基于门控渐进式神经网络的计算制导方法
本发明涉及一种基于门控渐进式神经网络的计算制导方法,属于制导。
背景技术:
1、计算制导主要可以划分为两类:基于模型的计算制导和基于数据的计算制导。
2、其中,基于模型的计算制导方法是根据导弹飞行动力学和制导律等数学模型,通过优化算法寻找最优解的制导方法。但是这种方法需要准确的模型,在实际情况中,由于飞行环境、目标动态等因素的影响,飞行器飞行的真实模型往往很难获取。基于数据的计算制导方法则是通过学习大量的历史数据,从中提取有用的信息并进行决策。这类方法的优点是不需要准确的模型,而且能够处理模型复杂或者不确定的情况。例如,深度学习等机器学习方法就是基于数据的计算制导的代表。这种方法通过训练大量数据,可以学习到制导过程中的复杂模式,并进行有效决策。
3、然而当任务环境发生改变时,预训练好的制导模型表现并不理想。为获得适用于新制导任务环境中的制导模型,需要大量的数据和时间成本,这在实际应用中是不现实的。
4、现有技术中有将渐进式神经网络替代传统神经网络进行增量学习,通过增加列网络的方法,使得新制导任务的学习过程中不会忘记旧的制导任务,从而降低新环境制导任务训练数据量,实现在新环境中的精准制导,但是将渐进式神经网络中特殊的横向连接方式会造成网络参数随着任务数的增多而爆炸式增长的现象,从而导致适应后续任务的时间成本陡增。
5、因此,有必要对现有的基于数据的计算制导方法进一步研究,以解决上述问题。
技术实现思路
1、为了克服上述问题,本发明人进行了深入研究,提供了一种基于门控渐进式神经网络的计算制导方法,包括以下步骤:
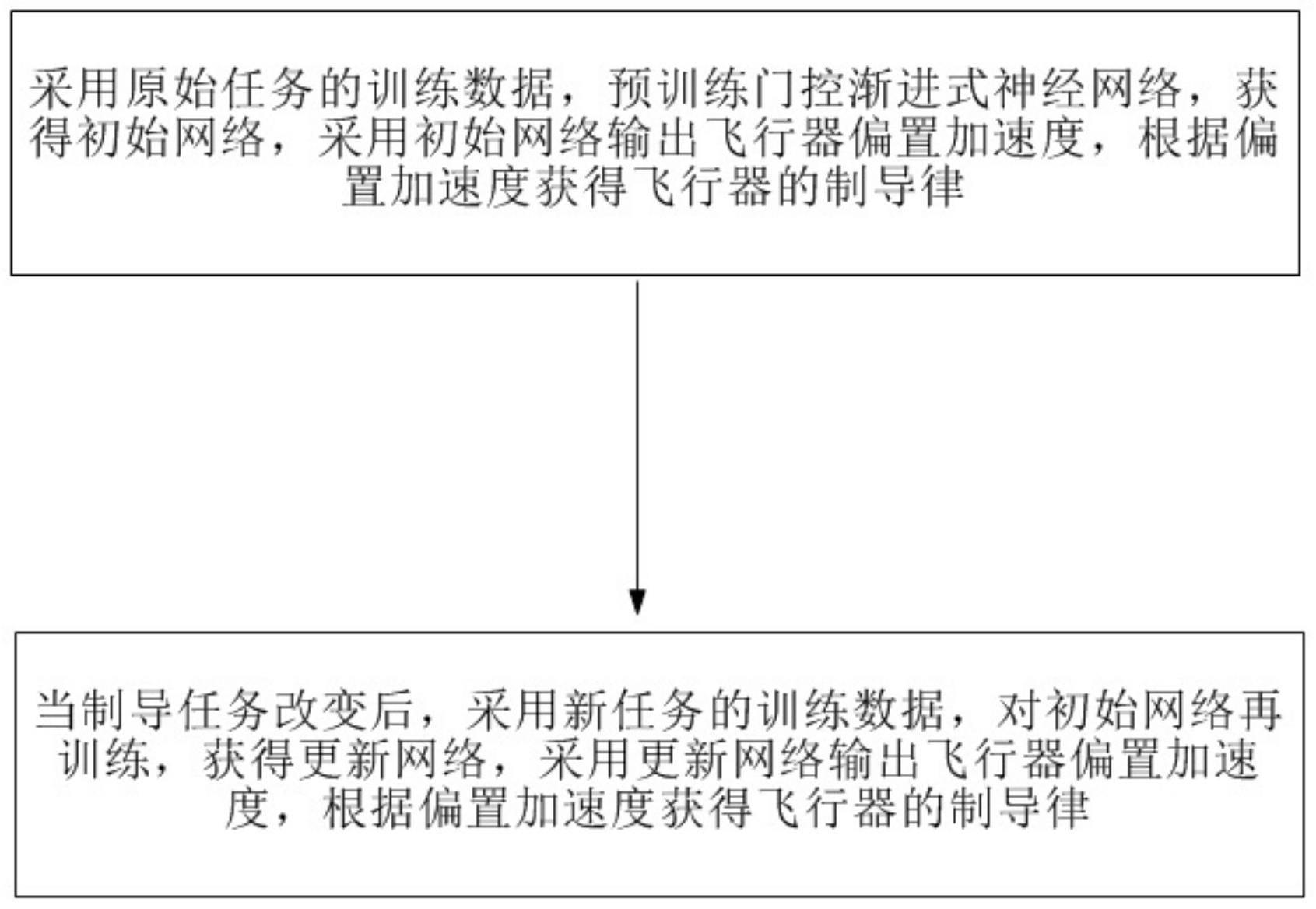
2、采用原始任务的训练数据,预训练门控渐进式神经网络,获得初始网络,采用初始网络输出飞行器偏置加速度,根据偏置加速度获得飞行器的制导律;
3、当制导任务改变后,采用新任务的训练数据,对初始网络再训练,获得更新网络,采用更新网络输出飞行器偏置加速度,根据偏置加速度获得飞行器的制导律。
4、在一个优选的实施方式中,所述门控渐进式神经网络,包括一列或多列任务单元,每个列任务单元均具有一个输入层、一个或多个隐含层、一个输出层;不同列任务单元之间具有横向连接。
5、在一个优选的实施方式中,所述再训练包括以下步骤:
6、在初始网络中增加新列任务单元,在新列任务单元与旧列任务单元之间建立横向连接,形成新的渐进式神经网络;
7、采用新任务的训练数据训练新的渐进式神经网络,获得更新网络。
8、在一个优选的实施方式中,所述新列任务单元输入层的输入,包含神经网络输入数据以及所有旧列任务单元输出层的输出量。
9、在一个优选的实施方式中,在新列任务单元输入层的输入中,为旧列任务单元输出层的输出量设置有权重参数。
10、在一个优选的实施方式中,所述权重参数为自适应参数。
