对话交互方法、装置、设备和存储介质与流程
本公开涉及人工智能,尤其涉及对话交互方法、装置、设备和存储介质。
背景技术:
1、随着技术的不断发展,对话助手越来越多地出现在人们的日常生活工作中。对话助手是一种基于人工智能技术的软件,能够与用户进行自然语言交流,使用自然语言处理和深度学习等技术来理解用户的输入信息,然后生成相应的回复。例如客服问答机器人就是一种常见的对话助手。
2、相关技术中,当用户输入的内容较为复杂时,对话助手生成的回复文本也可能变得复杂。这样的情况下,在显示界面上呈现大段文字会影响用户的交互体验,使用户阅读起来困难,理解效率降低。
技术实现思路
1、本技术实施例的主要目的在于提出对话交互方法、装置、设备和存储介质,能够提高显示内容的直观性,提升用户的交互体验。
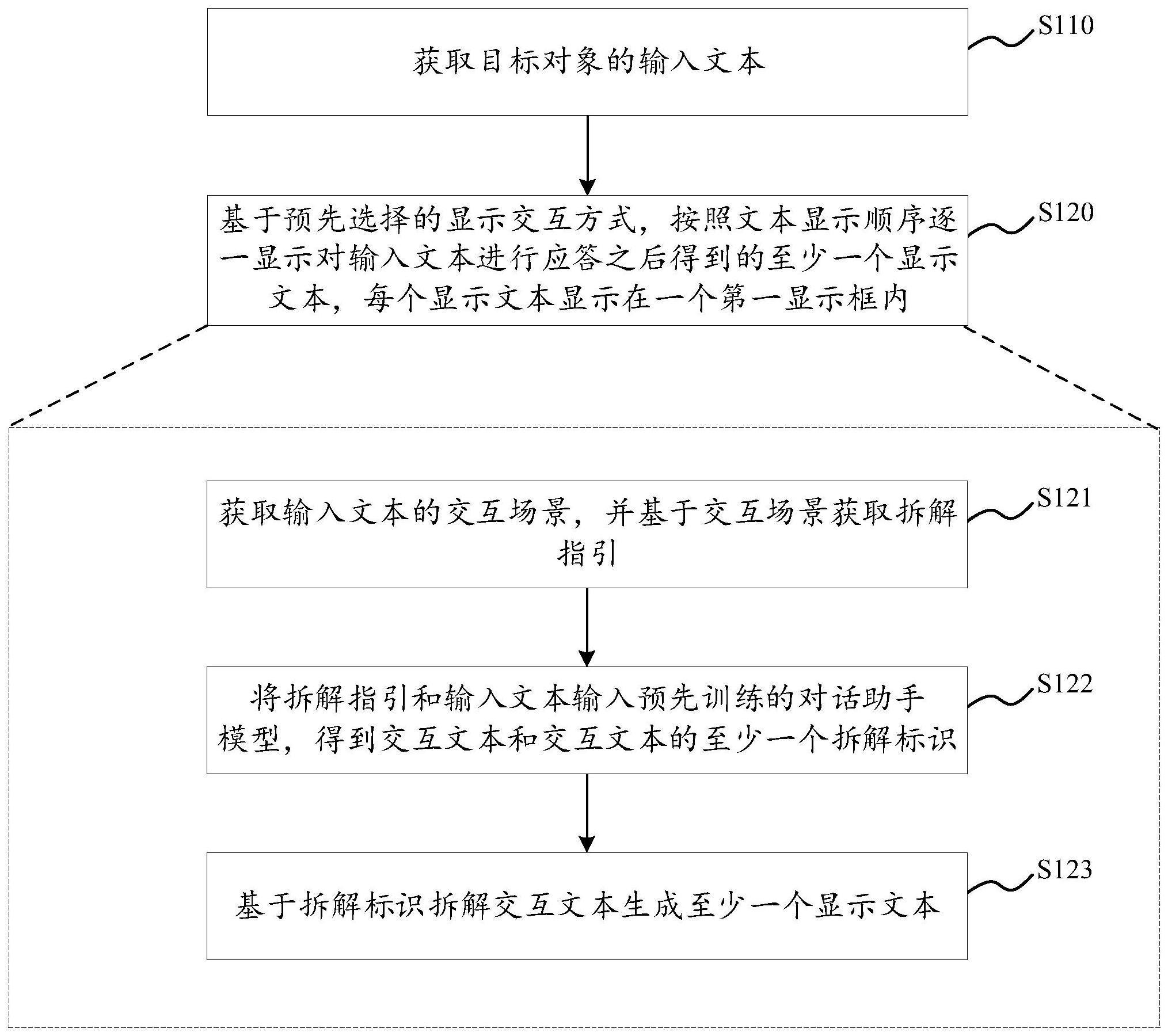
2、为实现上述目的,本技术实施例的第一方面提出了一种对话交互方法,包括:
3、获取目标对象的输入文本;
4、基于预先选择的显示交互方式,按照文本显示顺序逐一显示对所述输入文本进行应答之后得到的至少一个显示文本,每个所述显示文本显示在一个第一显示框内;
5、所述至少一个显示文本通过以下步骤生成:
6、获取所述输入文本的交互场景,并基于所述交互场景获取拆解指引;
7、将所述拆解指引和所述输入文本输入预先训练的对话助手模型,得到交互文本和所述交互文本的至少一个拆解标识;
8、基于所述拆解标识拆解所述交互文本生成至少一个所述显示文本。
9、在一实施例中,所述将所述拆解指引和所述输入文本输入预先训练的对话助手模型,得到交互文本和所述交互文本的至少一个拆解标识,包括:
10、将所述拆解指引和所述输入文本输入预先训练的对话助手模型,得到所述交互文本和拆解位置;
11、根据所述拆解位置生成所述拆解标识。
12、在一实施例中,所述显示交互方式包括:字式交互;所述基于预先选择的显示交互方式,按照文本显示顺序逐一显示对所述输入文本进行应答之后得到的至少一个显示文本,包括:
13、按照所述文本显示顺序获取至少一个第一显示数据;所述第一显示数据为在所述显示文本的预设位置增加与所述显示文本关联的所述拆解标识得到的;
14、将所述第一显示数据作为第一目标数据;
15、若所述预设位置为末位,则在所述第一显示框内按照第一预设字符数量显示所述第一目标数据中所述显示文本,直至检测到所述拆解标识后,生成新的所述第一显示框,并选取下一个所述第一数据组作为所述第一目标数据进行显示;
