一种图像识别的方法、装置、电子设备及存储介质与流程
本说明书涉及计算机,尤其涉及一种图像识别的方法、装置、电子设备及存储介质。
背景技术:
1、随着互联网络的飞速发展,由于图像具有直观、承载信息量大等优势,图像成为互联网平台用户发布信息的主要形式之一。为了吸引流量,不法分子会生成或传播大量违规图像,例如,色情图像、暴力图像等。这些违规图像会造成恶劣的社会影响或对互联网平台的正常运行带来负面影响。基于此,互联网平台需要对用户上传的图像进行识别,避免用户对违规图像进行传播。
2、目前,常用的方法是在大规模数据集上对多模态预训练模型进行训练,从而,通过多模态预训练模型对用户上传的图像进行识别。但是,多模态预训练模型所需的运算资源较多,图像识别的效率较低。
3、因此,如何降低图像识别所需的运算资源以及提高图像识别的效率,则是一个亟待解决的问题。
技术实现思路
1、本说明书提供一种图像识别的方法、装置、存储介质及电子设备,以降低图像识别所需的运算资源以及提高图像识别的效率。
2、本说明书采用下述技术方案:
3、本说明书提供了一种图像识别的方法,所述方法应用于服务端,所述服务端上部署了预先训练的多模态预训练模型以及分类模型,所述多模态预训练模型包含的模型参数的数量大于所述分类模型包含的模型参数的数量,包括:
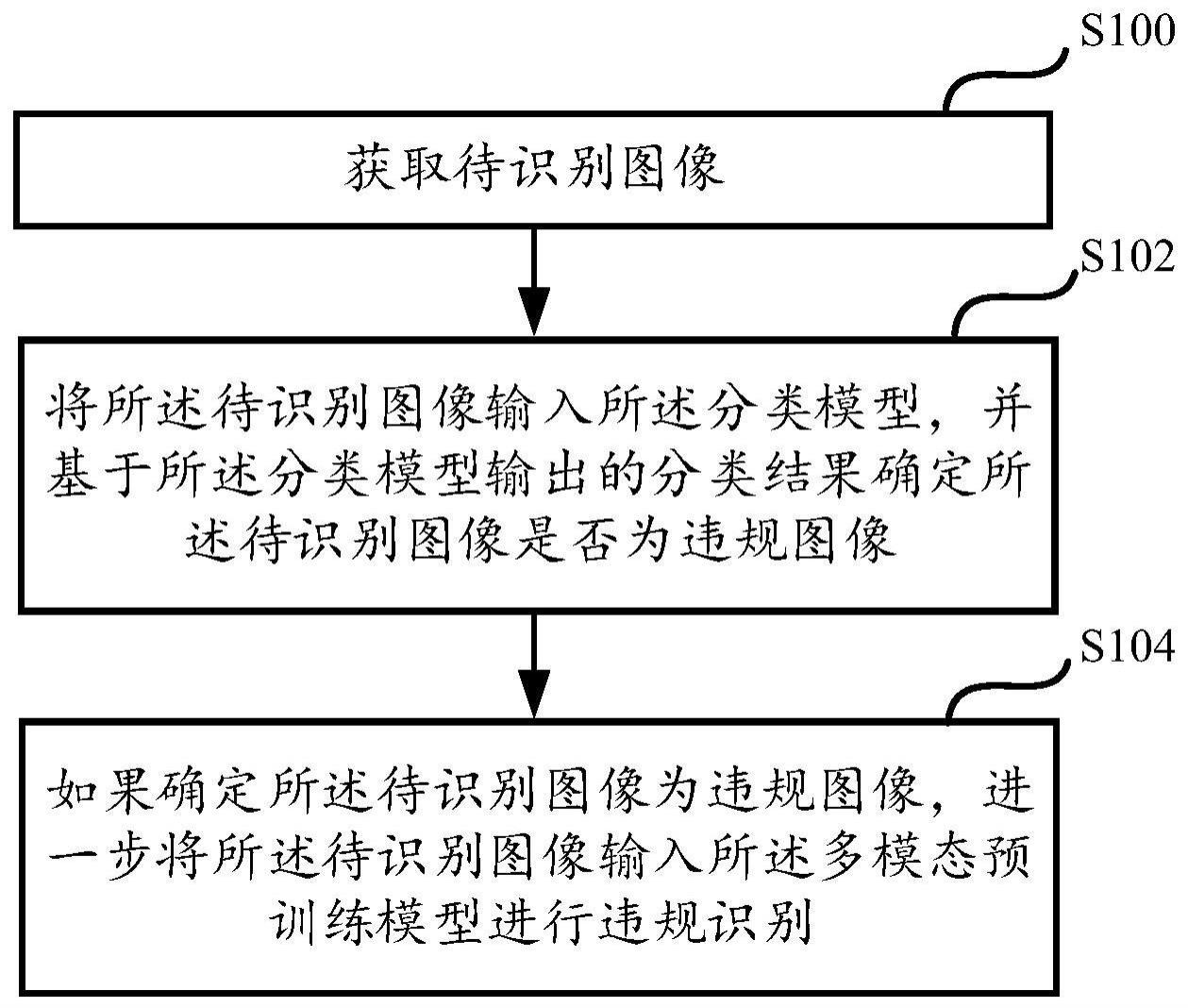
4、获取待识别图像;
5、将所述待识别图像输入所述分类模型,并基于所述分类模型输出的分类结果确定所述待识别图像是否为违规图像;
6、如果确定所述待识别图像为违规图像,进一步将所述待识别图像输入所述多模态预训练模型进行违规识别。
7、可选地,所述分类模型对应的输入图像尺寸,小于所述多模态预训练模型的输入图像尺寸;
8、将所述待识别图像输入所述分类模型,将所述待识别图像输入所述分类模型,并基于所述分类模型输出的分类结果确定所述待识别图像是否为违规图像,包括:
9、按照与所述分类模型对应的输入图像尺寸,针对所述待识别图像进行缩放处理,将缩放后的所述待识别图像输入所述分类模型,并基于所述分类模型输出的分类结果确定所述待识别图像是否为违规图像。
10、可选地,所述服务端上部署了对应的输入图像尺寸存在差异的多个分类模型;
11、按照与所述分类模型对应的输入图像尺寸,针对所述待识别图像进行缩放处理,将缩放后的所述待识别图像输入所述分类模型,并基于所述分类模型输出的分类结果确定所述待识别图像是否为违规图像,包括:
12、将所述多个分类模型按照所述输入图像尺寸的从小到大的顺序进行排序;
13、按照排序后的所述多个分类模型中的第一分类模型对应的输入图像尺寸,针对所述待识别图像进行缩放处理,将缩放后的所述待识别图像输入所述第一分类模型,并基于所述第一分类模型输出的分类结果确定所述待识别图像是否为违规图像;
14、如果是,继续按照排序后的所述多个分类模型中的第二分类模型对应的输入图像尺寸,针对所述待识别图像进行缩放处理,将缩放后的所述待识别图像输入所述第二分类模型,并基于所述第二分类模型输出的分类结果确定所述待识别图像是否为违规图像,以此类推,直到按照排序后的所述多个分类模型中的最后一个分类模型对应的输入图像尺寸,针对所述待识别图像进行缩放处理,并将缩放后的所述待识别图像输入所述最后一个分类模型中。
15、可选地,如果确定所述待识别图像为违规图像,进一步将所述待识别图像输入所述多模态预训练模型进行违规识别,包括:
