一种融合知识图谱和神经网络的浸渍纸原料管理系统的制作方法
本发明涉及数据管理领域,尤其涉及一种融合知识图谱和神经网络的浸渍纸原料管理系统。
背景技术:
1、目前,浸渍纸原料管理系统主要是通过人工记录和管理的方式进行的,存在以下问题:
2、数据不准确:由于人工操作容易出现错误和遗漏,导致原料信息的准确性无法得到保证。这可能导致生产过程中的浸渍液配比不准确,影响产品质量;
3、数据不实时:人工记录和管理需要一定的时间和人力成本,导致原料信息的更新和传输不及时。这可能导致生产计划和库存管理的不准确,影响生产效率和库存成本;
4、数据不可追溯:人工记录和管理无法提供完整的数据追溯功能,无法准确了解原料的来源、使用情况和变化趋势。这可能导致质量问题的溯源困难,影响质量管理和风险控制;
5、缺乏分析和决策支持:人工记录和管理无法提供有效的数据分析和决策支持功能,无法对原料的使用情况和效益进行深入分析和评估。这可能导致原料采购和使用的不合理,影响成本控制和资源利用效率;
6、随着浸渍纸行业的发展,生产规模和复杂性不断增加,传统的手工记录和管理已经无法满足需求。
技术实现思路
1、为了解决上述问题,本发明的目的在于提供一种融合知识图谱和神经网络的浸渍纸原料管理系统,对浸渍纸原料质量控制、库存管理等进行全面管理和监控的系统,能够提高生产效率、降低生产成本、提升产品质量,实现可视化管理。
2、为实现上述目的,本发明采用以下技术方案:
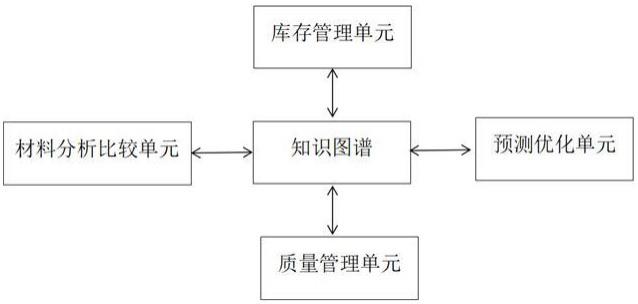
3、一种融合知识图谱和神经网络的浸渍纸原料管理系统,包括原材料知识图谱库、库存管理单元、材料分析比较单元、质量管理单元以及预测优化单元;所述库存管理单元、材料分析比较单元、质量管理单元以及预测优化单元分别与原材料知识图谱库连接;
4、所述库存管理单元,通过与供应商数据库的接口,自动获取供应商信息并创建采购订单,并将原材料的入库信息与知识图谱进行关联;
5、所述材料分析比较单元,通过知识图谱对原材料的属性进行分析和比较,找出与特定属性相关的原材料,供选择或优化配方;
6、所述质量管理单元,通过与质检系统的接口,将质检结果与原材料知识图谱进行关联;
7、所述预测优化单元,通过知识图谱对原材料的历史数据进行分析,预测原材料的需求量、库存变化,并优化原材料的采购计划和库存管理。
8、进一步的,所述原材料知识图谱构建,具体如下:
9、原材料节点:每种原材料都表示为一个节点,节点上包含以下属性:
10、- 原材料名称:表示原材料的名称;
11、- 原材料编号:表示原材料的唯一标识符;
12、- 原材料类型:表示原材料的类型;
13、- 原材料供应商:表示原材料的供应商信息;
14、- 原材料属性:表示原材料的其他属性;
15、属性关系:使用边来表示原材料之间的属性关系,包括:
16、- 相似属性关系:表示两种原材料具有相似的属性,根据属性的相似度来建立边;
17、- 依赖属性关系:表示一种原材料的属性依赖于另一种原材料的属性,可以根据属性的依赖关系来建立边;
18、-供应关系:根据供应商与原材料的供应关系建立边;
19、原材料属性的层次结构:使用层次结构来表示原材料属性之间的层次关系,包括:
20、- 父属性节点;
21、- 子属性节点;
22、 - 属性关系边:表示父属性节点和子属性节点之间的层次关系;
23、所述知识图谱包括二级展开图谱,其中一级展开示意图,展示浸渍纸的配方、组成成分及原材料;二级展开示意图,展示原材料可采用材料种类,以及对应供应商信息、库存数据、采购信息以及属性数据。
24、进一步的,所述库存管理单元包括原材料采购数据库和库存数据库;
25、在采购过程中,原材料采购数据库记录每次采购的原材料信息,并将材料知识图谱与采购入库数据进行关联;
26、将知识图谱中的原材料与库存数据库的原材料进行关联,在原材料入库时,将入库信息记录到库存数据库中,并更新库存数量。
27、进一步的,所述将材料知识图谱与采购入库数据进行关联,具体如下:
28、通过原材料的唯一标识符将知识图谱中的原材料与采购入库数据中的原材料进行关联;
29、将采购入库数据中的原材料信息与知识图谱中的原材料属性进行匹配,以验证原材料的准确性和一致性;
30、将采购入库数据中的供应商信息与知识图谱中的供应商信息进行匹配,以获取原材料的来源和质量。
31、进一步的,所述材料分析比较单元中预定义原材料的属性关系和规则,基于原材料知识图谱的推理和关联功能,基于已知的属性关系和规则,推断出与浸渍纸强度相关的其他属性,并找出与浸渍纸强度相关且符合用户需求的原材料;
32、定义有n个属性与浸渍纸的强度属性y存在相关性,则浸渍纸强度:
33、 y = β0 + σβixi,
34、其中,xi为原材料属性,βi为回归系数,1≤i≤n。
