一种面向心理咨询的用户情感分析方法
本发明涉及自然语言处理领域,具体是一种面向心理咨询的用户情感分析方法。
背景技术:
1、当人们寻求心理咨询时,往往倾诉出自己情感困扰和内心矛盾,表达情绪波动和情感需求。心理咨询师的言辞和语气传递安抚和支持信息,让用户感受被理解和接纳。这种安抚和支持有助于减轻用户的焦虑和压力,改善他们的情绪状态。因此对心理咨询文本中的用户进行情感分析,挖掘出用户自身的情感传递,以及用户与咨询师交互中产生的情感转移,识别用户情感的变化,使咨询师可以更好地了解用户情感状态,从而有效进行心理干预和支持,也为心理咨询ai助手实时检测用户的情感变化以生成合适的回复提供帮助。
2、现有对话情感分析方法主要分为基于上下文建模、基于说话者建模和基于外部知识建模三种。基于上下文建模的方法通过获取上下文信息,捕捉上下文信息对话语的影响并提取特征用于情感分类。基于说话者建模的方法将情感分析任务与说话者的特点与个性化相关联,考虑到不同说话者可能有不同的情感表达方式和特点,从而更准确的预测他们的情感状态。基于外部知识建模的方法通过利用外部的语言资源、情感词典、知识图谱等来增强模型的语义理解和情感识别能力。以上方法将对话历史文本作为一个整体特征进行情感分析,而在对话过程中,随着时间的推移早期对话内容可能逐渐模糊或被遗忘,在用户当前的前几句对话内容可能对用户当前有着较强的情感影响,本发明将对用户当前情感状态有较强影响的句子定义为前向近邻句,因忽略早期对话内容和前向近邻句对用户当前的情感状态具有不同程度的影响,导致分类的准确率较低。
3、针对以上不足,本发明提出一种面向心理咨询的用户情感分析方法。本发明不同之处在于,通过构建心理健康情感词典,识别对话双方历史文本中的情感词,并利用艾宾浩斯遗忘曲线对历史情感词序列进行权重分配,增强文本的情感特征。同时,使用交互注意力机制挖掘用户自身的情感传递、用户与咨询师之间的情感交互。
技术实现思路
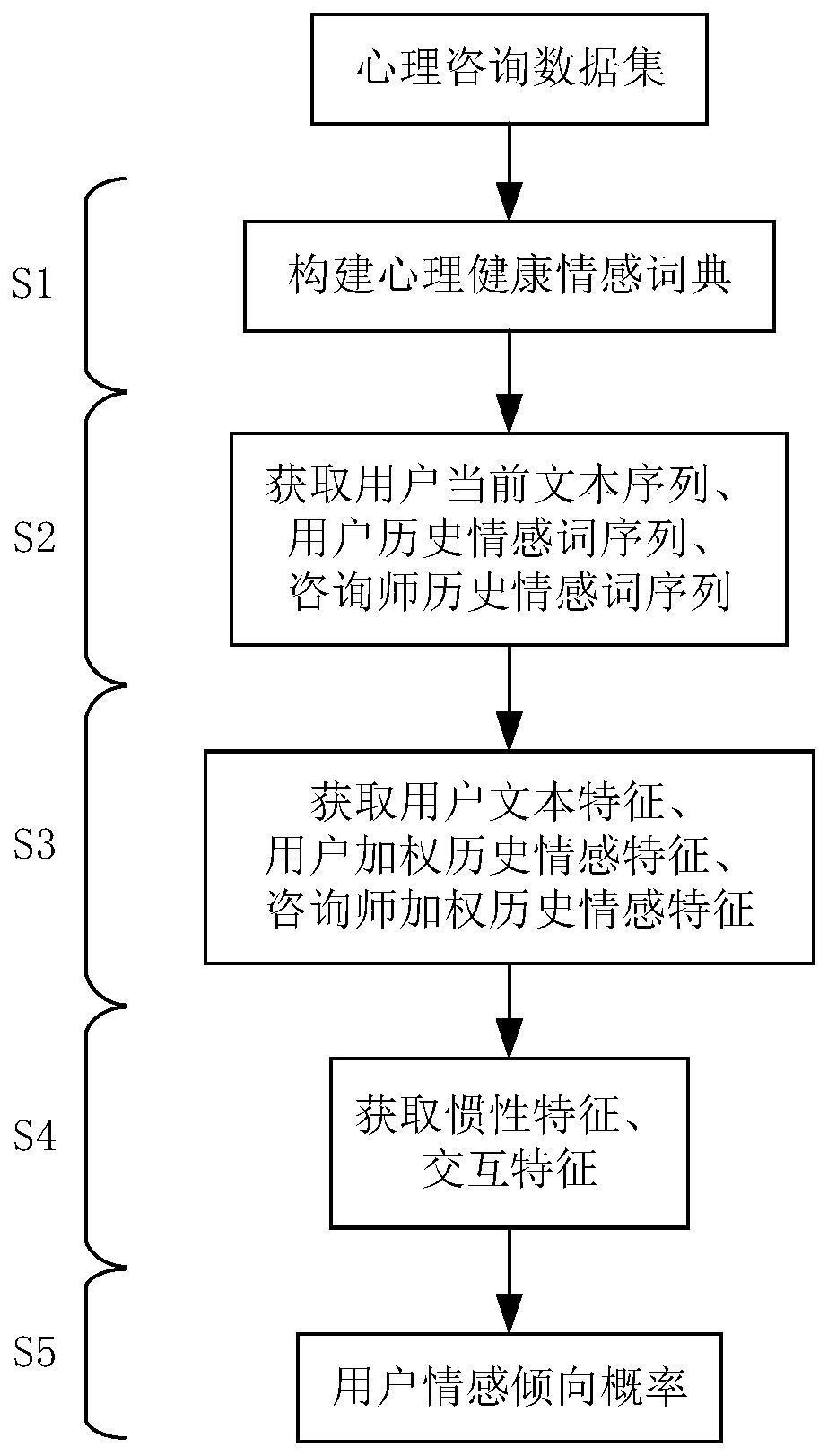
1、本发明的目的在于提供一种面向心理咨询的用户情感分析方法,先将心理咨询文本分为用户当前句、用户历史文本和咨询师历史文本,利用构建的心理健康情感词典分别提取对话双方历史文本的情感词序列。再将当前句与对话双方的历史情感词序列输入到bilstm中获取对应的特征向量,并利用艾宾浩斯遗忘对历史情感词序列进行权重分配。再将用户文本特征分别与对话双方的情感特征通过交互注意力机制获取惯性特征和交互特征,并结合用户文本特征输入到softmax计算情感倾向概率。
2、本发明为了实现发明目的采用如下技术方案:
3、一种面向心理咨询的用户情感分析方法,包括以下步骤:
4、步骤1:对数据进行降噪、分词、去停用词预处理后,计算词汇的情感倾向来构建心理健康情感词典,其基本步骤如下:
5、步骤1.1:降噪处理。将心理咨询文本中特殊符号、多余空格和url去除。
6、步骤1.2:分词操作。根据《心理学大辞典》中心理咨询与心理治疗、普通心理学、人格心理学和社会心理学这四个方面提取心理学领域专有名词,获取心理学词集,利用jieba分词工具对文本进行分词处理时,加入自定义的心理学词集来提高心理咨询文本分词的准确率。
7、步骤1.3:去停用词处理。从心理咨询文本分词结果中移除了出现在停用词列表内的单词。
8、步骤1.4:获取种子词集和候选词集。通过统计每个词汇在文本中出现的次数,以及在整个语料库中出现的文档数,计算出词频tf和逆文档频率idf后,求出tf-idf值。去除低频词以获取候选情感词集,并筛选出高频率词汇以获取正、负向情感种子词集。
9、步骤1.5:构建心理健康情感词典。通过计算候选词集与种子词集的pmi值,并进行差异计算,得出每个词的情感值so-pmi(w)并与阈值相比较,得出该词汇的情感倾向,进而构建心理健康情感词典。
10、情感倾向点互信息算法计算如下:
11、
12、参数说明:w1和w2分别表示未确定情感极性的情感词,pw和nw分别表示正负情感种子词,p(w1,w2)表示两个词语w1和w2共同出现的概率,p(w1)和p(w2)分别表示两个单词单独出现的概率,将w1与种子词计算情感倾向,最终差值大于0时,w1为正面情感词,等于0时,则为中性词;小于0时,则为负向情感词。
13、步骤2:将心理咨询文本进行预处理,获取用户当前文本序列,并结合步骤1构建的心理健康情感词典获取用户历史情感词序列和咨询师历史情感词序列,其基本步骤如下:
14、步骤2.1:将心理咨询文本首先分为三个部分,分别为用户当前句、用户历史文本和咨询师历史文本,再对三个部分进行降噪、分词和去停用词操作。在利用jieba分词工具进行分词时,加入自定义的心理学词集进行分词操作。经以上处理后获取用户当前文本序列、用户历史文本序列和咨询师历史文本序列。
15、步骤2.2:利用自建的心理健康情感词典,分别与用户历史文本序列和咨询师历史文本序列进行匹配,当历史文本序列中的词在情感词典中,则留下;反之,则去除。从而获取用户历史情感词序列和咨询师历史情感词序列。
16、步骤3:针对步骤2中获取的用户当前文本序列、用户历史情感词序列和咨询师历史情感词序列,通过bilstm和加权处理,提取相应的特征向量,其基本步骤如下:
17、步骤3.1:针对步骤2获取的用户当前文本序列、用户历史情感词序列和咨询师历史情感词序列,使用word2vec进行词嵌入训练,以获取每个词的词向量。
18、步骤3.2:将用户当前文本序列训练得到的词向量,输入到bilstm中获取用户当前句的文本特征向量,