16、基于所述最后一个分类模型输出的分类结果确定所述待识别图像是否为违规图像;如果是,进一步将所述待识别图像输入所述多模态预训练模型进行违规识别。
17、可选地,所述方法还包括:
18、如果确定所述多个分类模型中的任一分类模型输出所述待识别图像为未违规图像的分类结果,不再将缩放后的所述待识别图像输入到位于该分类模型所在排序位置之后的其他分类模型中。
19、可选地,所述多模态预训练模型包括:视觉问答模型;
20、将所述待识别图像输入所述多模态预训练模型进行违规识别,包括:
21、获取用于违规识别的多个文本问题;
22、将所述待识别图像以及所述多个文本问题输入到视觉问答模型中,基于针对所述多个文本问题的回复文本,确定所述待识别图像是否为违规图像。
23、可选地,所述分类模型是以最小化漏检率为优化目标进行优化调整训练的,所述漏检率是指违规图像被分类为不违规图像的数量占所述违规图像的数量的比值。
24、可选地,在将所述待识别图像输入所述分类模型之前,所述方法还包括:
25、判断所述用户黑名单中是否包含所述待识别图像的用户信息,如果是,确定所述待识别图像为违规图像;
26、判断所述用户白名单中是否包含所述待识别图像的用户信息,如果是,确定所述待识别图像为未违规图像。
27、可选地,在将所述待识别图像输入所述分类模型之前,所述方法还包括:
28、对所述待识别图像进行边缘检测,确定所述待识别图像包含的图像目标的边缘信息;
29、根据所述待识别图像包含的图像目标的边缘信息的数量,确定所述待识别图像是否为违规图像。
30、可选地,所述视觉问答模型包括:blip模型。
31、可选地,所述待识别图像包括:用户使用基于ai的绘制程序绘制的图像。
32、本说明书提供了一种图像识别的装置,所述装置应用于服务端,所述服务端上部署了预先训练的多模态预训练模型以及分类模型,所述多模态预训练模型包含的模型参数的数量大于所述分类模型包含的模型参数的数量,包括:
33、获取模块,用于获取待识别图像;
34、执行模块,用于将所述待识别图像输入所述分类模型,并基于所述分类模型输出的分类结果确定所述待识别图像是否为违规图像;
35、输入模块,用于如果确定所述待识别图像为违规图像,进一步将所述待识别图像输入所述多模态预训练模型进行违规识别。
36、本说明书提供了一种电子设备,包括通信接口、处理器、存储器和总线,所述通信接口、所述处理器和所述存储器之间通过总线相互连接;
37、所述存储器中存储机器可读指令,所述处理器通过调用所述机器可读指令,执行上述图像识别的方法。
38、本说明书提供了一种机器可读存储介质,所述机器可读存储介质存储有机器可读指令,所述机器可读指令在被处理器调用和执行时,实现上述图像识别的方法。
39、本说明书采用的上述至少一个技术方案能够达到以下有益效果:
40、在本说明书提供的图像识别的方法中,多模态预训练模型包含的模型参数的数量大于分类模型包含的模型参数的数量,本方法可以将待识别图像输入分类模型,并基于分类模型输出的分类结果确定待识别图像是否为违规图像,从而识别出识别难度较小的待识别图像,筛选出识别难度较大的待识别图像。如果确定待识别图像为违规图像,进一步将识别难度较大的待识别图像输入多模态预训练模型进行违规识别,从而降低图像识别所需的运算资源以及提高图像识别的效率。
- 还没有人留言评论。精彩留言会获得点赞!