一种基于卷积神经网络的模型训练方法及应用系统与流程
本发明涉及人工智能,特别涉及一种基于卷积神经网络的模型训练方法及应用系统。
背景技术:
1、利用人工智能和大数据技术,通过自动化和智能化的方式实现了对大量数据的监控和反馈,为各行各业带来了低成本的解决方案。然而,为了保持系统的高效运行,实现高精确度的数据分析和处理需要不断对算法和模型进行优化。
技术实现思路
1、本发明提供一种基于卷积神经网络的模型训练方法及应用系统,通过对网络模型的训练和优化,将该模型应用于大数据监控的系统,提高了数据监控的效率和精确度。
2、根据本公开的一方面,提供了一种基于卷积神经网络的模型训练方法,其特征在于,所述方法包括:
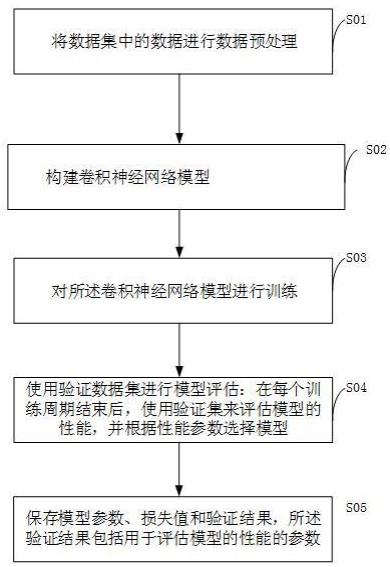
3、将数据集中的数据进行数据预处理;
4、构建卷积神经网络模型;
5、对所述卷积神经网络模型进行训练,包括:
6、定义损失函数,选择优化器,所述优化器用于更新所述模型的参数使得损失函数的值最小化,将数据集划分为训练数据集和测试数据集,将训练集分成小批量数据,通过前向传播计算损失函数的值,然后进行反向传播更新梯度,优化所述模型的参数;
7、使用验证数据集进行模型评估:在每个训练周期结束后,使用验证集来评估模型的性能,并根据性能参数选择模型;
8、保存模型参数、损失值和验证结果,所述验证结果包括用于评估模型的性能的参数。
9、在一种可能的实现方式中,所述对所述卷积神经网络模型进行训练,还包括:通过对卷积神经网络模型的测试,调整所述模型的深度,所述模型的深度包括所述模型的层数。
10、在一种可能的实现方式中,所述对所述卷积神经网络模型进行训练,还包括:通过对卷积神经网络模型的测试,调整批归一化层的数量和位置;
11、通过对卷积神经网络模型的测试,调整学习率大小,所述学习率的大小会直接影响模型的训练速度和收敛效果。
12、在一种可能的实现方式中,所述对所述卷积神经网络模型进行训练,还包括:对所述测试数据集进行数据增强处理,所述数据增强处理包括旋转、翻转、裁剪;
13、在损失函数后增加l1正则化项或l2正则化项,用于限制所述模型参数的大小,防止过拟合。
14、在一种可能的实现方式中,所述将数据集中的数据进行数据预处理,包括:
15、将数据集进行分组得到多个数据组;
16、计算每个数据组中的数据的中位数;
17、遍历所述数据集,判断每个数据是否是缺失值,包括:根据每个数据组对应的中位数,遍历所述数据组,判断数据组中每个数据是否是缺失值;
18、在数据是缺失值的情况下,用数据组对应的中位数代替所述缺失值。
19、在一种可能的实现方式中,所述将数据集中的数据进行数据预处理,包括:
20、根据数据集中的数据的分布情况,将数据集中的数据乘以大小不同的权重,得到新数据集;计算新数据集中的数据的中位数;
21、遍历所述新数据集,判断每个数据是否是缺失值。
22、在一种可能的实现方式中,所述将数据集中的数据进行数据预处理,包括:
23、遍历数据集中的缺失数据的各个位置;
24、根据k最邻近算法预测数据集中的各个位置的预测缺失值;
25、将所述测缺失值填充到对应的位置。
26、在一种可能的实现方式中,所述将数据集中的数据进行数据预处理,包括:
27、根据数据集的大小,确定插值窗口的大小,所述插值窗口用于确定与缺失数据的点相邻的数据点;
28、计算插值窗口内的每个数据点与所述缺失数据的点之间的距离;
29、根据所述距离确定对应的权重值;
30、将所述插值窗口内的每个数据点乘以对应的权重之后计算加权和;
31、将所述加权和除以所有权重的和,得到加权中位数;
32、将所述加权中位数填充至缺失数据的点。
33、在一种可能的实现方式中,构建卷积神经网络模型,包括:
34、定义卷积层:使用卷积核进行特征提取,通过多个卷积核提取不同特征;
35、定义池化层:用于降低特征图的尺寸;
36、添加批归一化层:将数据转换至[0,1]或[-1,1]之间的范围;
37、添加激活函数:用于引入非线性特征;
38、展平操作:将最后一个池化层的输出展平成一维向量;
39、添加全连接层:用于将卷积层提取的特征映射到目标标签空间;
40、输出层:使用归一化指数函数输出分类概率。
41、根据本公开的另一方面,提出了一种基于数据监控的自动反馈识别应用系统,所述系统包括收发器,存储器,显示装置,处理器;处理器分别于所述收发器,存储器及显示装置连接,配置为执行存储器上的计算机可执行指令,控制所述收发器的数据接收和发送,并实现权利要求1-9任一项所述的卷积神经网络的模型;所述收发器用于接收待监控的数据,以及将所述处理器的识别结果发送至显示装置。
