考虑非共有类别样本的迁移学习方法
本发明涉及轴承故障诊断方法,尤其涉及一种考虑非共有类别样本的迁移学习方法。
背景技术:
1、轮对轴承是高速列车的关键部件之一。它在运行时容易受到高载荷和高转速的影响,而使得其产生局部磨损和损坏。轮对轴承发生故障会使列车产生巨大振动和噪声,甚至急停、脱轨等灾难性后果。因此高速列车轮对轴承故障诊断对保证列车安全可靠运行的至关重要。
2、随着人工智能技术的发展,基于深度学习的轴承故障诊断方法由于其可以自动对目标进行特征提取和故障分类,而不需要其他额外特征工程的支持,正越来越地受到关注。工业大数据和云计算能力的提升,也使得端到端的故障诊断算法在自动化、可靠性以及准确性方面有了较大提升。以卷积神经网络为代表的故障诊断模型,非常依赖大量的有标签数据。在现阶段,轮对轴承的故障数据还无法大量收集。这就使得这类模型很难达到预期的故障诊断精度。且深度学习模型进行故障诊断的前提是训练数据集与测试数据集具有相同的空间分布。而在实际的工业运用当中,由于轮对轴承的转速、载荷等工况的不同,使获取到的样本的分布空间差异很大,导致利用单一工况训练出来的模型不能很好的应用于其他工况。
3、为了解决上述问题,迁移学习方法被应用于轴承故障诊断领域,以解决上述深度学习中无法有效解决的问题。迁移学习在轴承故障诊断领域具有两个优势。首先迁移学习可以很好地解决无监督于适应问题。使得收集到的无标签样本可以被有效利用和诊断。第二是它可以拟合不同工况下的样本特征,使不同分布空间下的故障样本可以有效被诊断。现有的迁移学习方法虽然可以将一个源域学习到另一个目标域中。但在训练时,通常目标域样本的数量要与源域数量相当。然而在工业应用时源域样本通常是一次集中的跟踪试验,或实验室获取的数据。目标域数据通常是某次故障诊断工作开始后才开始进行收集。因此源域数据的工况、故障种类以及样本数量会远远大于目标域。因此这些问题限制了当前迁移学习模型的实用性。
4、通过分析上述问题,不难发现主要有两个迁移学习中的问题亟待解决。(1)如何充分利用现有样本和其中的有效信息。(2)如何仅用单一模型来增加迁移学习模型的适用范围。
技术实现思路
1、本发明所要解决的技术问题是如何提供一种可以提高大数据源域的利用效率和故障诊断精度的考虑非共有类别样本的迁移学习方法。
2、为解决上述技术问题,本发明所采取的技术方案是:一种考虑非共有类别样本的迁移学习方法,包括如下步骤:
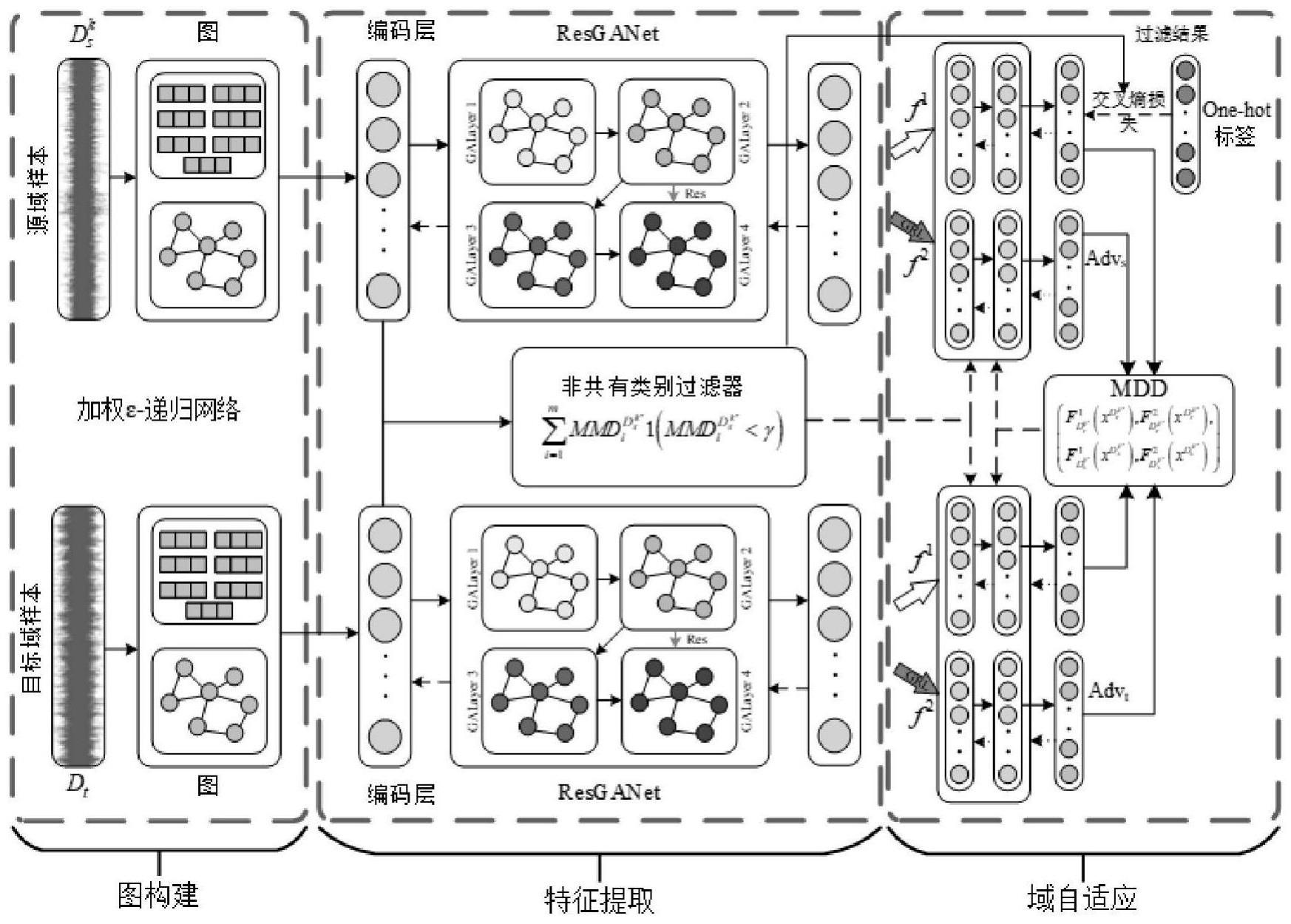
3、首先将原始振动信号处理为图样本;
4、然后利用递归多头图注意力残差网络对其进行特征提取;
5、最后利用mdd动态迁移方式,将源域特征迁移到目标域中;
6、其中,在进行动态迁移的过程中使用非目标域类别过滤器来实现非目标域类别迁移。
7、进一步的技术方案在于,使用加权e-rn算法将原始振动信号处理为图样本,具体包括如下步骤:
8、轴承的振动信号是一个具有n个点的非线性时间序列x,对x以相同的时间延迟进行划分并截取,获得m个具有τ维的向量集合,表示如下:
9、x={x(t),x(t+τ),…,x(t+(m-1)τ)}
10、振动信号的递归图g由一个二维递归矩阵r表示,通过计算两个矢量间的任意范数,获取两个矢量间的递归程度;设定参数阈值ε作为判断是否发生递归的阈值;通过计算得到递归矩阵即可表示两个矢量间是否是递归对;递归矩阵的计算方法如下:
11、ri,j=θ(ε-||x(ti)-x(tj)||)
