参与数据采集的被试者和被试车辆有限,在其他维度(如驾驶员外貌、衣着、车内背景等)上多样性有限,为提高机器学习网络的准确性,需要对驾驶员驾驶状态图像数据集进行增广。
3、相关技术中,对驾驶员驾驶状态图像数据集做增广的方法大体包括以下三种思路:图像变换、生成式数据增广以及基于3d(三维)渲染的数据增广。
4、其中,图像变换或多种图像变换的组合主要包括:几何变换(旋转、翻转、仿射变换、透视变换、裁剪、填充等)和颜色变换(调节亮度、对比度、饱和度、色调、锐度等,以及加噪、模糊)。然而,由于驾驶员驾驶状态图像内容较为复杂,涉及驾驶员姿态、表情、车内背景等多个关键部分,图像变换无法真正生成数据集中原本没有的样本,也不能使数据集的多样性有效增加。
5、生成式数据增广通常基于小样本图像生成领域思路,常见的对规模不足的小数据集做生成式数据增广的范式包括模型迁移和可导增广两类,上述两种范式或者需要多样性充足的源数据集,或者需要目标小数据集本身具有一定的多样性。对于现有的驾驶员驾驶状态数据集而言,通常既不满足可导增广范式需要的多样性水平,又无法找到与之高度相关、域差异足够小的源数据集。所以,生成式数据增广通常也无法产生足够真实且多样的驾驶员驾驶状态图像样本。
6、基于3d渲染的数据增广采用3d建模的方法,由于3d建模本身属于对现实世界的低维模拟,其人物外观、表情、动作、位置、车内背景等部分的真实性取决于建模的精细程度。以当前通常的建模水平而言,采取3d渲染得到的驾驶员驾驶状态图像仍与真实采集的数据集图像存在较大的域差异,可能会在使用增广图像的下游任务中对效果产生明显的负面影响。
7、也就是说,上述的对驾驶员驾驶状态数据集做增广的三种方式均不能产生既真实又多样的驾驶状态图像样本。
技术实现思路
1、为解决上述技术问题,本发明的第一个目的在于提出一种驾驶状态图像数据集的增广方法,能够生成真实性、多样性均较好的驾驶员驾驶状态图像,从而实现驾驶状态图像数据集的有效增广。
2、本发明的第二个目的在于提出一种驾驶状态图像数据集的增广装置。
3、本发明的第三个目的在于提出一种计算机设备。
4、本发明的第四个目的在于提出一种非临时性计算机可读存储介质。
5、本发明采用的技术方案如下:
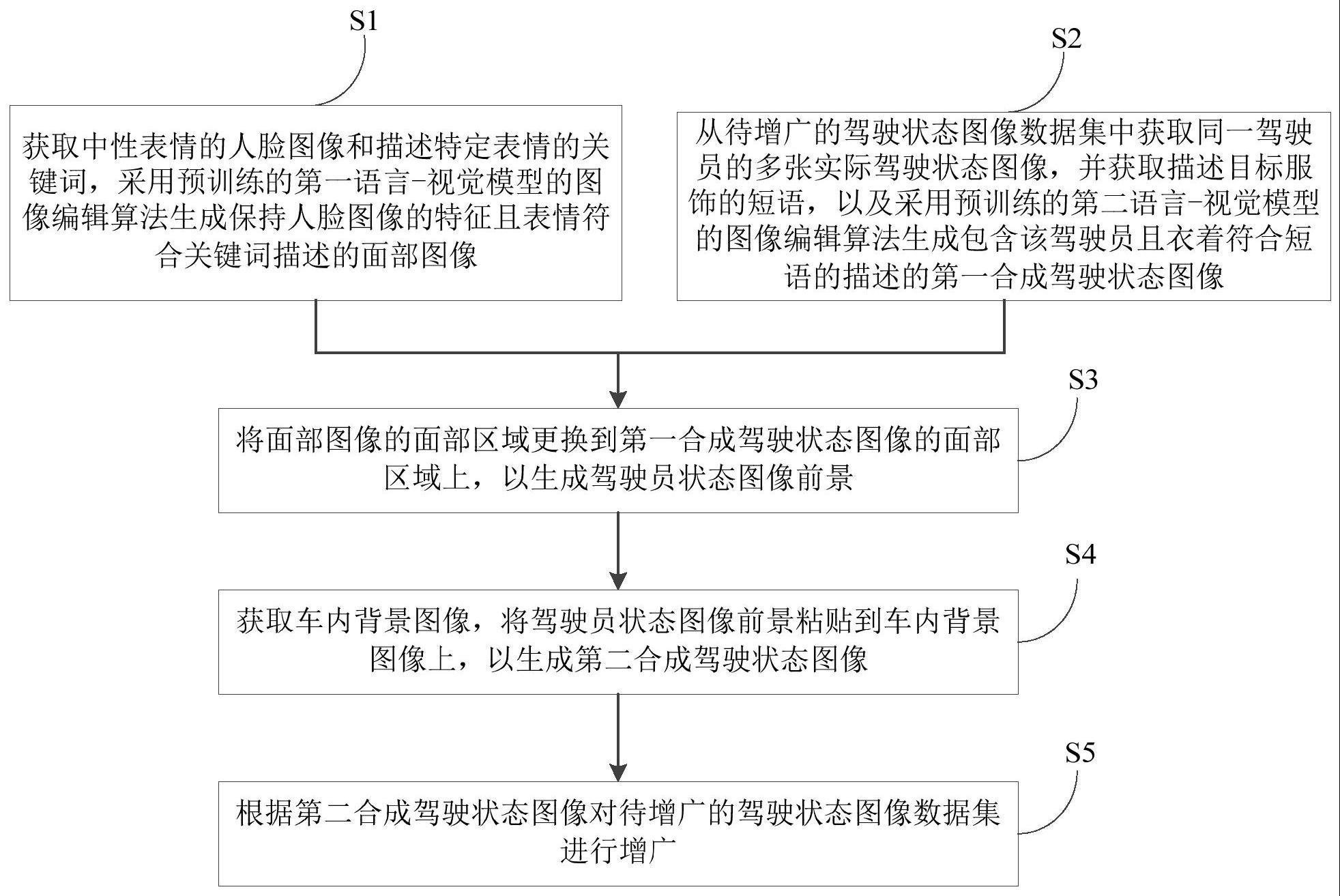
6、本发明的第一方面实施例提出了一种驾驶状态图像数据集的增广方法,包括以下步骤:获取中性表情的人脸图像,并获取描述特定表情的关键词,以及采用预训练的第一语言-视觉模型的图像编辑算法生成保持所述人脸图像的特征且表情符合所述关键词的描述的面部图像;从待增广的驾驶状态图像数据集中获取同一驾驶员的多张实际驾驶状态图像,并获取描述目标服饰的短语,以及采用预训练的第二语言-视觉模型的图像编辑算法生成包含该驾驶员且衣着符合所述短语的描述的第一合成驾驶状态图像;将所述面部图像的面部区域更换到所述第一合成驾驶状态图像的面部区域上,以生成驾驶员状态图像前景;获取车内背景图像,将所述驾驶员状态图像前景粘贴到所述车内背景图像上,以生成第二合成驾驶状态图像;根据所述第二合成驾驶状态图像对所述待增广的驾驶状态图像数据集进行增广。
