一种基于伪标签的半监督小样本目标检测方法与流程
本发明属于计算机视觉领域,具体涉及一种基于伪标签的半监督小样本目标检测方法、系统、装置。
背景技术:
1、随着人工智能技术的快速发展,深度神经网络的表征学习能力日益增强,在大规模标注数据集上训练的目标检测网络取得了良好的检测性能。然而,建立大规模的标注数据集不仅耗时耗力,而且在一些物体类别较多、数据不易获取的情况下,难以构建满足训练要求的样本集,例如服务机器人在家庭、办公等实际环境中,待检测物体种类繁多且外观各异,难以针对所有物品收集数量足够多、具有丰富类内变化的训练样本。因此,如何借助少量标注数据实现对新类目标物体的检测(即小样本目标检测)备受研究人员关注。
2、针对小样本目标检测,国内外研究人员开展了深入的研究,结合元学习或迁移学习等学习策略从少量样本中学习类别代表性特征。其中,基于迁移学习的小样本目标检测方法由于简单有效而被广泛采用,代表性的方法为tfa(two-stage fine-tuningapproach)等。tfa以faster r-cnn目标检测网络为基础,主要由特征提取器、候选区域生成网络rpn(region proposal network)、roi(region of interest)pooling、分类器和回归器组成。tfa将训练过程分为两个阶段:第一阶段首先在一个包含丰富标注数据的基类数据集上进行训练,获得一个通用物体检测器;第二阶段冻结特征提取器、rpn以及roipooling的权重参数,利用少量新类目标物体的标注数据对分类器和回归器进行微调,从而实现对新类目标物体的检测。由于新类目标物体的标注数据少且缺乏类内变化,微调的网络难以从有限的新类目标物体的样本中捕获类别区分性特征,从而容易出现网络对新类适应性较差的问题。实际上,基类数据集中存在大量包含新类目标物体的图像,在这些图像中,新类目标物体未被标注,因而,其在第一阶段训练中被当作背景。如果这些新类目标物体能够被自动标注和学习,将带来网络性能的提升。此时,半监督学习提供了一种有效的解决思路。半监督学习通常采用教师网络和学生网络协同训练,其中教师网络针对无标注新类目标物体产生伪标签,用于进一步训练学生网络,有利于缓解新类标注数据稀缺的问题。
3、为此,本领域技术人员有必要将半监督学习和小样本目标检测方法结合起来,充分挖掘基类数据集中大量的无标注的新类目标物体,以解决在新类目标物体的标注样本有限的情况下新类样本缺乏类内变化,从而影响小样本目标检测性能的问题。
技术实现思路
1、为了解决现有技术中的上述问题,即为了解决在新类目标物体的标注样本有限的情况下新类样本缺乏类内变化,从而影响小样本目标检测性能的问题,本发明提供了一种基于伪标签的半监督小样本目标检测方法,包括:
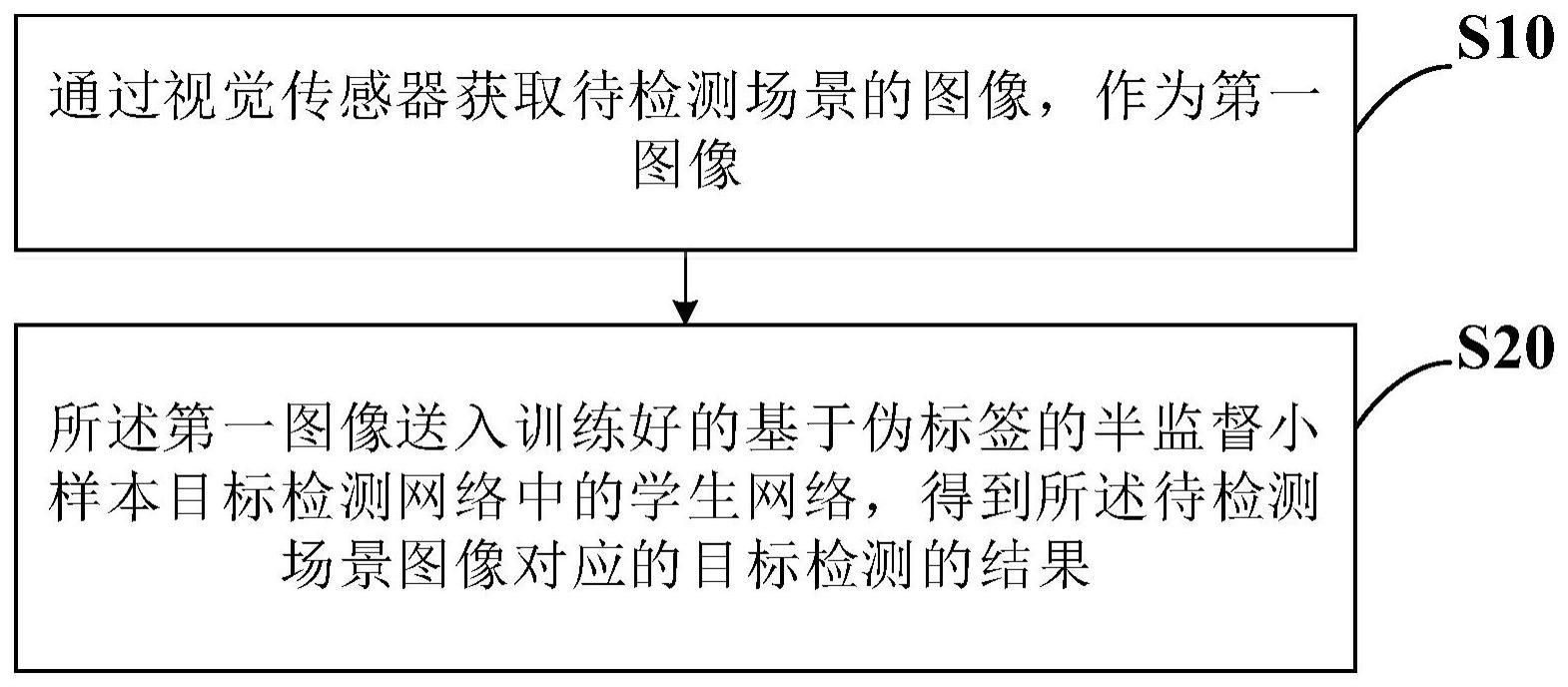
2、步骤s10,通过视觉传感器获取待检测场景的图像,作为第一图像;