42、与现有技术相比,本发明的有益效果是:
43、通过本公开实施例的基于卷积神经网络的模型训练方法,不断对构建的卷积数据网络模型进行优化,不断对算法进行优化以及对模型的参数进行修改进而进行训练实现高精确度的数据分析和处理。在该模型成熟后,就可以进行随后的产业化开发了,比如将该模型进行接口封装,供使用者调用。
44、在基于数据监控的自动反馈识别应用系统中,人工智能和大数据技术发挥着重要作用。通过大数据技术,系统可以收集、存储和处理来自多个来源的大量数据,包括实时数据流、历史数据等。这些数据可以来自传感器、用户行为、设备输出等。然后,人工智能技术可以通过分析这些数据来识别模式、发现异常、预测未来情况等。通过机器学习和深度学习等技术,系统可以逐步改进自己的表现,并在处理复杂任务时变得越来越精准。
45、经济性:该系统相对于传统的人工监控和反馈方法,具有明显的经济优势。传统上,为了实现有效的数据监控和反馈,往往需要大量的人力资源,例如专业人员对数据进行实时监控和分析。这不仅需要高额的薪资开支,还可能因人为因素导致错误和延迟。而基于数据监控的自动反馈识别系统,则可以通过自动化和智能化的方式,大大降低运营成本。一旦建立和部署,系统可以自动处理数据,减少对人力的依赖,从而提高效率并节省资源。
46、精确度:尽管追求经济性很重要,但系统的精确度也是至关重要的。如果系统的识别能力不足,误报和漏报可能会导致严重后果。因此,在设计该系统时,需要充分考虑如何在经济性和精确度之间取得平衡。系统可以通过不断学习和改进来提高自己的精确度,确保能够准确地识别各种情况,并在必要时发出及时反馈。
47、中位数填充的优点是不会引入过多的噪声,因为中位数比均值更加鲁棒,对异常值不敏感。同时,中位数填充可以保留原始数据的分布特征,不会改变数据的整体形态。
技术特征:
1.一种基于卷积神经网络的模型训练方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于卷积神经网络的模型训练方法,其特征在于,所述对所述卷积神经网络模型进行训练,还包括:通过对卷积神经网络模型的测试,调整所述模型的深度,所述模型的深度包括所述模型的层数。
3.根据权利要求1所述的基于卷积神经网络的模型训练方法,其特征在于,所述对所述卷积神经网络模型进行训练,还包括:通过对卷积神经网络模型的测试,调整批归一化层的数量和位置;
4.根据权利要求1所述的基于卷积神经网络的模型训练方法,其特征在于,所述对所述卷积神经网络模型进行训练,还包括:对所述测试数据集进行数据增强处理,所述数据增强处理包括旋转、翻转、裁剪;
5.根据权利要求1所述的基于卷积神经网络的模型训练方法,其特征在于,所述将数据集中的数据进行数据预处理,包括:
6.根据权利要求1所述的基于卷积神经网络的模型训练方法,其特征在于,所述将数据集中的数据进行数据预处理,包括:
7.根据权利要求1所述的基于卷积神经网络的模型训练方法,其特征在于,所述将数据集中的数据进行数据预处理,包括:
8.根据权利要求1所述的基于卷积神经网络的模型训练方法,其特征在于,所述将数据集中的数据进行数据预处理,包括:
9.根据权利要求1所述的基于卷积神经网络的模型训练方法,其特征在于,构建卷积神经网络模型,包括:
10.一种基于数据监控的自动反馈识别应用系统,所述系统包括收发器,存储器,显示装置,处理器;处理器分别于所述收发器,存储器及显示装置连接,配置为执行存储器上的计算机可执行指令,控制所述收发器的数据接收和发送,并实现权利要求1-9任一项所述的卷积神经网络的模型;所述收发器用于接收待监控的数据,以及将所述处理器的识别结果发送至显示装置。
技术总结
本发明公开了一种基于卷积神经网络的模型训练方法及应用系统,涉及人工智能技术领域,包括:将数据集中的数据进行数据预处理;构建卷积神经网络模型;对所述卷积神经网络模型进行训练;使用验证数据集进行模型评估:在每个训练周期结束后,使用验证集来评估模型的性能,并根据性能参数选择模型;保存模型参数、损失值和验证结果,所述验证结果包括用于评估模型的性能的参数。通过对网络模型的训练和优化,将该模型应用于大数据监控的系统,提高了数据监控的效率和精确度。
技术研发人员:刘继前,张朋,杨训,刘松,石志康,吕仲恒
受保护的技术使用者:安徽航辰信息科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!