7、本发明上述提出的驾驶状态图像数据集的增广方法还可以具有如下附加技术特征:
8、根据本发明的一个实施例,在生成所述第二合成驾驶状态图像之后,上述的驾驶状态图像数据集的增广方法还包括:对所述第二合成驾驶状态图像进行和谐化处理,以便根据和谐化后的第二合成驾驶状态图像对所述待增广的驾驶状态图像数据集进行增广。
9、根据本发明的一个实施例,对所述第二合成驾驶状态图像进行和谐化处理,具体包括:根据所述第二合成驾驶状态图像的背景区域中图像像素间的梯度信息对前景区域中的像素进行编辑修改,和/或,采用深度学习网络自动对所述第二合成驾驶状态图像在光照、对比度以及语义上的和谐度进行调整。
10、根据本发明的一个实施例,采用预训练的第一语言-视觉模型的图像编辑算法生成保持所述人脸图像的特征且表情符合所述关键词的描述的面部图像,具体包括:根据所述关键词的监督在生成式模型内部解耦良好的隐特征空间上学得符合所述关键词描述的修改特征向量;利用在生成式模型,在对应隐特征向量上叠加所述修改特征向量,生成保持所述人脸图像的特征且表情符合所述关键词描述的面部图像。
11、根据本发明的一个实施例,采用预训练的第二语言-视觉模型的图像编辑算法生成包含该驾驶员且衣着符合所述短语的描述的第一合成驾驶状态图像,具体包括:根据多张实际驾驶状态图像微调预训练的第二语言-视觉模型,使所述预训练的第二语言-视觉模型在给定特殊占位词时能够生成实际驾驶状态图像中所包含的驾驶员的图像;将所述描述服饰的短语与所述占位词拼接组成短句,并依据所述短句生成包含所述驾驶员且衣着符合所述目标服饰的短语描述的第一合成驾驶状态图像。
12、根据本发明的一个实施例,具体采用以下步骤生成所述第二合成驾驶状态图像:选取关键点并分别标注在驾驶员状态图像前景和车内背景图像中;将去掉背景的驾驶员状态图像前景根据所述关键点做透视变换后,粘贴到所述车内背景图像上;将粘贴后的图像进行裁剪,生成所述第二合成驾驶状态图像。
13、本发明第二方面的实施例提出了一种驾驶状态图像数据集的增广装置,包括:第一生成模块,所述第一生成模块用于获取中性表情的人脸图像,并获取描述特定表情的关键词,以及采用预训练的第一语言-视觉模型的图像编辑算法生成保持所述人脸图像的特征且表情符合所述关键词的描述的面部图像;第二生成模块,所述第二生成模块用于从待增广的驾驶状态图像数据集中获取同一驾驶员的多张实际驾驶状态图像,并获取描述目标服饰的短语,以及采用预训练的第二语言-视觉模型的图像编辑算法生成包含该驾驶员且衣着符合所述短语的描述的第一合成驾驶状态图像;第三生成模块,所述第三生成模块用于将所述面部图像的面部区域更换到所述第一合成驾驶状态图像的面部区域上,以生成驾驶员状态图像前景;第四生成模块,所述第四生成模块用于获取车内背景图像,将所述驾驶员状态图像前景粘贴到所述车内背景图像上,以生成第二合成驾驶状态图像;增广模块,所述增广模块用于根据所述第二合成驾驶状态图像对所述待增广的驾驶状态图像数据集进行增广。