16、若所述预设位置为首位,则根据检测到的所述拆解标识生成所述第一显示框,在所述第一显示框内按照第一预设字符数量显示所述第一目标数据中所述显示文本,直至到达所述显示文本的最后一个字符,选取下一个所述第一数据组作为所述第一目标数据进行显示。
17、在一实施例中,所述显示交互方式包括:段式交互;所述基于预先选择的显示交互方式,按照文本显示顺序逐一显示对所述输入文本进行应答之后得到的至少一个显示文本,包括:
18、按照所述文本显示顺序获取至少一个第二显示数据;所述第二显示数据为在所述显示文本的预设位置增加与所述显示文本关联的所述拆解标识得到的;
19、将所述第二显示数据作为第二目标数据;
20、若所述预设位置为末位,则在所述第一显示框内显示预设内容,并按照第二预设字符数量获取所述第二目标数据中所述显示文本中字符构成待显示文段,直至检测到所述拆解标识,利用所述待显示文段替换所述预设内容在所述第一显示框内显示,并生成新的所述第一显示框,选取下一个所述第二数据组作为所述第二目标数据组进行显示;
21、若所述预设位置为首位,则根据检测到的所述拆解标识生成所述第一显示框,在所述第一显示框内显示预设内容,并按照第二预设字符数量获取所述第二目标数据中所述显示文本中字符构成待显示文段,直至到达所述显示文本的最后一个字符,利用所述待显示文段替换所述预设内容在所述第一显示框内显示,并生成新的所述第一显示框,选取下一个所述第二数据组作为所述第二目标数据组进行显示。
22、在一实施例中,所述按照文本显示顺序逐一显示对所述输入文本进行应答之后得到的至少一个显示文本之后,所述方法还包括:
23、响应于所述目标对象的聚合指令,生成第二显示框;所述聚合指令包括聚合方式;
24、根据所述聚合方式将所述显示文本进行分组,得到一个或一个以上显示组;所述显示组的数量与所述第二显示框的数量一致;
25、在所述第二显示框内显示所述显示组的内容。
26、在一实施例中,所述对话助手模型通过下述步骤训练得到:
27、构建训练样本集;所述训练样本集包括:多个输入数据样本,所述输入数据样本包括输入数据和拆解指引数据;所述输入数据样本关联样本标签,所述样本标签包括交互数据和拆解标签,所述拆解标签为所述输入数据样本的交互场景对应的拆解位置向量;
28、将所述输入数据样本输入所述对话助手模型进行预测,得到预测交互结果和预测拆解向量;
29、根据所述预测交互结果和所述交互数据得到第一损失值,以及根据所述预测拆解向量和所述拆解标签得到第二损失值;
30、根据所述第一损失值和所述第二损失值计算得到总损失值,并根据所述总损失值调整所述对话助手模型的模型权重,直至迭代结束,得到训练好的所述对话助手模型。