12、其中||·||表示两个向量的相空间范数;采用余弦相似度作为衡量指标;θ(·)为亥维赛函数,定义为:若两个向量为递归对则ri,j为1,反之为0;
13、由于图神经网络需要将去除递归矩阵r自环进行运算,因此将递归矩阵r转化为邻接矩阵a进行运算,定义如下:
14、a=r-iτ
15、其中,iτ为具有τ维的单位矩阵;递归图g由顶点集合是由顶点集合v={v1,v2,…vp}以及连接顶点之间的边集合e={e1,e2,…eq}组成;其中vi表示顶点,ei表示边,p和q分别表示顶点以及边的数量;
16、通过设定ρ来自适应地调节每张图的e,e为e-rn算法中的参数,递归图的连接密度ρ的定义如下:
17、
18、其中,a表示递归图的邻接矩阵a的元素;d可以分析出递归图中边的数量占总样本全连接时边的比例;从而使构造的递归图的连接密度参数保持一致;由于每组图的递归取值范围不同,因此需要首先获取这张图向量两两间的递归程度,计算如下:
19、[vmax,vmin]=||x(ti)-x(tj)||i,j∈m
20、以最大值vmax和最小值vmin作为取值范围,计算与能使连接密度与设定值ρset最为接近的ε,并将它作为这一个递归图的参数;
21、
22、为了能够将尽可能多地获取样本中的先验知识,提出以顶点集合的范数信息对递归图进行加权;首先获取顶点集合的相空间范数矩阵l,定义如下:
23、li,j=||x(ti)-x(tj)||
24、其中li,j表示相空间范数矩阵l中的元素;将矩阵l归一化后与邻接矩阵a对位相乘,得到加权递归图邻接矩阵q,计算公式如下所示:
25、q=norm(l)a
26、由于l和a都是对称阵,因此将两个矩阵相乘即可得到q矩阵;若两个顶点为递归对,则矩阵q中的对应位置的值为其空间范数值,反之则为0。
27、进一步的技术方案在于,递归多头图注意力残差网络的构成方法包括如下步骤:
28、将两个顶点的空间分布距离在再生希尔伯特空间中运算,使其具有一个完整性的内积空间;高斯核函数的定义如下:
29、
30、其中σ是核函数的带宽;多核高斯函数需要首先设定一个初始σ,并以一定间隔获取k个带宽,分别求得高斯核函数的值并求平均,计算如下:
31、
32、其中r为间隔大小。由于图注意力机制的关注对象为边,因此只有存在边的递归对才会在训练中被计算注意力系数;注意力系数是指当前训练下的递归对的注意力大小;计算每组递归对的注意力系数,构造注意力矩阵,并引入训练参数:
33、
34、其中,p即为所提图注意力矩阵的传播矩阵,β(t)为第t层的训练参数;所提图注意力机制可以表示为:
35、h(t+1)=σ(p(t)h(t))
36、为了提高模型的稳定性,将其拓展为多头图注意力机制;用k个独立的注意力机制对输入特征进行分析,并将其串联作为输出:
37、
38、其中‖表示连接;多头图注意力机制的聚合过程为:
39、
40、以多头图注意力网络为基础,构建递归多头图注意力残差网络,所述残差网络模型主要分为三个部分,特征编码部分、特征提取部分以及分类部分;利用多层感知机作为特征编码部分,其输入与输出维度相同;
41、将一个图注意力层、sigmoid激活函数以及meannorm层作为一个图注意力模块,每层模块都会对输入特征进行聚合,每层的输出如下:
42、
43、采用sigmoid激活函数与meannorm层可以在一定程度上抑制模型的过平滑,其中,
44、
