跨多种室内场景的视觉定位方法
本发明涉及一种跨多种室内场景的视觉定位方法,属于视频图像拍摄视觉定位领域。
背景技术:
1、给定一幅rgb图像,视觉定位的目标是估计从相机坐标系估计到世界坐标系的6自由度相机位姿。这是机器人感知系统的关键步骤,如结构从运动(sfm)和同步定位和绘图(slam)。当前基于学习的视觉定位前沿方法可分为绝对位姿回归、相对位姿回归和场景坐标回归。其中,场景坐标回归方法使用训练好的卷积神经网络(cnn)直接预测场景坐标,并使用pnp算法计算摄像机姿态。
2、作为一项开创性的工作,有学者利用回归森林预测三维坐标。后续的研究主要关注网络架构设计,以实现准确的视觉定位。例如,还有学者提出了一种分层结构,为每个像素附加离散的位置标签,以区分相似的像素,从而获得更高的精度。还有学者阐述了一种元素关注,有效融合多个特征,构建稀疏图神经网络,实现全面的场景解析。虽然这些方法带来了很好的结果,但它们也有一些缺陷。这些方法的场景坐标回归是特定于场景的,需要对新的场景进行重新训练,导致存储成本随着场景数量的增加呈线性增加,使得这些方法在资源有限的情况下难以持续。
技术实现思路
1、针对视觉定位场景坐标回归方法只能应用于特定场景的问题,本发明提供一种跨多种室内场景的视觉定位方法。
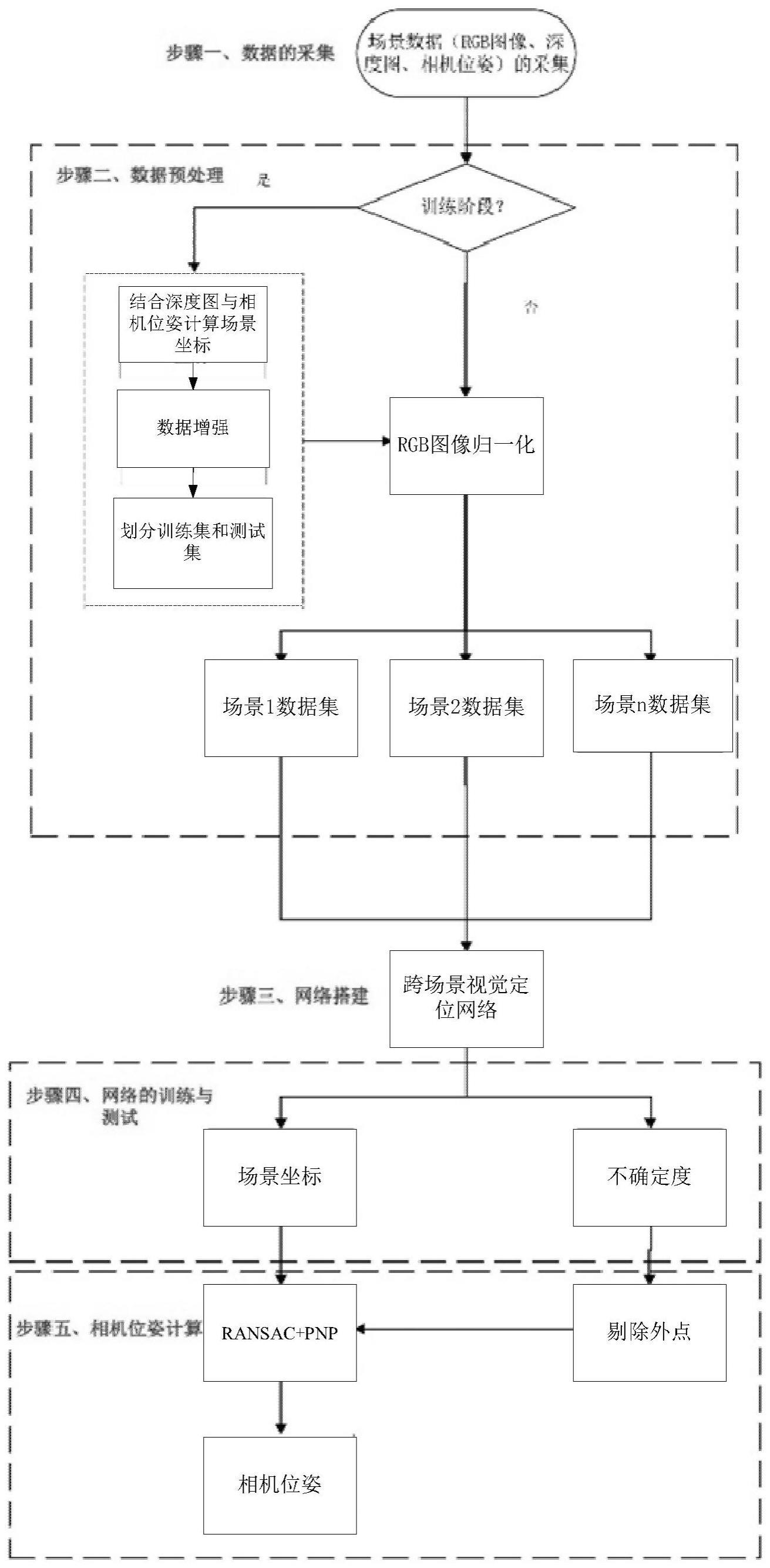
2、本发明的一种跨多种室内场景的视觉定位方法,包括:
3、s1、在n个不同的场景中,进行采集数据,数据包括rgb图像、深度图、采集相机的位姿;
4、s2、对s1中采集的数据进行预处理;
5、s3、将场景中的rgb图像和深度图作为输入,将深度图中每个像素点所对应的场景坐标作为输出,搭建跨场景视觉定位网络,利用预处理后n个场景的rgb图像分别输入到跨场景视觉定位网络中进行训练,得到训练好的n个场景的跨场景视觉定位网络;
6、对跨场景视觉定位网络进行训练时,卷积层权重确定时采用自适应参数共享策略:
7、在正向传递中,确定第i个卷积层各个通道的可学习得分表示第c个通道的得分,c=1,2,…,cin,cin为输入的通道数,计算二值化后的得分参数θ(si):
8、
9、其中,λ表示设置的阈值;
10、若为0,则继续判定相应通道内各个卷积核的参数是否共享,若为1,则判定相应通道内各个卷积核的参数为任务特定权值
11、判定相应通道内各个卷积核的参数是否共享的方法:
12、确定算所述相应通道内各个卷积核的可学习得分h为卷积核的高,l为卷积核的宽,表示位置(j,k)的得分,j=1,2,…,h,k=1,2,…,l,计算卷积核二值化后的得分参数若为0,则通道内相应卷积核的参数为共享权值wi,若为1,则通道内相应卷积核的参数为任务特定权值
13、将训练好的n个场景的跨场景视觉定位网络中的权值整合成一个跨场景视觉定位网络;
14、s4、根据待测的rgb图像和对应深度图像选择相应跨场景视觉定位网络的权值,再利用跨场景视觉定位网络对待测rgb图像进行预测,得到每个像素点的场景坐标,根据得到的场景坐标及对应深度图像中的像素坐标,计算相机位姿。
