基于超图的标签聚类方法
本发明涉及标签聚类,具体为基于超图的标签聚类方法。
背景技术:
1、数据标签是指为数据样本附加的关键信息或标识,用于描述数据对象的特征、属性或所属类别。标签可以是文本、类别名称或其他形式的符号,具体取决于任务的性质和数据的类型。数据标签能够更准确地描述数据,通过为数据对象进行标签标注,可以使得数据的管理和查询更加高效,提高数据的可用性。
2、然而,在现实环境中,由于个人认知水平的差异,在对同一数据资源进行标注时,不同用户可能倾向于使用不同的词汇、术语或表达方式来描述相同的概念或属性,这导致同一资源可能会被赋予多个不同但含义相近的标签。这种标签的多样性增加了标注结果的复杂性,给数据的管理和应用带来了一定的困难。
3、类似地,不同组织在制定标签体系时也会根据自身的需求和目标做出不同的选择。一些组织可能更关注细粒度的标注,将标签细分为多个层次或细节级别,以捕捉更丰富的信息。而其他组织可能更注重标注的一致性和标准化,将标签设计为更广泛、更一般化的类别,以适应更广泛的应用场景。这导致了不同组织之间标签体系的差异,使得数据在跨组织或跨平台之间的标签一致性变得更加困难。
4、现有的标签聚类方法通常捕获成对标签之间的相关性,忽略了标签之间可能存在更复杂的关系,例如多个标签同时出现的情况。然而,在真实世界中,此类高阶标签关系非常常见,以ms-coco数据集为例,标签“椅子”与“餐桌+杯子”同时出现的概率高达0.45。传统的标签相关性建模方法未考虑到这类高阶标签关系。
技术实现思路
1、本发明的目的在于提供基于超图的标签聚类方法,引入超图结构来建模高阶标签关系,考虑了标签间的复杂关系,使得相关标签的特征表示趋于相似。
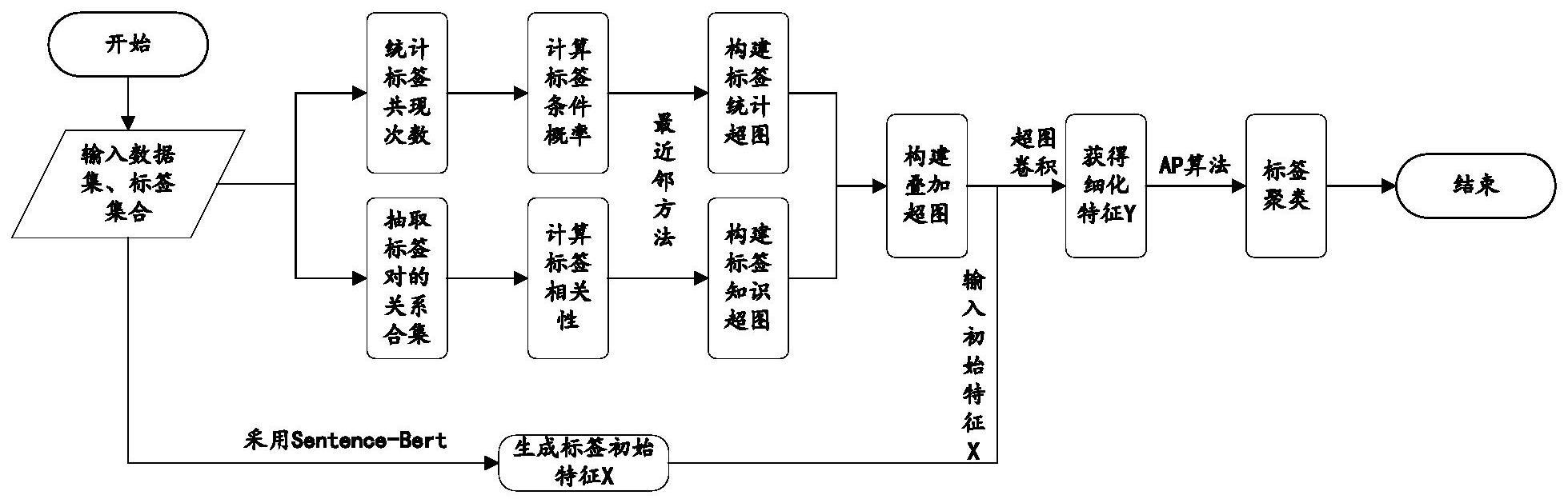
2、为了解决上述技术问题,本发明提供如下技术方案,基于超图的标签聚类方法的步骤为:
3、定义超图g=(v,ε,w),其中v=[vi]表示超图的顶点的集合,ε=[ei]表示超边的集合,n=|v|表示顶点个数,m=|ε|表示超边个数,w=diag(w1,w2,...,wn)为m×m的对角矩阵,主对角线上的元素wi分别表示各个超边的权值,将w初始化为单位矩阵以视为所有超边的权值相同;
4、基于标签数据集,构建标签统计超图,基于先验知识,构建标签知识超图;
5、将标签统计超图和标签知识超图进行叠加得到叠加超图;
6、基于标签数据集,采用bert预训练语言模型生产标签初始特征向量;
7、在叠加超图上对标签初始特征向量进行卷积运算获得新的标签特征表示,将新的特征表示作为聚类算法的输入,从而完成标签聚类。
8、根据上述技术方案,所述标签统计超图构建步骤包括:
9、对标签数据集中的标签对的共现次数进行计数,获得标签共现矩阵m;
10、基于标签共现矩阵m,利用条件概率公式计算标签的条件概率矩阵p;
