一种多感官驾驶员情绪识别方法、系统、装置及存储介质与流程
本发明涉及人工智能,尤其是一种多感官驾驶员情绪识别方法、系统、装置及存储介质。
背景技术:
1、在汽车驾驶中,行驶安全最为重要,但大多数的交通事故都是人为因素导致的,而车内人员尤其是驾驶员的情绪则是导致人为交通事故的重要原因。在行车过程中,由于长途的驾驶容易导致驾驶员疲劳困倦,而堵车、糟糕的路况以及其它的车辆的不规范行为也会导致驾驶员产生愤怒、不满等不良情绪,从而影响车辆行驶的安全性。因此有必要对驾驶员的情绪进行识别,以便于及时进行情绪引导,防止可能出现的交通事故。
2、现有技术中,驾驶员的情绪识别一般是通过驾驶员面部表情变化来进行识别,但这种单一维度的情绪识别方式容易受到外界环境的干扰,影响了驾驶员情绪识别的准确性。
技术实现思路
1、本发明的目的在于至少一定程度上解决现有技术中存在的技术问题之一。
2、为此,本发明实施例的一个目的在于提供一种多感官驾驶员情绪识别方法,该方法提高了驾驶员情绪识别的准确性以及车辆行驶的安全性。
3、本发明实施例的另一个目的在于提供一种多感官驾驶员情绪识别系统。
4、为了达到上述技术目的,本发明实施例所采取的技术方案包括:
5、第一方面,本发明实施例提供了一种多感官驾驶员情绪识别方法,包括以下步骤:
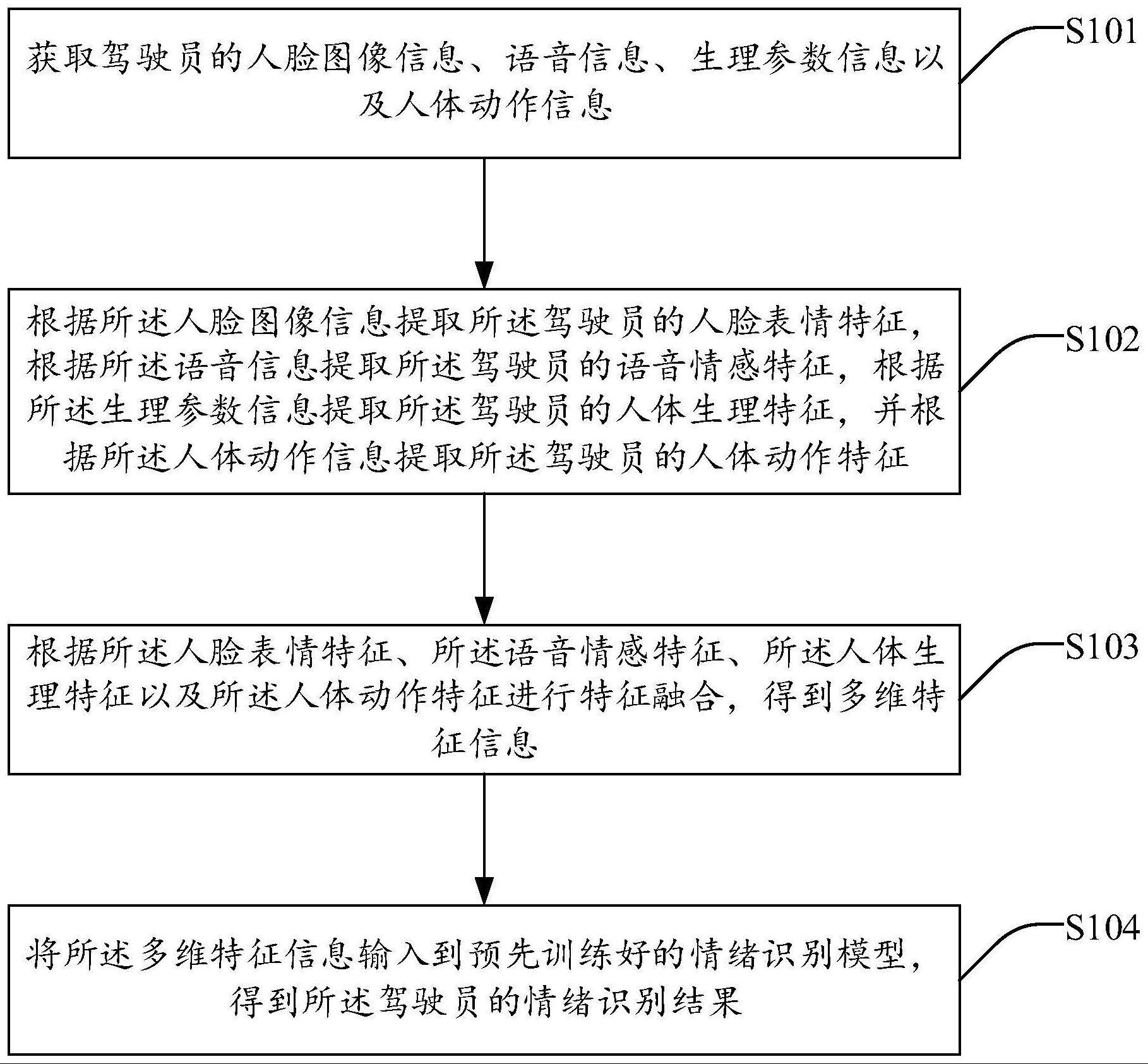
6、获取驾驶员的人脸图像信息、语音信息、生理参数信息以及人体动作信息;
7、根据所述人脸图像信息提取所述驾驶员的人脸表情特征,根据所述语音信息提取所述驾驶员的语音情感特征,根据所述生理参数信息提取所述驾驶员的人体生理特征,并根据所述人体动作信息提取所述驾驶员的人体动作特征;
8、根据所述人脸表情特征、所述语音情感特征、所述人体生理特征以及所述人体动作特征进行特征融合,得到多维特征信息;
9、将所述多维特征信息输入到预先训练好的情绪识别模型,得到所述驾驶员的情绪识别结果。
10、进一步地,在本发明的一个实施例中,所述获取驾驶员的人脸图像信息、语音信息、生理参数信息以及人体动作信息这一步骤,其具体包括:
11、通过设置在目标车辆内的摄像装置获取所述驾驶员的人脸图像信息;
12、通过设置在所述目标车辆内的语音采集装置获取所述驾驶员的语音信息;
13、通过所述驾驶员穿戴的生理探测装置获取所述驾驶员的生理参数信息;
14、通过所述驾驶员穿戴的姿态传感器获取所述驾驶员的人体动作信息。