31、在一实施例中,所述拆解指引数据通过下述步骤得到:
32、获取所述输入数据样本的画像数据;所述画像数据根据用户使用数据得到,所述用户使用数据包括历史使用数据和/或当前使用数据;
33、将所述画像数据输入场景分类模型得到交互场景,并根据交互场景得到拆解指引数据。
34、为实现上述目的,本技术实施例的第二方面提出了一种对话交互装置,包括:
35、输入获取模块:用于获取目标对象的输入文本;
36、交互显示模块:用于基于预先选择的显示交互方式,按照文本显示顺序逐一显示对所述输入文本进行应答之后得到的至少一个显示文本,每个所述显示文本显示在一个第一显示框内;
37、所述至少一个显示文本通过以下步骤生成:
38、获取所述输入文本的交互场景,并基于所述交互场景获取拆解指引;
39、将所述拆解指引和所述输入文本输入预先训练的对话助手模型,得到交互文本和所述交互文本的至少一个拆解标识;
40、基于所述拆解标识拆解所述交互文本生成至少一个所述显示文本。
41、为实现上述目的,本技术实施例的第三方面提出了一种电子设备,所述电子设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述第一方面所述的方法。
42、为实现上述目的,本技术实施例的第四方面提出了一种存储介质,所述存储介质为计算机可读存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述第一方面所述的方法。
43、本技术实施例提出的对话交互方法、装置、设备和存储介质,通过获取目标对象的输入文本,基于预先选择的显示交互方式,按照文本显示顺序逐一显示对输入文本进行应答之后得到的至少一个显示文本,每个显示文本显示在一个第一显示框内。其中,显示文本通过以下步骤生成:获取输入文本的拆解指引,将拆解指引和输入文本输入预先训练的对话助手模型,得到交互文本和交互文本的至少一个拆解标识,基于拆解标识拆解交互文本生成至少一个显示文本。本技术实施例结合交互场景得到拆解指引,利用拆解指引对交互文本进行拆解,将拆解得到的显示文本逐一显示在第一显示框内。通过这种方式一方面避免大段文字显示造成的阅读困难问题,按顺序逐步显示拆解后的显示文本,可以引导用户逐步了解应答内容,提高交互文本的可读性,提升用户的理解效率,另一方面利用适应于交互场景的拆解指引对交互文本进行拆解,避免交互文本在不合适的地方产生中断,造成显示文本不连贯的情况,拆解得到的显示文本更合理更流畅,进一步提升交互体验。
- 还没有人留言评论。精彩留言会获得点赞!