基于部分可观测强化学习的分布式经济调度方法
本发明属于电网,涉及基于部分可观测强化学习的分布式经济调度方法。
背景技术:
1、为了实现向智能电网的过渡,能源管理是一个需要重新审视的重要问题。传统电网通常采用集中式控制架构,但是随着数据规模的扩大,传统的求解方法计算量较大,且难以进行整体求解;对于不确定因素,集中式控制架构缺乏灵活性。此时的智能电网系统已经是复杂的动态系统,针对变量高维度问题,高维特征的冗余性和不相关性会降低传统算法的求解速度和精度,系统中复杂多样的约束条件会导致模型的非线性化,也将加大求解难度;因此,传统的集中式控制架构可拓展性较差,可能无法实现对新型电力系统的准确优化调控。
2、目前,已有大量文献对多智能体强化学习在智能电网经济调度中的应用进行了研究。新型电力系统中的经济调度问题一方面解决了电力系统能源供需平衡的优化问题,另一方面提升了电力系统整体的稳定性与经济性。
3、面向电力系统的综合能源系统设计和优化近年来也被广泛研究。为了适应工业生产规模扩大,解决工业园区效率低、成本高等严重问题,并满足多能源需求,在工业园区引入了能源管理中心进行多能源管理。在环境的设定上,大部分研究聚焦于状态已知的马尔可夫过程,针对综合能源的高度不确定性,传统的优化方法建立能源系统的动态模型,这类方法计算量大,并且优化结果不理想。基于强化学习的分布式能源管理不依赖精确的模型,在分布式控制架构中,各节点通过自身与邻居节点交互信息,按照设定进一步完成相应的计算。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于部分可观测强化学习的分布式经济调度方法。
2、为达到上述目的,本发明提供如下技术方案:
3、基于部分可观测强化学习的分布式经济调度方法,其特征在于:该方法包括以下步骤:
4、s1:对于一个具有n节点的有向通信拓扑图g=(ν,ε,α),其中ν为顶点的非空有限集,为有向路径的有限集,αn=(aij)∈rn×n为邻接矩阵;有向通信链路表示节点i可以接受节点j传输的消息,aij表示节点i分配给邻居节点j的权重;如果任意两个节点之间存在着有向路径使得消息可达,则图g是强连通的,不讨论自环的情况,即对于和分别表示节点i的入度邻居集合和出度邻居集合;νi表示节点i的邻居节点集合;定义节点i的入度为有向网络由对角矩阵表示;
5、存在以下定义:
6、(1)定义l=di-α=[lij]∈rn×n为有向图的拉普拉斯矩阵,其中
7、(2)ρn=(pij)n×n为耦合权重矩阵,
8、(3)对于一个没有重边的加权图,若对所有的顶点,有入度等于出度,即满足时,则称该有向网络是平衡网络;设智能体i在时刻m的标量状态为则其一阶离散时间平均一致协议为:
9、xi[m+1]=xi[m]+σ∑aij(xj[m]-xi[m])
10、或者
11、x[m+1]=x[m]+σlx[m]
12、其中,为步长;