11、基于标签的条件概率矩阵p,利用最近邻搜索方法构建超图关联矩阵hs,最近邻搜索方法是将每个超边选择一个顶点作为中心,根据共现概率值连接k个最近的邻居,形成一条连接k+1个顶点的超边,由于最近邻搜索方法是以每一个顶点为中心生成一条连接其邻居节点的超边,此时n=m。构建好的超图分别包含n个顶点和n条超边;
12、在标签统计超图hs的基础上添加一个单位矩阵,得到标签统计超图关联矩阵h′s,所述标签统计超图关联矩阵表示标签统计超图结构;
13、其中,条件概率矩阵p∈rn×n,条件概率矩阵p中的元素pij=p(lj|li)表示标签li出现时标签lj出现的概率,i,j=1,2,...,n。
14、根据上述技术方案,所述超图关联矩阵hs表示为:
15、
16、其中,vi表示第i个顶点,i=1,2,...,n,j=1,2,...,m,vj表示第j个顶点的k个最近邻居集合。
17、根据上述技术方案,所述标签知识超图构建步骤为:
18、根据conceptnet知识图谱的api接口来抽取数据集中任意标签对(li,lj)的关系集合,取其中最大的关系标签权值作为两个标签的相关程度的数值体现,数值越大,表示二者关系越紧密,进而构建标签相关性矩阵ak;
19、基于标签相关性矩阵ak,利用最近邻搜索方法构建标签知识超图关联矩阵hk。
20、在上文中采用标签共现计算标签统计超图,但这类统计信息是由数据集中样本的分布决定的,因此由标签共现信息得出的标签相关性可能会受到噪声和干扰的影响,如果存在标签不平衡的情况,则会造成统计偏差,难以完全反映出真实的标签关系,因此借助外部先验知识弥补这一问题,同时也可以获取更全面更准确的标签关系。
21、根据上述技术方案,所述标签相关性矩阵ak表示为:
22、
23、其中,sij是标签i和标签j之间的关系集合,wre表示关系re的权重,|sij|表示集合sij的元素个数。
24、根据上述技术方案,将标签统计超图与标签知识超图的关联矩阵h′s和hk进行连接,形成所述叠加超图关联矩阵h,所述叠加超图关联矩阵h表示为:
25、
26、其中,表示超图关联矩阵的拼接操作,h′s表示标签统计超图关联矩阵,hk表示标签知识超图关联矩阵。
27、根据上述技术方案,所述卷积计算:
28、
29、其中,dv表示顶点的度矩阵,de表示超边的度矩阵,w表示n条超边的权重矩阵,初始值为单位矩阵,x表示顶点的初始特征,y表示经过超图卷积操作后得到的新特征。通过超图卷积运算,可以更好地利用标签高阶相关性进行表示学习。
30、根据上述技术方案,所述聚类算法采用affinitypropagation(ap)聚类算法,affinitypropagation(ap)聚类算法的基本思想是将全部数据点都当作潜在的聚类中心,然后数据点两两之间连线构成一个网络(相似度矩阵),再通过网络中各条边的消息(responsibility和availability)传递计算出各样本的聚类中心。相较于kmeans算法,ap聚类算法适用范围广,不需要事先指定聚类的类别数目k,而且聚类效果稳定。