35、进一步的,所述预测优化单元包括词向量转换模块、词嵌入层、lstm模型和分析优化模块,具体构建如下:
36、所述词向量转换模块,抽取知识图谱中库存变化相关数据的实体及关系进行词向量的转换,将非结构化和半结构化数据转化为结构化数据;
37、所述词嵌入层通过将转化后的结构化数据作为输入,构建词嵌入层的训练数据集,并使用dbn深度置信网络来学习词向量,捕捉到词语的语义信息,丰富训练集的特征;
38、所述lstm模型基于训练集训练,得到原材料预测模型。
39、进一步的,所述dbn深度置信网络构建,具体如下:
40、对于每一层的rbm,使用对比散度算法进行训练,训练过程中,使用梯度下降法来最小化rbm的能量函数;
41、对于第一层rbm,其输入是词向量表示,输出是隐藏层的激活值。对于后续层的rbm,输入是前一层rbm的隐藏层的激活值,输出是当前层的隐藏层的激活值。
42、训练完成后,每个rbm都会学习到一组权重和偏差。
43、进一步的,所述使用对比散度算法进行训练,具体为:
44、使用梯度下降法来最小化rbm的能量函数,rbm的能量函数定义如下:
45、e(v, h) = -sum(w * v * h) - sum(b_v * v) - sum(b_h * h)
46、其中,v表示可见层的状态,h表示隐藏层的状态,w表示可见层与隐藏层之间的权重矩阵,b_v表示可见层的偏差向量,b_h表示隐藏层的偏差向量。
47、进一步的,所述训练过程如下:
48、(1) 初始化rbm的可见层的状态v为训练样本;
49、(2)使用gibbs采样来进行近似推断,得到隐藏层的状态h;
50、 - 通过计算条件概率p(h|v)来采样隐藏层的状态h
51、p(h|v) = sigmoid(b + wv)
52、其中,sigmoid表示sigmoid函数,b表示偏差项,w表示权重矩阵,v表示给定的变量;
53、 - 通过计算条件概率p(v|h)来采样可见层的状态v
54、p(v|h) = sigmoid(b + wh)
55、其中,sigmoid表示sigmoid函数,b表示偏差项,w表示权重矩阵,h表示给定的变量;
56、- 重复上述两步多次,直到达到稳定状态;
57、(3)计算rbm的梯度,并使用梯度下降法来更新rbm的参数:
58、 - 计算可见层与隐藏层之间的相关性:pos_corr = v * h.transpose();
59、- 计算可见层与隐藏层之间的平衡关联性:neg_corr = v' * h'.transpose();
60、其中v'和h'是通过gibbs采样得到的新样本,pos_corr 为可见层与隐藏层之间的相关因数,neg_corr为可见层与隐藏层之间的平衡关联因数;
61、- 更新权重矩阵w;
62、- 更新可见层的偏差向量b_v;
63、- 更新隐藏层的偏差向量b_h;
64、- 更新参数:w = w + delta_w;b_v = b_v + delta_b_v,b_h = b_h + delta_b_h;
65、其中,delta_w = learning_rate * (pos_corr - neg_corr);delta_b_v =learning_rate * (v - v');delta_b_h = learning_rate * (h - h'), learning_rate为学习率;
66、(4)重复(2)和(3),直到达到收敛条件或达到预定的训练迭代次数。
67、进一步的,所述原材料预测模型构建具体如下:
68、将经过词嵌入层处理的数据,分为训练集和测试集;
69、构建lstm模型,包括三层lstm层、一层dropout层和全连接层;
70、在模型的训练过程中,使用了adam优化器和均方误差损失函数进行编译,基于训练集的数据并指定训练迭代次数epochs和每批次的样本数量batch_size进行训练;
71、最后,使用训练后的lstm模型预测测试集数据,并使用反向传播算法来更新lstm网络模型的权重和偏差,最小化损失函数。
72、本发明具有如下有益效果:
73、1、本发明基于知识图谱技术对浸渍纸原料进行管理,能够实现对原材料的全生命周期管理,并提供更智能化、高效的原材料管理;
74、2、本发明利用知识图谱对原材料的属性进行深入分析和比较,帮助用户更好地理解原材料的特点和优劣,能够辅助用户进行分析决策;
75、3、本发明融合知识图谱、dbn和lstm对原材料的历史数据进行分析和预测,帮助用户更好地了解原材料的需求情况和库存变化,从而辅助用户做出更准确的供应链决策;使用反向传播算法来更新lstm网络模型的权重和偏差,最小化损失函数,并通过改进随机梯度下降法来加速训练过程,有效提高lstm网络模型的计算效率并节省计算成本。
- 还没有人留言评论。精彩留言会获得点赞!