13、部分可观测马尔可夫决策过程pomdp由一个六元组<s,a,r,p,z,o>定义,s表示状态集合,并且环境状态为部分可观测;a表示动作集合;r表示奖励函数;p表示状态转移函数,状态转移矩阵表述了不可观测状态按照markov链随机转移,观测矩阵联系了系统的输出与真实不可观测状态;z表示观测值集合;o表示对于每个状态和动作的观测函数,代表基于观测值的概率分布,表示智能体执行动作后,转移到状态得到观测值的概率,o(s′,a,z)=p(z|s′,a);
14、用信度状态表示有效的历史信息,b(s)为状态s的信度状态,所有状态的信度之和为1,bt(s)表示t时刻智能体处于状态s的概率pt(s:s∈s);信度状态的更新基于智能体所采取的动作和观测信息;求解pomdp问题时,就是得到一个从动作集合到信度状态的映射;
15、对于t时刻信度状态bt(s)已知的智能体,在t时刻执行动作,从状态s转移到状态s′,得到观测值z,智能体在新状态s′的信度状态表示为:
16、
17、其中,分子o(s′,a,z)表示观测函数,p(s,a,s′)表示转换函数,分母p(z|a,bt)表示观测模块由前一时刻的信度状态和执行动作所得到的全部感知概率值:
18、
19、在pomdp问题中,最优值函数求解公式变更为:
20、
21、其中,b是所有信度状态的集合,
22、
23、
24、s2:建立分布式经济调度问题;
25、s3:进行分布式经济调度的多智能体深度强化学习。
26、可选的,所述s2具体为:
27、园区里包括热电联产装置chp、传统发电机组tg和用户;
28、针对设备chp、tg和能源交换过程进行建模,具体过程如下:
29、(1)热电联供装置
30、chp通过消耗天然气,产生热能和电能,满足用户热能需求;chp的热功率比表示为:
31、
32、hchp=ηhgchp,
33、echp=ηpgchp
34、其中hchp和echp分别代表chp生产输出的热能和电能,ηh和ηp分别代表chp装置通过消耗天然气gchp产生热能和电能的效率;其成本函数表示为cchp;
35、能量约束如下所示:
36、
37、
38、
39、其中,和分别是chp的热量上限和功率上限,是设定的最大热功率比;
40、(2)传统电力生产
41、tg为传统的发电方式,其成本函数表示为ctg;
42、其中,g、h、k是tg固有的参数;
43、发电量约束表示为:
44、
45、其中,etg是tg输出的电能,和分别是tg电能输出的下限和上限;
46、(3)与公司进行能源交换
47、工业园区分别以价格pg和pp从天然气公司和电力公司购买天然气和电能;其成本函数分别表示为:
48、cg=pgggc
49、cp=ppepc
50、与公用事业公司进行能源交易的约束条件表示为:
51、0≤ggc≤gmax
52、0≤epc≤emax
53、其中,ggc和gmax表示天然气的购买量和购买上限;epc和emax表示电能的购买量和购买上限;
54、电能、热能、天然气用总量分别表示如下:
55、
56、其中,ei表示第i位用户的电力需求;n、m分别是chp和tg的总数;i是区域内电力需求用户的总数;
57、