3、步骤s20,所述第一图像送入训练好的基于伪标签的半监督小样本目标检测网络中的学生网络,得到所述待检测场景图像对应的目标检测的结果;
4、其中,所述基于伪标签的半监督小样本目标检测网络包括预训练tfa网络、教师网络、学生网络;所述预训练tfa网络、所述教师网络、所述学生网络的网络结构相同。
5、在一些优选的实施方式中,所述学生网络,其训练方法为:
6、步骤a10,获取训练数据,所述训练数据包括无标注训练图像和少量新类标注样本;将所述无标注训练图像输入预训练的tfa网络,得到所述无标注训练图像中新类目标物体的预测结果,作为第一预测结果;所述无标注训练图像为coco数据集的基类数据集中包含新类目标物体的图像;
7、步骤a20,在所述第一预测结果中去掉置信度得分低于设定背景阈值的第一物体候选框,并计算剩余的同类的第一物体候选框在设定分位点的值,作为各新类的初级类别自适应阈值,并将置信度得分高于相应类别的初级类别自适应阈值的第一物体候选框作为第一伪标签;所述第一物体候选框为所述第一预测结果对应的物体候选框;
8、步骤a30,对所述无标注训练图像分别进行弱数据增强和强数据增强处理,得到弱数据增强后的图像、强数据增强后的图像;将所述弱数据增强后的图像输入教师网络,得到所述弱数据增强后的图像中新类目标物体的预测结果,作为第二预测结果;
9、步骤a40,在所述第二预测结果中去掉置信度得分低于设定背景阈值的第二物体候选框,并在剩余的第二物体候选框中,将置信度得分高于相应类别的高级类别自适应阈值的第二物体候选框作为第二伪标签;所述第二物体候选框为所述第二预测结果对应的物体候选框;
10、步骤a50,将所述第一伪标签、所述第二伪标签进行融合,得到第三伪标签;将所述第三伪标签与所述强数据增强后的图像组成新类无标注样本,将所述新类无标注样本以及所述少量新类标注样本输入学生网络,并计算损失值,更新所述学生网络的权重参数,并利用更新后的学生网络的权重参数对教师网络的权重参数进行更新;
11、步骤a60,循环步骤a10-步骤a50,直至得到训练好的学生网络。
12、在一些优选的实施方式中,计算剩余的同类的第一物体候选框在设定分位点的值,其方法为:
13、采用python第三方数据分析工具库pandas库中的分位点函数计算剩余的同类的第一物体候选框在设定分位点的值。
14、在一些优选的实施方式中,在剩余的第二物体候选框中,将置信度得分高于相应类别的高级类别自适应阈值的第二物体候选框作为第二伪标签,其方法为:
15、所述高级类别自适应阈值以所述初级类别自适应阈值初始化,并在训练过程中进行动态调整和更新;动态调整和更新过程如下:
16、记累积n个mini-batch产生的第j个新类的第二伪标签数量为n为累积mini-batch的数量,当计算类别自适应分位点其中,为累积n个mini-batch获得的第j个新类的候选伪标签数量,nmax为最大伪标签数量;
17、当计算类别自适应分位点其中,nmin为最小伪标签数量;在其它情况下,类别自适应分位点保持不变;