45、在全连接层前引入残差块,将特征编码后的特征与输出特征进行连接,缓解梯度消失以及降低过拟合程度;最终在全连接层中采用softmax得到最终分类结果;
46、得到源域的损失,对目标域与源域具有相同故障类型的样本集采用交叉熵损失计算,即:
47、
48、其中,其中m指类别数量,yi∈(y1,y2,...,yc)是样本的标签,指共有类别在子网络上的输出,通过反向传播算法更新参数。
49、进一步的技术方案在于,使用非目标域类别样本过滤器实现非目标域类别迁移:
50、在子网络中,以编码后的特征为依据,比较非目标域类别的源域样本集与目标域样本的希尔伯特空间分布差异;运用mmd算法计算非目标域图样本中每个顶点与目标域图样本的分布距离,由此可以得到如下:
51、
52、其中表示某一源域顶点与目标域的空间分布距离,k为高斯核函数;非目标域类别过滤器通过设定置信度过滤阈值γ,可将样本分为可用样本与不可用样本;γ取0.1;由此可得非目标域类别补偿损失为:
53、
54、其中1(·)为指示函数,若满足条件输出为1,反之为0;从而过滤掉低置信样本产生的无效补偿;利用同样的方法,采用上述过滤机制对样本的交叉熵损失进行过滤,由此可得过滤后的非目标域类别样本损失为:
55、
56、其中,指非共有类别在子网络上的输出;因此,非目标域类别分类的总损失需要注意的是,与的损失是分别运算的,但是都公用一个分类器f1。
57、进一步的技术方案在于,将源域特征迁移到目标域的方法包括如下步骤:
58、从分类器和标签角度出发,采用分类器掩码矩阵m对目标域样本进行处理,掩码矩阵m的值如下:
59、m=[111…e-9e-9]
60、在对源域样本赋予标签时,采用one-hot编码方式;共有类别的标签靠前,非公有类别的标签靠后;
61、在迁移时采用marginal domain discrepancy(mdd-边际域差异)算法,
62、对抗域差异迁移使用两个分类器f1和f2的的散度来衡量两个数据集之间的分布差异;两个分类器的区别在于f1通过正常分类来获取模型的分类损失,f2通过梯度翻转来获取边缘分布差异;通过最小化分类损失,并最大化边缘分布差异,来实现对抗迁移;因此,所提模型的损失可以整合为:
63、
64、其中,1是两个数据集的指示函数,分别用来度量两个分类器f1和f2在数据集和中的预测差异,e表示两个数据集间的交叉熵损失。h1和h2表示经过特征提取网络与分类器的输出,其中目标域需要用掩码矩阵m进行处理,即:
65、
66、
67、其中,⊙表示两个向量对位相乘;以mdd作为预测差异的度量时,即为:
68、
69、其中,表示源域与目标域之间的mdd损失;argmax表示f1分类器的预测标签;m是mdd的超参数,表示边缘分布的最小差距,用于平衡泛化与优化;通过最小化损失可以最大化同一类别内样本的相似性,从而使得在源域中训练的模型可以适应目标域的数据。
70、采用上述技术方案所产生的有益效果在于:本技术所述方法使用mmd加权的递归多头图注意力残差网络(resganet),用于轮对轴承样本的特征提取,可以显性地拟合样本间关系,提高有效特征的提取效果。提出了非共有类别样本迁移机制,使源域中额外故障类型的样本可以被有效利用。使用空间分布差异加权策略,过滤会产生负迁移的样本,提高非共有类别样本的利用率。所述方法用于高速列车轮对轴承的故障诊断任务,提高了大数据源域的利用效率和故障诊断精度。
- 还没有人留言评论。精彩留言会获得点赞!