58、其中,hi表示第i位用户的热力需求;
59、
60、其中,gi表示第i位用户的天然气需求;
61、可用能量域y={e,g,h},总可用能量域约束条件为:
62、
63、其中,yi表示第i位用户对能量y∈y的需求;
64、优化目标定义为最佳能源分配策略,使用最小的运营成本实现能源供需平衡;优化问题的目标函数表示为:
65、
66、其中,c是运营总成本;包括chp、tg发电的成本消耗和从天然气公司购买天然气、电力公司购电的成本花费;优化过程的约束整理如下:
67、
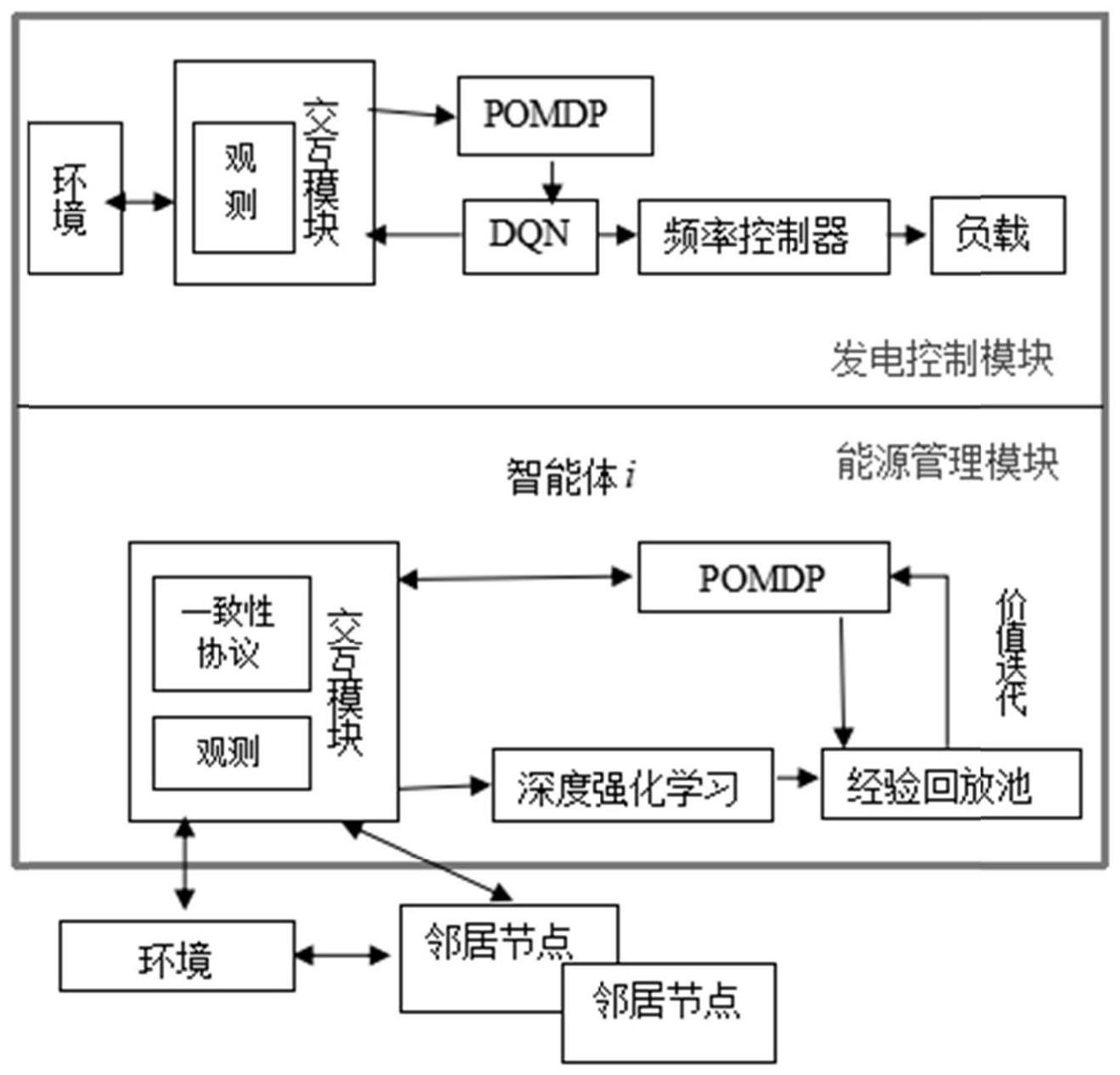
68、对于此系统,假设fi(x)为智能体i的局部目标函数,其中为智能体i的决策变量,分布式优化问题描述为:
69、
70、s.t.g(x)≤0
71、f(x)=0
72、其中g(x)、f(x)表示所有智能体的局部约束,g(xi)、f(xi)是智能体i的局部约束。
73、可选的,所述s3具体为:进行分布式经济调度的多智能体深度强化学习;
74、s31:部分可观测的能量管理系统;
75、s311:多智能体深度强化学习网络;
76、在生产园区中,多个能源设备与工业环境相互作用,并学习最佳策略,以最大化奖励函数;每个chp和tg都被视为单个智能体,采用静态优化的深度学习方案;每个agent获取本地信息并采取行动,然后mas从当前状态转移到下一个状态,并向agent分配相应的奖励;每个agent的状态、行动和奖励详情如下:
77、状态:在工业园区中,每个能源装置都有自己的观察结果,包括其能源消耗和发电;agent tg的状态向量包括园区总电力需求;agent chp,状态向量包括园区总电力需求、总热力需求、总天然气需求;
78、动作:对于agent tg,其任务是控制是否发电,动作集合为电功率输出ptg,i;agentchp的动作集合包括热功率比αchp,i和电功率输出pchp,i;
79、奖励:根据上面给出的运营总成本函数,设定该工业园区的奖励函数与成本函数负相关其中为目标需求,α1和α2为效用系数;假设每个能量装置/代理获得相同的奖励;因此,所有的代理都将以最大化共同奖励为目标;
80、为了引导策略走向满足约束的解,在奖励函数中应该添加一个局部不等式约束的惩罚项;奖励函数被修改为:
81、其中pi(s′i)是智能体i关于其局部不等式约束的惩罚函数,其中λi为惩罚系数;
82、s312:奖励记录器
83、在每个状态,智能体都会获得相应的奖励,算法通过平均一致性协议求取平均奖励,实现多智能体全局一致;对于智能体i当前状态<si,t,ai,t,si,t+1>,设置奖励网络其中为奖励网络的估计参数,奖励网络的损失函数定义为:
84、
85、通过平均一致协议得到平均奖励,有效奖励为平均奖励和对应记录奖励的最大值:
86、
87、然后由更新奖励记录器;最后将状态、动作、有效奖励组成的样本<si,t,ai,t,si,t+1,ri,t+1>存储在经验回放池中;
88、s313:贝尔曼算子收缩分析