15、作为优选,跨场景视觉定位网络的输出还包括不确定度,s4中,跨场景视觉定位网络输出每个像素点的场景坐标和不确定度,根据不确定度剔除预测效果差的场景坐标,根据剩余的预测效果的场景坐标,及相应深度图像中的像素坐标,计算相机的位姿。
16、作为优选,将训练好的n个场景的跨场景视觉定位网络中的权值整合成一个跨场景视觉定位网络:
17、第n个场景的任务特定权值的梯度为:
18、
19、表示对求梯度操作,表示第n个任务的训练损失;
20、整合成一个跨场景视觉定位网络后的任务特定权值的梯度更新为:
21、
22、第n个场景的共享权值的梯度为:
23、
24、表示对求梯度操作;
25、整合成一个跨场景视觉定位网络后的共享权值的梯度更新为:
26、
27、将第n个场景的共享权值和任务特定权值
28、作为优选,第n个任务的训练损失:
29、
30、其中:q为输入图像的像素数,cn,q为第q个像素的预测场景坐标,为第q个像素的真实场景坐标,un,q为第q个像素的不确定度。
31、作为优选,在反向传播过程中,第n个场景的可学习得分sn的梯度为:
32、
33、其中,表示对的求梯度操作。
34、作为优选,s3中,对跨场景视觉定位网络进行训练时,每结束一次epoch,使用当前跨场景视觉定位网络参数进行一次测试,若测试结果的误差和准确率均优于保存的最优网络,则将当前跨场景视觉定位网络参数保存为最优参数;当训练次数达到所设定的epoch值时,停止训练,得到训练好的跨场景视觉定位网络。
35、作为优选,s4中,使用ransac与pnp算法选择q组像素点与预测的场景点坐标,预测的相机位姿t*为:
36、
37、其中,q为输入图像的像素数,puq为第q个像素的像素坐标,pcq为第q个像素的相机坐标的深度值,k为相机内参,t为相机在世界坐标系中的位姿,pwi为第q个像素的预测场景坐标;
38、根据预测的相机位姿t*,使用高斯牛顿法计算每个像素点的重投影误差,判断是否存在外点,若存在外点,则剔除外点,使用ransac与pnp算法根据剩余像素点,得到新的相机位姿t*,若不存在外点,当前相机位姿t*为相机的空间位姿t。
39、作为优选,所述跨场景视觉定位网络包括特征提取层和回归层;
40、所述特征提取层,由一系列的卷积层组成,用于对rgb图像中的特征进行编码;所述特征提取层使用修改后的resnet34网络作为主干网络,所述修改后的resnet34为在resnet34网络中去除最大池化层、平均池化层与全连接层,将四个残差块的步幅更改为(1,1,2,2);
41、所述回归层,由一系列卷积层组成,用于预测场景坐标与不确定度。
42、作为优选,训练过程中采用深度监督方法,使用回归层预测场景坐标与不确定度,随后各个场景之间的损失加权后相加获得总损失ltotal,表示第n个任务的训练损失,wn为调和各任务损失的权重系数,n=1,2,…,n。
43、作为优选,s1中,使用深度相机在n个不同的场景中采集大量的rgb图像、深度图、以及同时记录的每帧图像拍摄时的相机位姿,在不同场景中所用相机为同一设备,且相机参数保持一致。
44、本发明的有益效果,本发明设计了一种自适应参数共享策略,能够自动确定通道维度和单层空间维度中的参数是否共享,用于有效地优化各种场景的视觉定位特征表示,从而使得基于场景坐标回归的视觉定位方法能够适用于多种场景。
