一种基于自编码器聚类算法的高校教师评价方法
本发明涉及教育评价领域,具体涉及一种基于自编码器聚类算法的高校教师评价方法。
背景技术:
1、高校教育的发展对于推动社会进步有着有着重要作用,而高校教师的评价在一定程度上决定了高校教育的发展。但由于高校教师“五唯”评价的负面效果愈演愈烈,教师评价导向出现偏差,传统的高校教师评价方法已经很难客观地对高校教师进行评分,这时迫切需要一种可以客观评价高校教师各方面能力的方法。而聚类是一种无监督学习算法,它通过将数据集中相似的数据点划分到同一类别中,形成有意义的簇,从而帮助理解数据集中的潜在结构和模式。评价则是对对象进行质量评估的过程。通过将聚类应用于评价问题中,可以根据聚类结果来评估对象的质量。
2、针对现有的深度自编码器聚类方法,很多学者做了深入的研究。例如guo x等学者(guo x,gao l,liu x,et al.improved deep embedded clustering with localstructure preservation[c]//ijcai.2017:1753-1759.)提出了一种改进的深度自编码器聚类,在损失函数中加入了重构损失,以减小聚类损失对于表示空间的破坏程度。ghasedidizajik等学者(ghasedi dizaji k,herandi a,deng c,et al.deep clustering viajoint convolutional autoencoder embedding and relative entropy minimization[c]//proceedings of the ieee international conference on computervision.2017:5736-5745.)提出了depict算法,融合了子空间的思想,并提出了净前馈自编码器的概念。guo x等学者(guo x,liu x,zhu e,et al.deep clustering withconvolutional autoencoders[c]//neural information processing:24thinternational conference,iconip 2017,guangzhou,china,november 14-18,2017,proceedings,part ii 24.springer international publishing,2017:373-382.)还提出了一种基于跨步卷积层的深度自编码器聚类,以跨步卷积层替代了全连接层,增强了对于高级语义特征的提取能力。mrabah n等学者(mrabah n,khan n m,ksantini r,et al.deepclustering with a dynamic autoencoder:from reconstruction towards centroidsconstruction[j].neural networks,2020,130:206-228.)提出了dynae算法,通过提取特征的置信度分别采取重建或者聚类的方式更好地平衡了重构损失和聚类损失。wickramasinghe c s等学者(wickramasinghe c s,marino d l,manic m.resnetautoencoders for unsupervised feature learning from high-dimensional data:deep models resistant to performance degradation[j].ieee access,2021,9:40511-40520.)将残差块的思想融入了深度自编码器聚类,一定程度上解决了加深深度导致的学习到无用特征和网络退化等问题,使得编码器层数的加深成为可能。cai j等学者(cai j,wang s,guo w.unsupervised embedded feature learning for deep clustering withstacked sparse auto-encoder[j].expert systems with applications,2021,186:115729.)将稀疏自编码器应用到深度自编码器聚类中,使得聚类提取出的特征能够更强烈地反映出各个维度的重要程度。
3、但这些现有的深度聚类算法直接应用在教育评价领域效果不好,主要原因在于教育评价的指标中,评分含有主观性,对真实评分会进行随机偏移,同时高校教师评分数据存在各维度重要性不同的特点。
