一种基于先验模型的人脸稠密毛发皮肤区域网格修复方法
本发明涉及计算机图形学中的人脸重建领域,尤其涉及一种基于先验模型的人脸稠密毛发皮肤区域网格修复方法。
背景技术:
1、三维人脸重建是计算机视觉和计算机图形学领域的重要研究内容,在影视游戏等领域都有着重要作用。
2、目前采用多目视觉人脸重建方法可以通过拍摄多个视角的高清照片,对人脸表面的几何结构进行重建。但对于人脸表面存在的面部毛发,不仅会遮挡到皮肤表面影响重建,而且由于毛发是高频信息,在重建时也难以重建出毛发的几何。
3、(beeler,thabo,bernd bickel,gioacchino noris,paul beardsley,stevemarschner,robert w.sumner,and markus gross.2012.coupled 3d reconstruction ofsparse facial hair and skin.acm trans.on graphics 31.4(2012):1-10.)提出了一种重建面部毛发纤维及位于毛发下的皮肤表面的方法。
4、但该方法中,对于如眉毛这样具有稠密毛发的区域,是直接使用重建出的三维毛发根部作为皮肤的采样点代替原始点云对皮肤表面进行重建。该方法得到的稠密毛发区域的点云密度要远低于其他地方,影响重建质量,此外该方法在重建出的毛发质量不好的情况对稠密毛发区域的皮肤的重建结果依然存在异常的几何结构。
技术实现思路
1、本发明的目的在于针对现有技术的不足,提供一种基于先验人脸模型的人脸稠密毛发皮肤区域网格修复方法。
2、本发明的目的是通过以下技术方案来实现的:
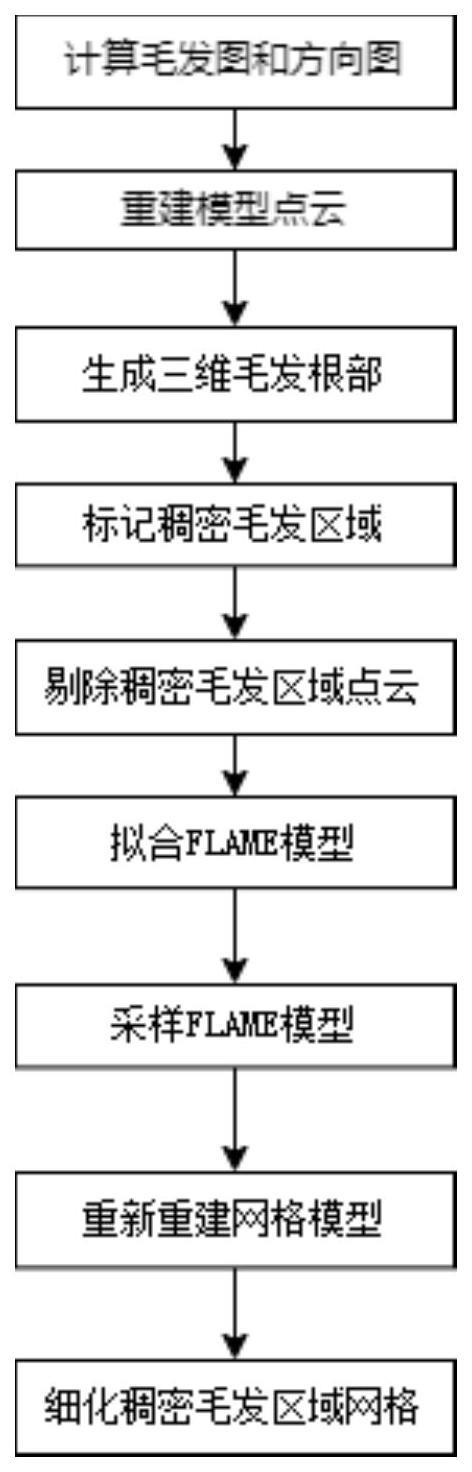
3、一种基于先验模型的人脸稠密毛发皮肤区域网格修复方法,包括以下步骤:
4、(1)计算毛发图和方向图:给定被重建者的多视角照片,将被重建者的多视角照片转至hsv颜色空间,使用不同角度的gabor卷积核函数分别处理图片的v通道的灰度图,根据不同方向的卷积核的卷积结果计算得到毛发图和方向图,并采用方向图和毛发图去除照片上的稀疏毛发;
5、(2)重建模型点云:去除了稀疏毛发后的照片使用多目视觉方法进行人脸模型三维重建,得到人脸点云数据和三角化后的网格模型;
6、(3)生成三维毛发根部:采用多目视觉的方法对各个视角照片生成的毛发图和方向图以及照片进行处理,得到三维毛发段;根据三维毛发段和初次重建出的模型的距离关系进行判断,得到三维毛发段的根部,作为毛发处皮肤的采样点;
7、(4)标记稠密毛发区域:利用稠密面部毛发出现在若干个面部区域的先验信息,使用图像分割的方法标记出照片中的这些区域作为后续处理的掩膜;
8、(5)剔除稠密毛发区域点云:读入相机内外参数,将初次重建出的人脸模型投影回各个视角下的图片,计算这些点云在各个视角下的可见性以及法线与视线方向的夹角,以可见性和夹角余弦值为排序关键字对各视角进行排序,其排序为第一即为选出的最合适的视角,检测每个点在其最合适视角下,在照片上的投影是否位于标记出的稠密毛发区域内,若处于稠密毛发区域内,则将该点进行剔除;
9、(6)拟合flame模型:使用去除了稠密毛发区域的人脸模型与毛发根部模型一同来优化flame模型;使得优化后的flame模型与原始模型贴合,且稠密毛发处与毛发根部也贴合;
10、(7)采样flame模型:使用重投影方法将flame模型投影回照片视角,得到位于稠密毛发区域的顶点和面片信息;对处于稠密毛发区域的面片进行随机采样,作为稠密毛发区域皮肤的采样点;
11、(8)重新重建网格模型:将采样flame模型得到稠密毛发区域皮肤的点云数据与去除了稠密毛发区域的原始人脸点云数据一同进行重建,得到三角网格模型;
12、(9)细化稠密毛发区域网格:计算新的三角网格模型的三角片的平均面积,并将新的网格模型投影回照片视角,找到原稠密毛发所在的区域,对该区域进行三角细分,直至该区域内三角片的面积都小于网格三角片的平均面积为止,;则完成了整个人脸网格模型修复。