89、状态空间s={s1,…,sm};动作空间a={a1,…,an},随机性策略为π(a|s),确定性策略为π(s)=a;考虑一个m维空间,每一维对应s中的一个状态;将值函数当作这个空间的一个向量,坐标为[v(s1),…,v(sm)];策略π的值函数为最优值函数为满足:
90、
91、对于所有的s∈s和贝尔曼期望算子定义如下:
92、
93、其中0≤γ≤1为折扣系数,定义两个值函数相差最大的状态的值定义为值函数的度量:对于任意两个v1(s)和v2(s),满足:
94、
95、即贝尔曼期望算子是s∈s的收缩映射;用迭代的方法求得策略的价值或最优价值;
96、对于mdp的序列有如下关系:
97、
98、
99、…
100、≤γm||bπvπ-vπ||∞
101、其中m是价值迭代的次数,随着m接近无穷大,与之间的差值接近于0,即序列收敛到一个不动点,为最优价值函数;
102、将智能体i的pomdp表示为<si,ai,ri,pi>,为实现全局一致性,智能体的奖励函数由r(r|s,a,s')改写为其中为平均奖励;为所有智能体的当前状态向量;为所有智能体的当前动作向量;为所有智能体的下一状态向量;状态价值函数的贝尔曼方程和贝尔曼期望算子改写为:
103、
104、
105、定义多个智能体在值迭代次数为m时的奖励函数为奖励函数随着迭代次数m变化;对于处于任意不同迭代次数m1和m2的v1(s)和v2(s):
106、
107、多个智能体收敛的条件为:当且仅当γ<1以及对都有即:
108、
109、对于智能体的pomdp序列
110、
111、
112、…
113、≤γm||bπvπ-vπ||∞
114、即序列会随着m趋近于无穷大,最终收敛到不动点v*;
115、对于基于奖励记录器的多智能体强化学习,推导出即为对于和m>1成立;当m=1时,有即大于奖励记录器的初始值;对于基于奖励记录器的多智能体强化学习,解决部分可观测影响时需要满足条件:r0<<0,γ<1
116、s314:具体算法如下:
117、(1)训练开始时,先初始化各参数,包括与邻居节点的通信权重、入度邻居、清空经验回放池、贪心策略ε、两层网络的估计神经网络权重参数;
118、(2)在每一个状态点,智能体i观测电力需求pi,t并由平均一致性协议计算总功率需求pt作为各智能体状态st,由贪婪策略获取执行动作ai,t,得到奖赏ri,t+1和观测ot+1;假如智能体在m时刻的状态为xi(m),被观测对象是向量x;基于一致性协议,设计分布式观测器;
119、
120、yi(m+1)←yi(m)+σ∑aij(xj(m)-xi(m))
121、
122、(3)使用二分查找法求解满足平衡约束的功率输出,调整功率输出其执行动作更新为计算信念表示bt+1;
123、(4)执行约束动作并整合样本发送至经验回放池,在固定的步数结束该回合;
124、(5)在每一个回合结束后,智能体从经验回放池中抽取小量样本进行学习,智能体i中的q网络通过迭代调整参数θi来训练减少贝尔曼方程中的均方误差,目标q网络定义为估计q网络定义为其中为智能体i的目标神经网络权重参数,为智能体i的估计神经网络权重参数;在pomdp环境中,状态s无法直接获取,在此情况下,应该利用信念模型的近似表示b,将q(s,a,θ)近似为q(b,a,θ),并以此进行策略优化;