15、进一步地,在本发明的一个实施例中,所述根据所述人脸图像信息提取所述驾驶员的人脸表情特征,根据所述语音信息提取所述驾驶员的语音情感特征,根据所述生理参数信息提取所述驾驶员的人体生理特征,并根据所述人体动作信息提取所述驾驶员的人体动作特征这一步骤,其具体包括:
16、根据所述人脸图像信息确定多个关键特征区域,并根据所述关键特征区域生成所述人脸表情特征;
17、对所述语音信息依次进行预加重、分帧、加窗、快速傅里叶变换、三角窗滤波、对数运算以及离散余弦变换,得到所述语音信息的梅尔频率倒谱系数,进而根据所述梅尔频率倒谱系数确定所述语音情感特征;
18、根据所述生理参数信息和预设的生理参数阈值确定生理参数增量信息,并根据所述生理参数增量信息生成所述人体生理特征;
19、根据所述人体动作信息确定所述驾驶员的人体动作姿态,并根据所述人体动作姿态生成所述人体动作特征。
20、进一步地,在本发明的一个实施例中,所述根据所述人脸表情特征、所述语音情感特征、所述人体生理特征以及所述人体动作特征进行特征融合,得到多维特征信息这一步骤,其具体包括:
21、根据所述人脸表情特征生成第一特征向量,根据所述语音情感特征生成第二特征向量,根据所述人体生理特征生成第三特征向量,并根据所述人体动作特征生成第四特征向量;
22、对所述第一特征向量、所述第二特征向量、所述第三特征向量以及所述第四特征向量进行向量拼接,得到所述多维特征信息。
23、进一步地,在本发明的一个实施例中,所述多感官驾驶员情绪识别方法还包括预先训练所述情绪识别模型的步骤,其具体包括:
24、获取预设的多个多维特征样本数据,并确定各所述多维特征样本数据的标签信息;
25、根据所述多维特征样本数据和对应的所述标签信息构建训练数据集;
26、将所述训练数据集输入到预先构建的卷积神经网络进行训练,得到训练好的所述情绪识别模型;
27、其中,所述多维特征样本数据根据测试人员的人脸图像样本数据、语音样本数据、生理参数样本数据以及人体动作样本数据生成。
28、进一步地,在本发明的一个实施例中,所述将所述训练数据集输入到预先构建的卷积神经网络进行训练,得到训练好的所述情绪识别模型这一步骤,其具体包括:
29、将所述训练数据集输入到所述卷积神经网络,得到情绪预测结果;
30、根据所述情绪预测结果和所述标签信息确定所述卷积神经网络的损失值;
31、根据所述损失值通过反向传播算法更新所述卷积神经网络的模型参数,并返回将所述训练数据集输入到所述卷积神经网络这一步骤;
32、当所述损失值达到预设的第一阈值或迭代次数达到预设的第二阈值,停止训练,得到训练好的所述情绪识别模型。