19、
20、参数说明:表示t时刻正向隐藏状态,表示t时刻反向隐藏状态,ht表示t时刻隐藏状态,h表示用户文本特征向量。
21、步骤3.3:将用户历史情感词序列和咨询师历史情感词序列训练得到的词向量,分别输入到bilstm中获取对应的用户历史情感特征和咨询师历史情感特征。
22、步骤3.4:将用户历史情感特征和咨询师历史情感特征利用艾宾浩斯遗忘曲线,按照情感词序列位置进行权重分配,获取用户加权历史情感特征和咨询师加权历史情感特征。其加权计算过程如下:
23、
24、参数说明:βa(t)表示权重函数,c为1.25,k为1.84,αa(t)表示权重约束后的权重值,表示在t时刻的隐藏状态,haq表示用户加权历史情感特征。
25、
26、参数说明:βb(t)表示权重函数,c为1.25,k为1.84,αb(t)表示权重约束后的权重值,表示在t时刻的隐藏状态,hbq表示咨询师加权历史情感特征。
27、步骤4:针对步骤3获取的三个特征向量,通过交互注意力机制获取惯性特征和交互特征,其基本步骤如下:
28、步骤4.1:对于用户文本特征向量每一个元素的隐藏向量,计算与用户的加权历史情感特征中每个元素的注意力分数,再进行加权求平均后,得到用户文本特征对于用户加权历史情感特征的交互表示;
29、
30、参数说明:表示元素hi与之间的注意力分数,f表示计算元素hi与相似得分的函数,表达了用户文本特征对于用户加权历史情感特征的表示。
31、对于用户的加权历史情感特征的每一个元素的隐藏向量,计算与用户文本特征中每个元素的注意力分数,再进行加权求平均后,得到用户加权历史情感特征对于用户文本特征的交互表示;
32、
33、参数说明:表示元素与hi之间的注意力分数,f表示计算元素与hi相似得分的函数,表达了用户加权历史情感特征对于用户文本特征的交互表示。
34、根据以上两个交互表示,得到用户当前情感状态与用户历史情感状态进行交互的惯性特征。
35、
36、参数说明:i表示惯性特征,wi和bi表示惯性特征的权重和偏置项。
37、步骤4.2:同步骤4.1进行处理用户文本特征和咨询师历史情感特征,进而获取用户与咨询师之间情感转移的交互特征m。
38、步骤5:融合步骤3和步骤4获取的特征并输出到全连接层和softmax获得分类结果,其基本步骤如下:
39、步骤5.1:将用户文本特征、惯性特征和交互特征进行融合。
40、
41、参数说明:s表示用户文本特征h、惯性特征i和交互特征m融合结果。
42、步骤5.2:将融合后的特征向量经全连接层输入到softmax层中,计算用户情感倾向概率。
43、
44、参数说明:ws和bs分别表示为权重矩阵和偏置项,表示预测结果。
- 还没有人留言评论。精彩留言会获得点赞!