125、定义估计q网络的损失函数为:
126、
127、目标值yi,t定义为:
128、
129、经过固定迭代次数后,使用估计网络的相关参数更新目标网络;
130、s32:部分可观测的发电控制系统
131、负荷频率控制是通过控制各发电机组的出力,来消除各个区域电网间的联络线功率偏差和频率偏差,以达到让整个电网稳定的目的;
132、频率调整fr是通过平衡发电和负载要求使电力系统的频率保持在标准值附近,部分可观测的发电模型为:
133、
134、状态:现实频率动态模型:其中s={δωi,δpij}为系统状态,δωi是总线i的频率偏差,δpij是从总线i到总线j的流量偏差;δpm为发电机机械功率;δpl为其他功率注入的偏差;发电机的调速涡轮控制模型表示为:
135、动作:对于agentfc,其任务是调频,动作选取设为标幺值,基准值根据运行电网的运行状态合理设置;
136、奖励:将系统的奖励函数设置为指数形式:r=ab|δω|,a表示最大可实现奖励,b∈(0,1)代表控制奖励衰减率的参数,此形式下δω越接近于0,奖励值就越大;
137、观测:多区域自动发电控制系统通常使用区域控制误差信号ace的比例、积分或者微分形式为观测结果,
138、可选的,所述s314为dqn算法,具体为:
139、(1)初始化各参数,包括两层网络的估计神经网络权重参数、贪心策略、清空经验回放池;
140、(2)采用贪婪策略选择智能体执行的动作,获取当前状态的信度表示;
141、(3)执行约束动作并整合样本发送至经验回放池,在固定的步数结束该回合;
142、(4)在每一个回合结束后,智能体从经验回放池中抽取小量样本进行学习,智能体中的q网络通过迭代调整参数来训练减少贝尔曼方程中的均方误差。
143、本发明的有益效果在于:
144、1、解决了智能电网非凸经济调度问题,针对智能电网中动态经济调度问题设计了分布式深度q学习算法。
145、2、将经济调度问题细化为能量分配问题和发电功率控制问题,并考虑环境的复杂性、高纬度性,建立经济调度中的部分可观测马尔可夫过程。
146、3、引入奖励记录器,减少了环境变化对奖励的不稳定影响,并且良好适配所提出的多智能体深度强化学习算法,同时将单智能体贝尔曼算子的收缩性质推广至多智能体强化学习,消除了部分可观测性对一致性的不利影响。
147、4、基于园区的部分可观测环境,设计了具有分布式观测器和经验池回放池的分布式强化学习。
148、5、在生产园区的气热电联供多智能体系统中,设计分布式查找法修改平均功率,完善了分布式强化学习中的平均一致性算法。
149、针对发电控制系统中的复杂环境进行部分可观测,提出了部分可观测的深度q学习发电控制算法。
150、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!