技术实现思路
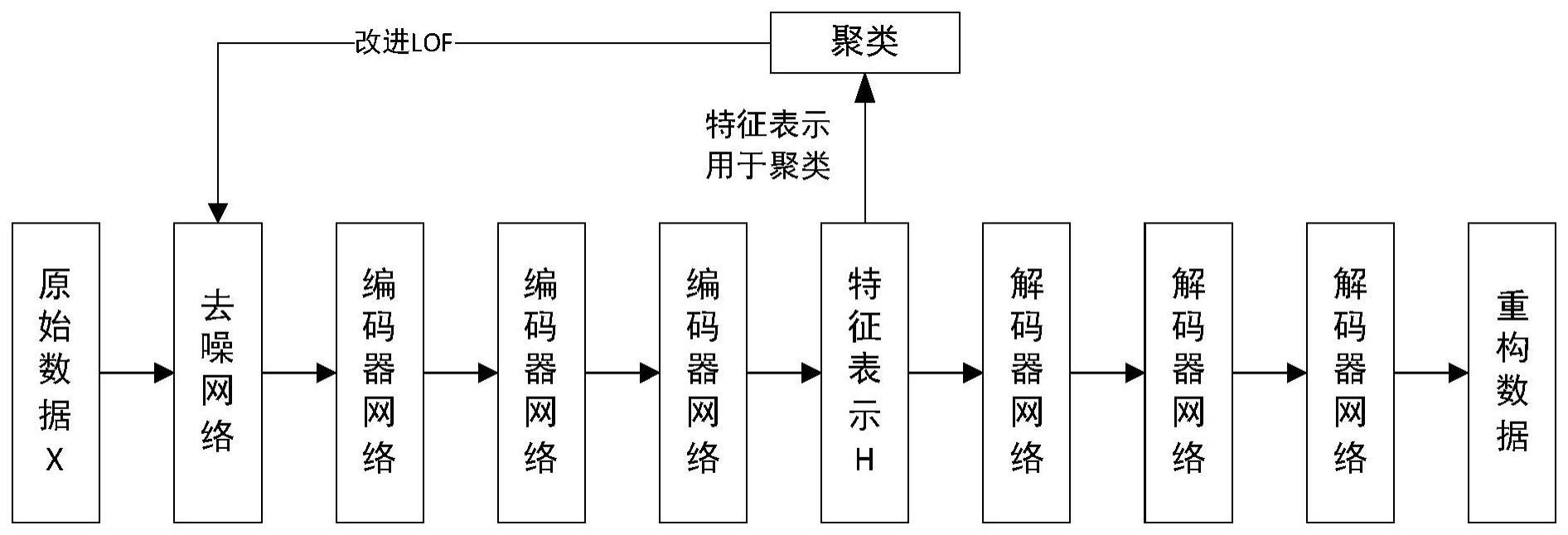
1、为了解决上述技术问题,本发明提出了一种基于自编码器聚类算法的高校教师评价方法,包括以下步骤:
2、s1:输入教师各项评分数据集x,并随机生成噪声向量;以教师各项评分数据集x和噪声向量为输入,以生成器的输出与教师各项评分数据集x的差异构成损失函数进行训练,得到一个用于去噪的生成器;
3、s2:将教师各项评分数据集x输入生成器,得到去噪后的评分数据集x';
4、s3:以去噪后的评分数据集x'为输入,通过dec算法构造编码器网络与解码器网络,计算重构损失,聚类损失;使用重构损失,训练编码器网络与解码器网络,得到数据的低维特征h;
5、s4:使用lof算法,计算低维特征h每个点的局部离群因子;
6、s5:计算去噪损失:将局部离群因子大于1的点都减去1,并累加,作为去噪损失;
7、s6:进行迭代训练,每次训练用去噪损失更新生成器,用聚类损失与重构损失更新编码器网络;
8、s7:达到训练结束条件后,输出聚类结果。
9、进一步的,对s4所述的lof算法进行进一步的改进,改进的lof算法称为dnglof算法;改进之处在于用k()函数,代替lof算法中的第k距离邻域函数nk(),在原始的lof算法中nk(p)指点p的第k距离内的所有点的集合:
10、使用w′作为k()函数的常数,具体的k()函数的定义如下:
11、若数据点o1满足w′o1∈nk(w′p)则o1∈k(p);
12、若数据点o2满足则
13、其中w′为维度重要性权重,具体计算方法如下:
14、根据编码器网络的各层权重w计算低维特征h的原始维度重要性z,其中,zi为原始维度重要性z中第i个元素,具体的,zi的计算公式fodiw_caculate()如下所示:
15、
16、其中,zi表示低维特征h的第i个维度的原始维度重要性,满足zi∈r,编码器网络总共有l层,第l层的维度为dl,表示编码器网络第k-1层的第jk-1个结点和第k层的第jk个结点之间的权重;
17、根据原始维度重要性z进行归一化运算,得到维度重要性权重w′,其中,wi'为维度重要性权重w′的第i个元素,wi'的具体计算方法fdiw_caculate()如下所示:
18、
19、其中,wi'表示低维特征h的第i个维度的维度重要性权重,满足wi'∈[0,1],d为低维特征h的维度数量,zj表示原始维度重要性z中第j个元素。
20、进一步的,在计算聚类损失时首先使用k-means算法对低维特征h进行聚类,作为初始聚类中心。
21、进一步的,在聚类损失和/或重构损失中,加入稀疏约束。
22、进一步的,训练结束条件设置为训练次数达到了预设的迭代次数或者两次迭代的聚类损失偏差小于阈值。
23、有益效果:
24、本发明改进了深度自编码器聚类中的结构,添加了去噪网络用于数据去噪,并提出一种新的衡量去噪能力的算法dnglof用于更好地衡量去噪能力,调整去噪网络的参数。使得数据不再受噪声的影响,编码器能够更好地提取数据的特征,评价更客观,更具有科学性。有利于社会推动高校教育发展,推动基层领域发展。目前国内学者在高校教师评价问题上尚未使用深度自编码器聚类的方法进行研究。本发明还充分考虑了高校教师评分数据存在各维度重要性不同等问题,进一步优化了去噪效果。
25、dnglof算法在计算数据点的邻域时不再局限于以自身为中心的球形,相比传统的lof算法,dnglof额外考虑了维度的重要性,能够更准确地反应数据的去噪情况。而维度重要性权重是通过编码器层与层之间的权重来得到的,编码器将原有的高维数据通过一层层网络压缩成低维特征表示,网络的权重反应了每个维度的重要性。由于每次计算维度重要性权重时需要逐层权重交叉计算,面对深度网络和高维特征时可能存在计算量大的问题,因此本专利选用了稀疏自编码器来提取数据的特征表示。稀疏自编码器引入了稀疏性约束,使得每一层尽可能多的结点输出为0,一方面减小了算法的计算量,另一方面可以更好地体现每个维度的重要程度。
26、本专利提出的算法通过去噪网络可以学习到更复杂的数据分布,从而更好地去除其噪声,以往用于去噪的dropout层则是以一定的概率随机删除神经元,有可能会丢失重要信息或者降低模型的表现。此外,通过dnglof算法衡量数据的异常程度能够使得去噪网络具有更强的表达能力,能够学习到更高阶的特征表示。因此,本专利提出的基于去噪网络的稀疏自编码器聚类算法可以更好地对数据去噪,使其更适合聚类。
- 还没有人留言评论。精彩留言会获得点赞!