一种基于模糊跨度机制的通用信息抽取模型生成方法
本发明涉及信息抽取,特别涉及一种基于模糊跨度机制的通用信息抽取模型生成方法。
背景技术:
1、信息提取(information extraction,ie)主要指从非结构化文本源中提取预先设定的结构化信息类型,如命名实体识别(named entity recognition,ner)、关系提取(relation extraction,re)和情感提取(sentiment extraction,se)等。现有方法在ie任务上做出的尝试包括基于既定规则的抽取模型一、基于机器学习的抽取模型二、基于深度学习的抽取模型三等。然而,由于信息抽取子任务种类多样,抽取目标繁杂,因此针对具体抽取任务和抽取目标类别分别设计并训练不同的模型结构将带来巨大的资源浪费和有限的应用场景。因此,为信息抽取任务进行统一建模和模型设计对于提升信息抽取效率至关重要。
2、通用信息抽取(universal information extraction,uie)旨在使用一个统一的框架对各种ie任务进行一致建模,重点是构建能够适应不同数据源、不同类型标签、不同语言和不同任务的模型结构,从而避免针对不同ie子任务分别设计和训练模型带来的资源消耗。现有工作中已经提出了一些生成式通用信息提取模型,并在各种ie数据集和基准上取得了广泛的成功。
3、尽管如此,通用信息抽取模型仍有局限性。例如,它们在训练期间严重依赖数据中的跨度边界的精确位置,这存储无法反映基于跨度的抽取任务的现实情况,即对边界位置的轻微调整也能满足要求。此外,通用信息抽取模型缺乏对信息抽取任务中有限的跨度长度特征的关注,造成了注意力的不合理分配。
4、综上所述,如何改进通用信息抽取模型,使得其更加符合信息抽取任务的实际需求成为一个亟待解决的问题。
技术实现思路
1、为了解决现有技术中存在的问题,本技术实施例提供一种基于模糊跨度机制的通用信息抽取方法,使用模糊跨度机制通用信息抽取(fuzzy span universal informationextraction,fsuie)模型将信息抽取任务中抽取目标的边界和注意力机制的范围模糊化,使得模型更加切合信息抽取任务的实际情况。
2、第一方面,提供了一种基于模糊跨度机制的通用信息抽取模型生成方法,包括:
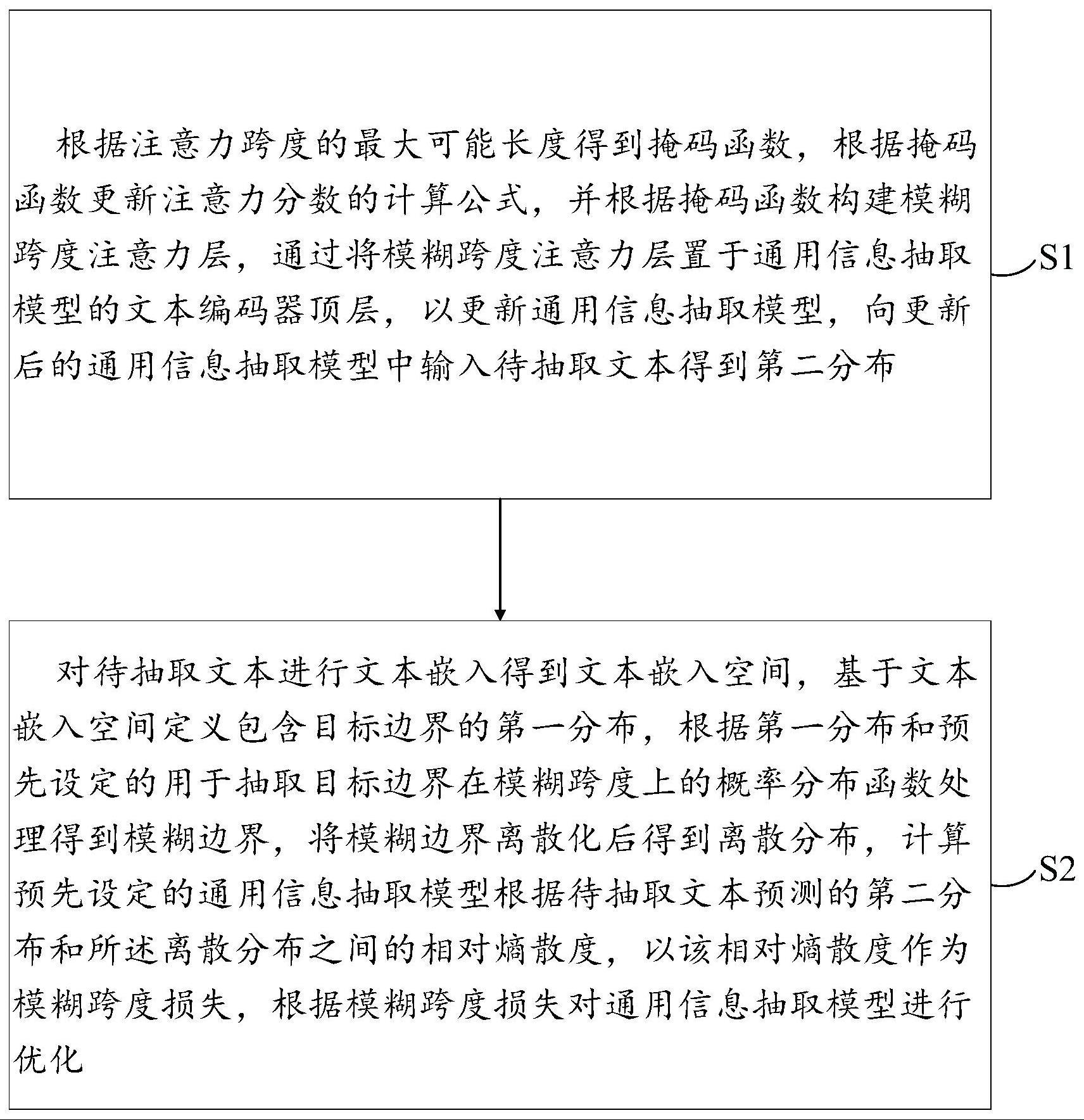
3、根据注意力跨度的最大可能长度得到掩码函数,根据掩码函数更新注意力分数的计算公式,并根据掩码函数构建模糊跨度注意力层,通过将模糊跨度注意力层置于通用信息抽取模型的文本编码器顶层,以更新通用信息抽取模型,向更新后的通用信息抽取模型中输入待抽取文本得到第二分布;
4、对待抽取文本进行文本嵌入得到文本嵌入空间,基于文本嵌入空间定义包含目标边界的第一分布,根据第一分布和预先设定的用于抽取目标边界在模糊跨度上的概率分布函数处理得到模糊边界,将模糊边界离散化后得到离散分布,计算预先设定的通用信息抽取模型根据待抽取文本预测的第二分布和所述离散分布之间的相对熵散度,以该相对熵散度作为模糊跨度损失,根据模糊跨度损失对通用信息抽取模型进行优化。
5、一些实施例中,所述最大可能长度基于第一中间参数计算得到,所述中间参数采用下述公式计算得到:
6、
7、其中,
8、ga用于表示第一中间参数;
9、z用于表示序列中参与注意力分数计算的两个词向量的相对距离;
