一种实时戴口罩人脸关键点检测和人脸质量评估方法与流程
本发明涉及一种戴口罩人脸关键点检测和人脸质量评估的方法,适用于人工智能中视频监控相关行业,属于计算机视觉领域。
背景技术:
1、人脸检测和人脸关键点检测在很多计算机视觉领域的应用中是一个非常基础而且关键的模块,比如人脸重建、人脸属性编辑、人脸识别以及视频监控等,特别是在视频监控中,准确捕获到人脸关键点对人脸识别来说很重要。
2、当前的人脸检测和关键点检测是在基于无口罩人脸的数据集上训练的,但随着口罩成为人们生活的必备品,如何准确检测戴口罩人脸的关键点成为了一个难题,目前没有相关的论文和专利。究其原因,首先,目前缺乏戴口罩人脸关键点检测公开数据集,其次,对戴口罩人脸数据人工标注关键点难度很大。
3、人脸质量是由几个反映真实场景的图片属性的组合,比如亮度、对比度、角度、表情、噪音、分辨率以及化妆等,人脸质量评估fiqa(face image quality assessment)算法在计算机视觉中已经被广泛的研究。当前的人脸质量评估方法大致可以分为两类:基于分析的fiqa和基于深度学习的fiqa。基于分析的fiqa通过人类的视觉系统来定义人脸质量的度量方式,并使用手工特征来评价人脸质量好坏,比如人脸的对称性、光照强度以及垂直边缘密度等。但是这类方法只能针对不同的人脸图片质量下降方式来提取不同的特征,无法应对所有可能的质量下降方式。因此,更多的研究者聚焦基于深度学习的fiqa,这类方法通常和人脸识别模型相结合来生成人脸图片的质量,最典型的方式是通过拟合一个人脸识别模型到图片之间的映射函数。当前主流的方法是使用深度学习网络生成的特征向量来直接评估人脸质量。faceqnet-v0提出了一种为每一个人脸id寻找相应的最高质量的人脸的方法,并把找到的这个高质量人脸作为这个类的代理,然后只需要通过人脸特征向量的欧氏距离就可以判断人脸质量,但是当一个人出现不同年龄的人脸时会误判。在此基础上,faceqnet-v1提出了使用当前三个主流的人脸识别系统来计算人脸质量。ser-fiq提出了一种无监督的评估方式,通过研究图像随机嵌入空间的变化,即使用dropout实现网络的变体,利用不同变体提取特征的稳定性,从而来评价图像的质量。pcnet采用了一种通过深度神经网络从类内相似度学习成对的回归损失。