11、在一个优选的实施方式中,再训练过程中,旧任务单元中的参数冻结。
12、在一个优选的实施方式中,所述训练数据包括飞行器的飞行状态量和制导律,其中飞行状态量为神经网络的输入量,飞行器偏置加速度为神经网络的输出量。
13、在一个优选的实施方式中,再训练过程中,采用均方误差作为训练新列的损失函数
14、在一个优选的实施方式中,所述训练数据通过以下方式获取:
15、建立飞行器的动力学模型;
16、设置最优控制目标,根据动力学模型获得多组飞行器飞行状态量及对应的飞行器偏置加速度。
17、本发明所具有的有益效果包括:
18、(1)简化了pnn网络,避免由任务增加引起的网络参数的爆炸性增长,降低了训练对运算量的需求;
19、(2)提出了一种门控机制来促进知识转移,以缓解由于网络简化而导致的不同任务之间的知识转移的弱点;
20、(3)制导方法能够在新数据较少的情况下快速适应新的空气动力学环境,能迅速适应新环境下的任务需求,相比传统深度学习制导节省了大量时间成本,极大地提高了制导律的部署效率。
技术特征:
1.一种基于门控渐进式神经网络的计算制导方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于门控渐进式神经网络的计算制导方法,其特征在于,
3.根据权利要求1所述的基于门控渐进式神经网络的计算制导方法,其特征在于,
4.根据权利要求3所述的基于门控渐进式神经网络的计算制导方法,其特征在于,
5.根据权利要求4所述的基于门控渐进式神经网络的计算制导方法,其特征在于,
6.根据权利要求5所述的基于门控渐进式神经网络的计算制导方法,其特征在于,
7.根据权利要求1所述的基于门控渐进式神经网络的计算制导方法,其特征在于,
8.根据权利要求1所述的基于门控渐进式神经网络的计算制导方法,其特征在于,
9.根据权利要求1所述的基于门控渐进式神经网络的计算制导方法,其特征在于,
10.根据权利要求1所述的基于门控渐进式神经网络的计算制导方法,其特征在于,
技术总结
本发明公开了一种基于门控渐进式神经网络的计算制导方法,包括以下步骤:采用原始任务的训练数据,预训练门控渐进式神经网络,获得初始网络,采用初始网络输出飞行器偏置加速度,根据偏置加速度获得飞行器的制导律;当制导任务改变后,采用新任务的训练数据,对初始网络再训练,获得更新网络,采用更新网络输出飞行器偏置加速度,根据偏置加速度获得飞行器的制导律。本发明公开的基于门控渐进式神经网络的计算制导方法,能够在新数据较少的情况下快速适应新的任务环境,且避免由任务增加引起的网络参数的爆炸性增长,降低了训练运算量。
技术研发人员:何绍溟,罗皓文,金天宇,侯利兵,巩庆海
受保护的技术使用者:北京理工大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!