10、l用于表示完整注意力的区间长度;
11、δ用于表示可学习参数,δ∈[0,1];
12、lspan用于表示最大可能长度;
13、d用于表示预先设定参数。
14、一些实施例中,所述最大可能长度采用下述公式计算得到:
15、
16、其中,
17、gm用于表示计算参与更新相对距离为z的两个词向量之间注意力的参数的函数;
18、gm(z)用于表示参与更新相对距离为z的两个词向量之间注意力分数的参数;
19、ga(z)用于表示相对距离为z的两个词向量之间的第一中间参数。
20、一些实施例中,所述更新后注意力分数的计算公式如下:
21、
22、其中,
23、atr用于表示注意力分数;
24、t用于表示词向量的坐标,t为正整数;
25、r用于表示词向量的坐标,r为正整数;
26、str用于表示第t个词向量对第r个词向量的相似度;
27、q用于表示位于第t个词向量之前,与第t个词向量相对距离小于lspan的所有词向量的坐标;
28、lspan用于表示注意力分布的最大可能长度;
29、exp(stq)用于表示第t个词向量和第q个词向量之间的相似度得分。
30、一些实施例中,所述用于抽取目标边界在模糊跨度上的概率分布函数采用高斯函数。
31、一些实施例中,所述模糊边界采用下述公式计算得到:
32、
33、其中,
34、q用于表示第一分布;
35、rmin用于表示模糊范围的起点位置;
36、rmax用于表示模糊范围的终点位置;
37、x用于表示模糊范围内的边界坐标;
38、q(x)用于表示坐标x上分布的边界概率;
39、s用于表示抽取目标的边界集合。
40、一些实施例中,所述将模糊边界离散化后得到离散分布,具体包括如下步骤:
41、基于第二中间参数,通过对连续分布按照相同的间隔取值,将模糊边界的连续概率分布映射为一组离散分布。
42、一些实施例中,所述第二中间参数采用下述公式计算得到:
43、∈=q(μ+(i-g)s)
44、其中,
45、∈用于表示第二中间参数;
46、q用于表示高斯分布的概率密度函数;
47、μ用于表示高斯分布的均值;
48、i用于表示当前词向量的位置坐标;
49、g用于表示抽取目标边界的准确边界坐标;
50、s用于表示间隔取样的间隔长度。
51、一些实施例中,所述离散分布为
52、所述f(qi)采用下述公式计算得到:
53、
54、其中,
55、f(qi)用于表示位置qi上分布的边界概率;
56、θ用于表示取样阈值。
57、一些实施例中,所述根据模糊跨度损失对通用信息抽取模型进行优化,具体包括如下步骤:
58、计算第二分布和目标边界的二元交叉熵,以该二元交叉熵作为通用信息抽取模型的二元交叉熵损失;
59、将模糊跨度损失和二元交叉熵损失加权求和得到通用信息抽取模型的最终损失;
60、根据最终损失对通用信息抽取模型进行优化。
61、本技术提供的技术方案带来的有益效果包括:
62、(1)本发明针对现有数据标注的局限性做出改进,提出的模糊跨度机制更好地契合了信息抽取任务的实际情况,从而带来更好的抽取效果。
63、(2)本发明提出的模糊跨度损失不引入额外的子模块,在增加较少计算量的情况下取得更好的效果,内容直观,且具有较好的扩展性。
64、(3)本发明提出的模糊跨度注意力机制引入使用单层注意力层,以较小的参数增量取得了更快速稳定的收敛速度和更好的抽取表现。
- 还没有人留言评论。精彩留言会获得点赞!