31、与现有技术相比,本发明所达到的有益效果是:本发明是将标签表示为超图,引入超图结构来建模高阶标签关系,具体通过数据驱动的方式来构建标签相关矩阵,即通过挖掘数据集中的标签共现信息形成基于统计信息的标签超图。此外,为弥补标签共现的不足,提出借助外部知识图谱,形成基于人类先验知识的标签知识超图,将二者叠加,形成叠加超图结构,并将叠加超图通过超图卷积运算得到标签的细化特征,该特征考虑到了标签间的复杂关系,使得相关标签的特征表示趋于相似,有助于提升后续的标签聚类任务的性能,将卷积运算得到标签的细化特征作为聚类算法的输入,从而完成标签聚类,能够对标签数据进行更加精确的划分,提升标签的聚类效果。
技术特征:
1.基于超图的标签聚类方法,将标签视为超图中的顶点,定义超图g=(v,ε,w),其中,v=[vi]表示超图的顶点的集合,ε=[ei]表示超边的集合,n=|v|表示顶点个数,m=|ε|表示超边个数,w=diag(w1,w2,...,wn)为m×m的对角矩阵,主对角线上的元素wi分别表示各个超边的权值,将w初始化为单位矩阵以视为所有超边的权值相同,其特征在于,步骤包括:
2.根据权利要求1所述的基于超图的标签聚类方法,其特征在于,所述标签统计超图构建步骤包括:
3.根据权利要求2所述的基于超图的标签聚类方法,其特征在于,所述超图关联矩阵hs表示为:
4.根据权利要求1所述的基于超图的标签聚类方法,其特征在于,所述标签知识超图构建步骤为:
5.根据权利要求4所述的基于超图的标签聚类方法,其特征在于,所述标签相关性矩阵ak表示为:
6.根据权利要求3所述的基于超图的标签聚类方法,其特征在于,将标签统计超图与标签知识超图的关联矩阵h′s和hk进行连接,形成所述叠加超图关联矩阵h,所述叠加超图关联矩阵表示叠加超图结构,所述叠加超图关联矩阵h表示为:
7.根据权利要求1所述的基于超图的标签聚类方法,其特征在于,所述卷积计算:
8.根据权利要求1所述的基于超图的标签聚类方法,其特征在于,所述聚类算法采用affinitypropagation(ap)聚类算法。
技术总结
本发明公开了基于超图的标签聚类方法,属于标签聚类技术领域。本发明将标签视为超图中的顶点,定义超图G=(V,ε,W),基于标签数据集,构建标签统计超图,基于先验知识,构建标签知识超图;将标签统计超图和标签知识超图进行叠加得到叠加超图;基于标签数据集,采用Bert预训练语言模型生产标签初始特征向量;利用叠加超图对标签初始特征向量进行卷积运算获得新的标签特征表示,将新的特征表示作为聚类算法的输入,从而完成标签聚类。本发明引入超图结构来建模高阶标签关系,考虑了标签间的复杂关系,使得相关标签的特征表示趋于相似,能够对标签数据进行更加精确的划分,提升标签的聚类效果。
技术研发人员:范强,周晓磊,严浩,张骁雄,王芳潇,陆斌,华悦琳
受保护的技术使用者:中国人民解放军国防科技大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!