技术特征:
1.跨多种室内场景的视觉定位方法,其特征在于,所述方法包括:
2.根据权利要求1所述的跨多种室内场景的视觉定位方法,其特征在于,跨场景视觉定位网络的输出还包括不确定度,s4中,跨场景视觉定位网络输出每个像素点的场景坐标和不确定度,根据不确定度剔除预测效果差的场景坐标,根据剩余的预测效果的场景坐标,及相应深度图像中的像素坐标,计算相机的位姿。
3.根据权利要求1所述的跨多种室内场景的视觉定位方法,其特征在于,将训练好的n个场景的跨场景视觉定位网络中的权值整合成一个跨场景视觉定位网络:
4.根据权利要求3所述的跨多种室内场景的视觉定位方法,其特征在于,第n个任务的训练损失:
5.根据权利要求4所述的跨多种室内场景的视觉定位方法,其特征在于,在反向传播过程中,第n个场景的可学习得分sn的梯度为:
6.根据权利要求1所述的跨多种室内场景的视觉定位方法,其特征在于,s3中,对跨场景视觉定位网络进行训练时,每结束一次epoch,使用当前跨场景视觉定位网络参数进行一次测试,若测试结果的误差和准确率均优于保存的最优网络,则将当前跨场景视觉定位网络参数保存为最优参数;当训练次数达到所设定的epoch值时,停止训练,得到训练好的跨场景视觉定位网络。
7.根据权利要求1所述的跨多种室内场景的视觉定位方法,其特征在于,s4中,使用ransac与pnp算法选择q组像素点与预测的场景点坐标,预测的相机位姿t*为:
8.根据权利要求1所述的跨多种室内场景的视觉定位方法,其特征在于,所述跨场景视觉定位网络包括特征提取层和回归层;
9.根据权利要求8所述的跨多种室内场景的视觉定位方法,其特征在于,训练过程中采用深度监督方法,使用回归层预测场景坐标与不确定度,随后各个场景之间的损失加权后相加获得总损失ltotal,表示第n个任务的训练损失,wn为调和各任务损失的权重系数,n=1,2,…,n。
10.根据权利要求1所述的跨多种室内场景的视觉定位方法,其特征在于,s1中,使用深度相机在n个不同的场景中采集大量的rgb图像、深度图、以及同时记录的每帧图像拍摄时的相机位姿,在不同场景中所用相机为同一设备,且相机参数保持一致。
技术总结
跨多种室内场景的视觉定位方法,解决了视觉定位场景坐标回归方法只能应用于特定场景的问题,属于视频图像拍摄视觉定位领域。本发明包括:在N个不同的场景中,采集数据,对采集的数据进行预处理;将场景中的RGB图像和深度图作为输入,将深度图中每个像素点所对应的场景坐标作为输出,搭建跨场景视觉定位网络,对跨场景视觉定位网络进行训练时,卷积层权重确定时采用自适应参数共享策略:根据待测的RGB图像和对应深度图像选择相应跨场景视觉定位网络的权值,再利用训练好的跨场景视觉定位网络对待测RGB图像进行预测,得到每个像素点的场景坐标,根据得到的场景坐标及对应深度图像中的像素坐标,计算相机位姿。
技术研发人员:王珂,谢涛,杨淋淇,孙祺淏,李瑞峰,陶贤水,赵立军
受保护的技术使用者:哈尔滨工业大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!