sdd-fiqa提出以上的方法都是通过同一类的类内样本的不确定性或者成对的相似度来评估人脸图片质量,但是没有利用到类内和类间相似度之间的关系,但这个关系也是种非常重要的信息,基于此提出了使用wassersteindistance来度量类内相似度分布和类间相似度分布作为质量伪标签,基于这个伪标签来训练一个轻量化的人脸质量回归网络。虽然基于深度学习的fiqa方法取得了不错的性能,但是仍然有几个难题难以解决。首先,当前的监控视频下的人脸戴口罩的居多,但是戴口罩的人脸识别公开数据集很少,因此导致基于人脸识别模型来判断人脸质量性能会变差。其次,sdd-fiqa需要一个人脸质量回归模型,加大了系统的复杂度和计算量。。
技术实现思路
1、本发明要解决的技术问题是:对于监控系统中的人脸识别来说,获取高质量的人脸至关重要,特别是当下的戴口罩人脸来说,如何精确戴口罩人脸的关键点和评估人脸质量成为了一个有挑战性的难题。
2、为了解决上述技术问题,本发明的技术方案是提供了一种实时戴口罩人脸关键点检测和人脸质量评估方法,其特征在于,包括以下步骤:
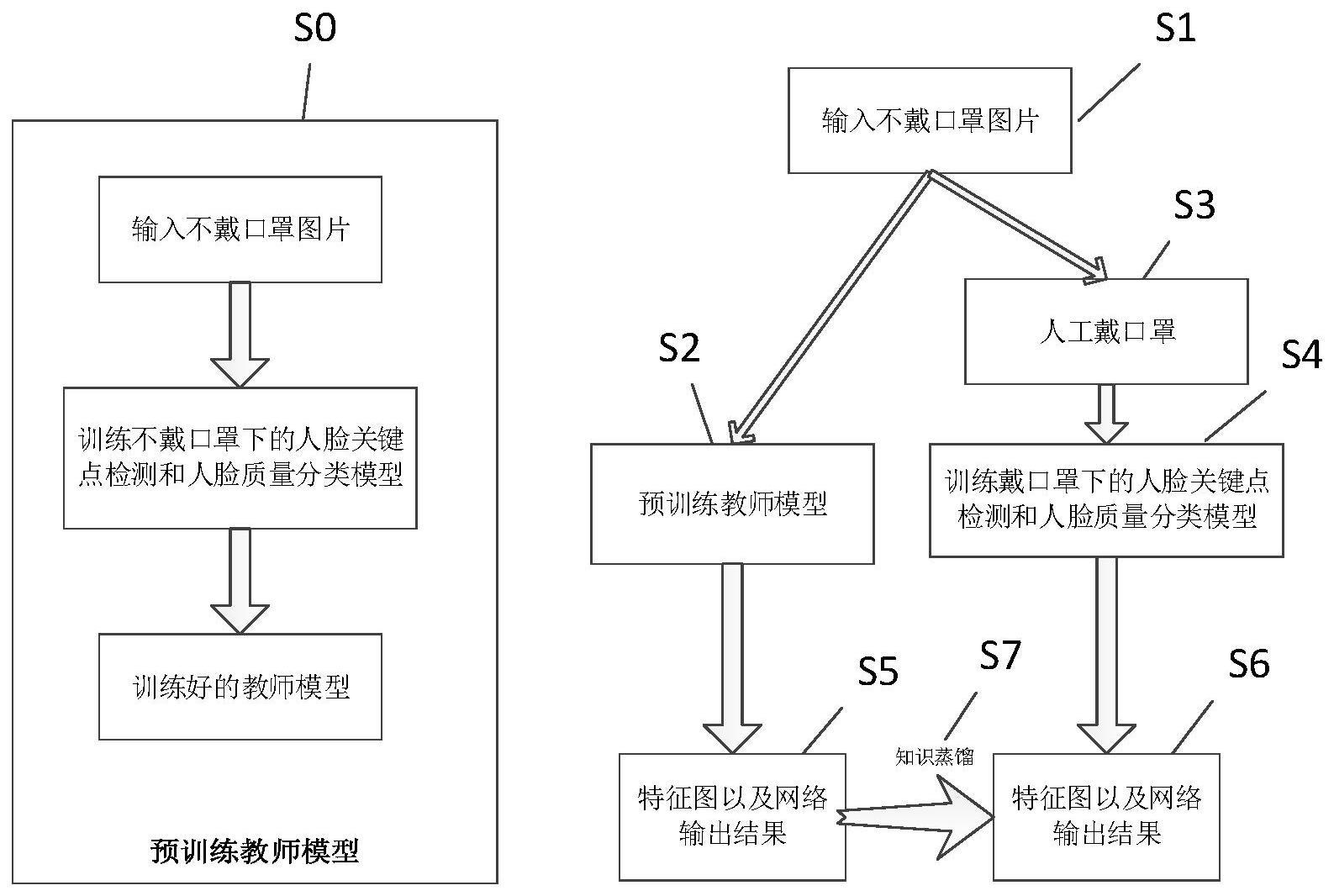
3、步骤1、获取已经标注人脸关键点的人脸图片,将每张人脸图片上的人脸按照不同的人脸质量分为n类,获得每张人脸图片上的不同人脸所对应的人脸质量分类标签,获得大规模人脸关键点检测数据集
4、步骤2、利用步骤1得到的大规模人脸关键点检测数据集训练教师模型,该教师模型的backbone为swin transformer,该教师模型的neck层使用rfp,该教师模型的head层分为人脸框回归分支、人脸关键点回归分支以及人脸质量分类分支,其中,人脸框回归分支用于实现人脸检测任务,人脸关键点回归分支用于实现人脸关键点检测任务,人脸质量分类分支用于实现人脸质量评估的分类任务;
5、步骤3、从大规模人脸关键点检测数据集中随机采样一张不戴口罩的样本图片;
6、步骤4、固定步骤2训练好的教师模型的参数,将步骤s1获得不戴口罩的样本图片输入到教师模型中;
7、步骤5、将步骤3获得的样本图片中所有的人脸进行人工合成戴口罩,获取戴口罩的样本图片;
8、步骤6、建立学生模型,将步骤5获得的戴口罩的样本图片输入到学生模型中,该学生模型的backbone为mobilenetv2,该学生模型的neck层使用rfp,该学生模型的head层分为四个分支,分别为人脸二分类分支、人脸框回归分支、人脸关键点回归分支、人脸质量分类分支,其中,通过人脸二分类分支对人脸戴口罩和不戴口罩进行分类;