18、进而采用python第三方数据分析工具库pandas库中的分位点函数,计算属于同一个新类的置信度得分不低于背景阈值τb的第二物体候选框在类别自适应分位点的值,更新所述高级类别自适应阈值;
19、将所述第二预测结果中置信度得分高于相应类别的高级类别自适应阈值的第二物体候选框作为第二伪标签。
20、在一些优选的实施方式中,将所述第一伪标签、所述第二伪标签进行融合,得到第三伪标签,其方法为:
21、将所述第一伪标签、所述第二伪标签进行合并,并将合并结果作为伪标签候选集;
22、在所述伪标签候选集中,采用非极大值抑制nms将属于同一物体的置信度得分较低的伪标签抑制掉,进而得到标签融合的结果,即第三伪标签;其中,所述伪标签候选集中的两个伪标签属于同一物体的判断标准为它们的类别相同且交并比iou不低于设定交并比阈值。
23、在一些优选的实施方式中,所述学生网络,其在训练过程中的损失函数为:
24、
25、
26、
27、其中,为学生网络在训练时的总损失,为针对新类标注样本的监督损失,为针对新类无标注样本的无监督损失,λu为损失权重超参数,nl和nu分别表示一个mini-batch中新类标注样本和新类无标注样本的数量,表示第k个新类标注样本,表示第k个新类无标注样本,分别表示rpn分类损失、rpn回归损失、roi head分类损失和roi head回归损失。
28、在一些优选的实施方式中,更新所述学生网络的权重参数,并利用更新后的学生网络的权重参数对教师网络的权重参数进行更新,其方法为:
29、
30、θt←αθt+(1-α)θst
31、其中,γ为学习率超参数,α为平滑超参数,θst为学生网络的权重参数,θt表示教师网络的权重参数。
32、本发明的第二方面,提出了一种基于伪标签的半监督小样本目标检测系统,包括:图像采集模块、小样本目标检测模块;
33、所述图像采集模块,配置为通过视觉传感器获取待检测场景的图像,作为第一图像;
34、所述小样本目标检测模块,配置为所述第一图像送入训练好的基于伪标签的半监督小样本目标检测网络中的学生网络,得到所述待检测场景图像对应的目标检测的结果;
35、其中,所述基于伪标签的半监督小样本目标检测网络包括预训练tfa网络、教师网络、学生网络;所述预训练tfa网络、所述教师网络、所述学生网络的网络结构相同。
36、本发明的第三方面,提出了一种存储装置,其中存储有多条程序,所述程序适用于由处理器加载并执行以实现上述的一种基于伪标签的半监督小样本目标检测方法。
37、本发明的第四方面,提出了一种处理装置,包括处理器、存储装置;处理器,适用于执行各条程序;存储装置,适用于存储多条程序;所述程序适用于由处理器加载并执行以实现上述的一种基于伪标签的半监督小样本目标检测方法。
38、本发明的有益效果:
39、本发明能够有效提升小样本目标检测网络对新类物体的适应性,为机器人在家庭服务、办公等领域下的小样本目标检测提供技术支持。
- 还没有人留言评论。精彩留言会获得点赞!