14、本发明上述提出的驾驶状态图像数据集的增广装置还可以具有如下附加技术特征:
15、根据本发明的一个实施例,上述的驾驶状态图像数据集的增广装置还包括:和谐模块,所述和谐模块用于对所述第二合成驾驶状态图像进行和谐化处理,以便所述增广模块根据和谐化后的第二合成驾驶状态图像对所述待增广的驾驶状态图像数据集进行增广。
16、根据本发明的一个实施例,所述和谐模块具体用于:根据所述第二合成驾驶状态图像的背景区域中图像像素间的梯度信息对前景区域中的像素进行编辑修改,和/或,采用深度学习网络自动对所述第二合成驾驶状态图像在光照、对比度以及语义上的和谐度进行调整
17、根据本发明的一个实施例,所述第一生成模块具体用于:根据所述关键词的监督在生成式模型内部解耦良好的隐特征空间上学得符合所述关键词描述的修改特征向量;利用在生成式模型,在对应隐特征向量上叠加所述修改特征向量,生成保持所述人脸图像的特征且表情符合所述关键词描述的面部图像。
18、根据本发明的一个实施例,所述第二生成模块具体用于:根据多张实际驾驶状态图像微调预训练的第二语言-视觉模型,使所述预训练的第二语言-视觉模型在给定特殊占位词时能够生成实际驾驶状态图像中所包含的驾驶员的图像;将所述描述服饰的短语与所述占位词拼接组成短句,并依据所述短句生成包含所述驾驶员且衣着符合所述目标服饰的短语描述的第一合成驾驶状态图像。
19、根据本发明的一个实施例,所述第四生成模块具体用于:选取关键点并分别标注在驾驶员状态图像前景和车内背景图像中;将去掉背景的驾驶员状态图像前景根据所述关键点做透视变换后,粘贴到所述车内背景图像上;将粘贴后的图像进行裁剪,生成所述第二合成驾驶状态图像。
20、本发明的第三方面实施例提出了一种计算机设备包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时,实现根据本发明第一方面实施例所述的驾驶状态图像数据集的增广方法。
21、本发明的第四方面实施例提出了一种非临时性计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现根据本发明的第一方面实施例所述的驾驶状态图像数据集的增广方法。
22、本发明的有益效果:
23、本发明应对驾驶状态这一复杂应用情形,可以生成现有数据集以外的驾驶员面部、服饰、车内背景等各部分图像,使图像数据的多样性得到大幅提升,且本发明基于已有的真实图像进行增广,生成的图像更贴近真实的驾驶状态,域差异更小,即本发明能够生成真实性、多样性均较好的驾驶员驾驶状态图像,从而实现驾驶状态图像数据集的有效增广;
24、本发明采用了基于文字提示或参考图像的条件生成方法,例如通过文字提示指定驾驶员的表情,或通过文字提示或参考服装图像指定驾驶员的衣着等等,可以一定程度上实现可控生成;
25、由于采用分步对图像的不同部分做增广的总体构思,能够降低数据增广的难度。
- 还没有人留言评论。精彩留言会获得点赞!