9、步骤7、获取教师模型的neck层里的特征图以及head层输出的人脸质量分类的输出结果;
10、步骤8、获取学生模型的neck层里的特征图以及head层输出的人脸质量分类的输出结果;
11、步骤9、分别对步骤7和步骤8对应的特征图和分类结果进行知识蒸馏,利用训练好的学生模型进行实时的戴口罩人脸关键点检测和人脸质量评估。
12、优选地,在步骤1中,所述人脸图片为实际监控场景下采集的人脸图片。
13、优选地,在步骤1中,将每张人脸图片上的人脸按照不同的人脸质量分为五类,分别为高质量、较高质量、中等质量、较低质量、较低质量。
14、优选地,在步骤5中,采用以下步骤获得戴口罩的样本图片:
15、步骤501、对步骤3获得的样本图片进行人脸检测;
16、步骤502、对检测到的所有人脸进行关键点检测;
17、步骤503、通过关键点和随机生成的口罩图片合成戴口罩的人脸图片,获得戴口罩的样本图片。
18、优选地,在步骤9中,在训练学生模型时,采用的联合训练的目标函数loss表示为:
19、loss=l1+l2+l3+l4+mse_loss+fgd_loss
20、式中,l1为学生模型的人脸二分类分支的二分类损失,l2为学生模型的人脸框回归分支的回归损失,l3为学生模型的人脸关键点回归分支的回归损失,l4为学生模型的人脸质量分类分支的分类损失,mse_loss为特征图的蒸馏损失,fgd_loss为分类的蒸馏损失。
21、鉴于质量差的人脸图片很难预测出准确的人脸关键点,而人脸质量高的时候人脸关键点检测也会准,这样两个任务一起联合训练就会相互促进。在监控场景下,如果单独训练其中一个任务都非常难,联合训练会有更好的效果。本发明使用一种联合训练方式同时训练戴口罩人脸关键点检测和人脸质量评估两个任务,使得两个任务同时达到比较高的性能,并成功应用到监控系统中。
22、相比于现有技术而言,本发明的创新之处在于:
23、第一,本发明制作了一个大型的监控场景下人脸关键点检测数据集;
24、第二,通过一种多任务联合训练的方法,即采用对口罩检测、人脸检测、戴口罩人脸关键点检测和人脸质量评估进行联合训练,能够同时解决多个任务,并能有效的提升各个任务的性能;
25、第三,训练的轻量化模型部署到实际场景达到了实时检测的能力,能精确识别出戴口罩人脸的关键点的同时准确的筛选出高质量的人脸,大大提升了监控视频里的人脸识别准确性。
- 还没有人留言评论。精彩留言会获得点赞!