33、进一步地,在本发明的一个实施例中,所述多感官驾驶员情绪识别方法还包括以下步骤:
34、根据所述情绪识别结果预测所述驾驶员是否存在驾驶风险,当存在驾驶风险,通过语音提醒装置播放预设的情绪引导内容对所述驾驶员进行情绪引导。
35、第二方面,本发明实施例提供了一种多感官驾驶员情绪识别系统,包括:
36、信息获取模块,用于获取驾驶员的人脸图像信息、语音信息、生理参数信息以及人体动作信息;
37、特征提取模块,用于根据所述人脸图像信息提取所述驾驶员的人脸表情特征,根据所述语音信息提取所述驾驶员的语音情感特征,根据所述生理参数信息提取所述驾驶员的人体生理特征,并根据所述人体动作信息提取所述驾驶员的人体动作特征;
38、特征融合模块,用于根据所述人脸表情特征、所述语音情感特征、所述人体生理特征以及所述人体动作特征进行特征融合,得到多维特征信息;
39、情绪识别模块,用于将所述多维特征信息输入到预先训练好的情绪识别模型,得到所述驾驶员的情绪识别结果。
40、第三方面,本发明实施例提供了一种多感官驾驶员情绪识别装置,包括:
41、至少一个处理器;
42、至少一个存储器,用于存储至少一个程序;
43、当所述至少一个程序被所述至少一个处理器执行时,使得所述至少一个处理器实现上述的一种多感官驾驶员情绪识别方法。
44、第四方面,本发明实施例还提供了一种计算机可读存储介质,其中存储有处理器可执行的程序,所述处理器可执行的程序在由处理器执行时用于执行上述的一种多感官驾驶员情绪识别方法。
45、本发明的优点和有益效果将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到:
46、本发明实施例获取驾驶员的人脸图像信息、语音信息、生理参数信息以及人体动作信息,根据人脸图像信息提取驾驶员的人脸表情特征,根据语音信息提取驾驶员的语音情感特征,根据生理参数信息提取驾驶员的人体生理特征,并根据人体动作信息提取驾驶员的人体动作特征,然后根据人脸表情特征、语音情感特征、人体生理特征以及人体动作特征进行特征融合,得到多维特征信息,再将多维特征信息输入到预先训练好的情绪识别模型,得到驾驶员的情绪识别结果。本发明实施例基于人脸图像信息、语音信息、生理参数信息以及人体动作信息这四个维度进行特征提取和特征融合,得到多维特征信息并通过情绪识别模型对驾驶员情绪进行识别,克服了单一维度的特征容易受到外界环境影响的缺陷,提高了驾驶员情绪识别的准确性,从而提高了车辆行驶的安全性。
- 还没有人留言评论。精彩留言会获得点赞!