13、进一步地,所述步骤(1)中毛发图代表该像素是毛发的可能性,所述方向图代表该像素的方向。
14、具体地,所述计算得到毛发图和方向图,具体为:先将拍摄的照片从rgb颜色空间转至hsv空间,使用gabor卷积核函数kθ处理图像的s和v通道,其数学表达式如下:
15、
16、其中,γ为卷积函数的形状,λ为卷积函数中三角函数部分的频率,为卷积函数中三角函数部分的相位,σ为卷积函数中高斯函数部分的方差;即使用18个不同的θ角度,从0开始每个方向差别10度,得到18个gabor卷积核,每个方向的gabor都对图片的v和s通道进行卷积,得到18个方向的卷积结果,g(θ,x,y)代表使用方向为θ的卷积核在(x,y)处像素的值;
17、g(θ,x,y)=|kθ*v|(x,y)+|kθ*s|(x,y) (2)
18、然后在对于每个像素点,选择在18个方向中值最大的方向,生成f图:
19、f(x,y)=max(g(θ,x,y)) (3)
20、且卷积结果中值最大的方向即为该像素的方向图o的值:
21、o(x,y)=argmax(g(θ,x,y)) (4)
22、接着对f图执行非极大值抑制算法,只有f(x,y)的值在垂直于o(x,y)的方向上是极大值时才将该像素上的值保留下来,得到置信图c,然后使用阈值迟滞的方法对置信度图c进行二值化得到掩膜图;
23、最后根据掩膜上每个像素点到掩膜上最近非零值的距离d计算得到毛发图h:
24、
25、进一步地,所述采用毛发图去除照片上的稀疏毛发,具体为:
26、以毛发图的值结合高斯函数得到每个像素点的权值,用于去除图像上的稀疏毛发,每个像素的对应的权值为:
27、
28、进一步地,所述步骤(5)具体为:采用重投影方法先得到稠密毛发处的点云,具体为:
29、读取各个视角下相机的内参k和外参矩阵p,对于重建出的三维顶点v,对于每一个视角,计算出v在该视角下照片的投影坐标(u,v)以及在相机坐标系下的深度z,数学表达式如下:
30、
31、选定若干个视角,将步骤(2)重建出的三维网格模型以这些视角的相机内外参数进行光栅化,得到深度图;然后再将步骤(2)重建出的点云变换到各个视角下,计算这些点云在各个视角下的可见性以及法线与视线方向的夹角;
32、接着对于每个点v,以可见性,夹角余弦值作为排序关键字对各视角进行排序评估,即先比较是否可见,再比较夹角余弦值;以排序评估第一的作为选出的最合适的视角,判断在该视角下,v是否位于步骤(4)分割出的掩膜内,若在掩膜内,则将该点剔除;最终得到剔除了稠密毛发区域的点云数据和网格模型。
33、进一步地,所述步骤(6)具体为:
34、(6.1)根据原始人脸模型的特征点与flame模型的特征点进行匹配,优化flame模型的全局旋转和全局平移,将flame模型旋转平移与原始人脸模型处于同一坐标系下;
35、(6.2)使用剔除了稠密毛发区域的原始模型的顶点以及毛发根部进行优化;具体优化的能量项使用原始模型的顶点到flame模型的距离与毛发根部到flame模型的距离;优化的参数为flame模型的基底系数betas,并增加正则项避免参数的过度优化;
36、(6.3)本轮优化的参数为flame模型的顶点坐标,并且仅使用剔除了稠密毛发区域的原始模型的顶点到flame模型的距离以及其他正则项作为能量项;以使得flame模型贴合原始模型,为阻止对稠密毛发区域的顶点的变化,从而利用flame模型内含的统计先验信息对该区域皮肤的几何进行约束。
37、本发明的有益效果如下:
38、本发明提出了一种利用flame先验人脸模对人脸稠密毛发皮肤区域网格修复方法。本发明在去除了重建人脸模型表面稠密毛发区域处的错误几何后,通过使用flame模型增加了人脸稠密毛发区域皮肤表面的采样数,并利用flame模型所具有的统计数据的先验信息使稠密毛发区域的皮肤几何形状更加真实,降低三维毛发重建质量差对稠密毛发区域表面重建的影响,也使修复后的稠密毛发区域的边界网格过渡自然,将模型重投影到照片时与照片中的人脸更贴合,因此具有较大的应用空间。
- 还没有人留言评论。精彩留言会获得点赞!