一种用于数学公式识别和抽取方法及系统与流程
本发明涉及在线教育,具体涉及一种用于数学公式识别和抽取方法及系统。
背景技术:
1、数学公式抽取是一项具有挑战性的任务,也是一项具有实际意义的任务。在在线教育领域中,从用户作答的纯文本文字中识别并抽取数学公式,是智能阅卷任务中核心的一环。例如“20×2年初乙公司股权价值=20×1年末乙公司股权价值=350×90%×(1+7%)/(11%-7%)=8426.25(万元)”,“20×2”表示的是年份而不是“20乘以2”,“=20×1”表示的是年份而不是“20乘以1”,“=350×90%×(1+7%)/(11%-7%)=8426.25(万元)”是一个正确的公式。并且用户作答通常是不规范的,系统固然可以通过“20×1年”中的“年”字来判断“20×1”的含义,但是当用户没有写明“年”这类关键字(词)时,判断“20×1”含义的难度相当大。
2、当前主要的解决方法可归结为以下三类:基于规则的方法、基于模板的方法和基于机器学习的方法。
3、1、基于规则的方法:基于规则的方法主要依赖预定义的规则,通过匹配这些规则来抽取数学公式。例如,可以通过匹配latex代码的特定模式来识别公式、通过正则表达式匹配符合预定义模式的公式。基于规则的方法也是最常用的方法。
4、优点:这种方法在处理符合预定义规则的公式时效果较好,实现相对简单,匹配速度很快。
5、缺点:由于数学公式的多样性和复杂性,定义全面的规则十分困难。此外,这种方法对于非标准的公式或新的公式形式适应性差,无法很好地处理。
6、2、基于模板的方法:基于模板的方法则主要依赖预定义的模板,对符合模板结构的公式进行抽取。这种方法通常需要专家对公式的结构进行深入分析,创建精细的公式模板。
7、优点:对于符合模板的公式,这种方法能够准确地抽取和解析。
8、缺点:由于需要专家进行模板创建,工作量大且耗时。同时,对于不符合模板的公式,这种方法无法有效处理。此外,新出现的公式形式需要重新设计模板,灵活性和适应性较差。
9、3、基于机器学习的方法:基于机器学习的方法主要是利用机器学习算法,自动学习公式的特征和结构,进行公式抽取。此类方法大都使用深度学习技术,例如使用命名实体识别(named entity recognition)进行公式位置的识别。
10、优点:这种方法可以自动地学习公式的特征,无需手动定义规则或模板,能够处理更复杂的公式,对新的公式形式具有一定的泛化能力。
11、缺点:此类方法需要大量标注的数据进行训练,且训练过程计算复杂度高,耗时且耗资源。同时,深度学习模型往往需要更精细的调参和优化。
12、综上所述,尽管现有技术在一定程度上实现了数学公式的抽取,但仍存在一些问题和不足,例如:抽取的准确性和效率,公式的适应性等。因此,研究和开发一种新的数学公式抽取方法是十分必要的。
技术实现思路
1、针对现有技术中的缺陷,本发明提供的一种用于数学公式识别和抽取方法及系统,能准确提高数学公式抽取的准确性和适应性,并且抽取效率高,提高处理大量文本的效率。
2、第一方面,本发明实施例提供的一种用于数学公式识别和抽取方法,包括:
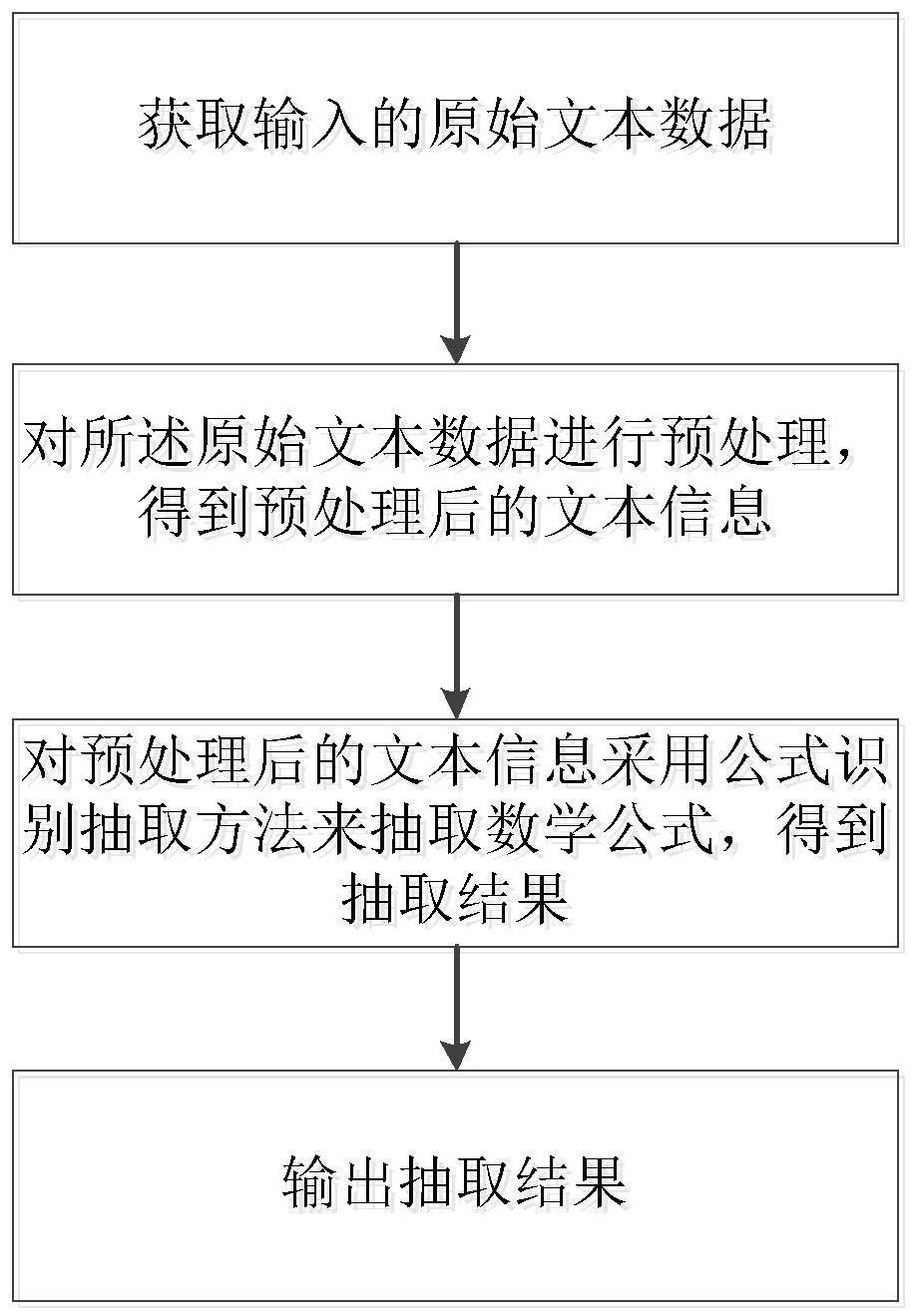
3、获取输入的原始文本数据;
4、对所述原始文本数据进行预处理,得到预处理后的文本信息;
5、对预处理后的文本信息采用公式识别抽取方法来抽取数学公式,得到抽取结果;
6、输出抽取结果。
7、第二方面,本发明实施例提供的一种用于数学公式识别和抽取系统,包括:数据获取模块、预处理模块、公式抽取模块和结果输出模块;
8、所述数据获取模块用于获取输入的原始文本数据;
9、所述预处理模块用于对所述原始文本数据进行预处理,得到预处理后的文本信息;
10、所述公式抽取模块对预处理后的文本信息采用公式识别抽取方法来抽取数学公式,得到抽取结果;
11、所述结果输出模块用于输出抽取结果。
12、本发明的有益效果:
13、本发明实施例提供的一种用于数学公式识别和抽取方法,具有以下显著的效果和优点:
14、高准确率:能够有效地识别和抽取出文本中的数学公式,包括复杂的数学符号和结构,大幅提高公式抽取的准确性。
15、高适应性:不仅能处理常见类型和格式的数学公式,还能处理未见过的或非标准的公式。通过引入机器学习技术,使模型具有更强的泛化能力,能够适应各种复杂情况。
16、高效率:优化了抽取流程,减少了冗余计算,有效提高了抽取效率。尤其在处理大规模文本时,能显著降低处理时间。
17、本发明实施例提供的一种用于数学公式识别和抽取系统,与上述用于数学公式识别和抽取方法具有相同的构思,除了具有相同的效果外,还具有易于扩展的优点:设计具有很好的模块化特性,可以方便地与其他系统或模块结合,如可以结合自然语言处理系统进行深层次的文本分析和处理。
技术特征:
1.一种用于数学公式识别和抽取方法,其特征在于,包括:
2.如权利要求1所述的方法,其特征在于,所述对原始文本数据进行预处理的具体方法包括:
3.如权利要求2所述的方法,其特征在于,所述将原始文本中连续的数字或符号分别组合成一组的具体方法包括:
4.如权利要求3所述的方法,其特征在于,所述将分割后的文本进行合并处理的具体方法包括:
5.如权利要求4所述的方法,其特征在于,所述将合并后的数据中的公式分组的具体方法包括:
6.如权利要求5所述的方法,其特征在于,所述对预处理后的文本信息采用公式识别抽取方法来抽取数学公式的具体方法包括:
7.如权利要求6所述的方法,其特征在于,所述识别计算过程的具体方法包括:
8.如权利要求7所述的方法,其特征在于,所述识别计算结果的具体方法包括:
9.如权利要求6所述的方法,其特征在于,所述对第二识别结果和第三识别结果进行映射的具体方法包括:
10.一种用于数学公式识别和抽取系统,其特征在于,包括:数据获取模块、预处理模块、公式抽取模块和结果输出模块;
技术总结
本发明公开了一种用于数学公式识别和抽取方法及系统,方法包括:获取输入的原始文本数据;对所述原始文本数据进行预处理,得到预处理后的文本信息;对预处理后的文本信息采用公式识别抽取方法来抽取数学公式,得到抽取结果;输出抽取结果。该方法能准确提高数学公式抽取的准确性和适应性,并且抽取效率高,提高处理大量文本的效率。
技术研发人员:刘琛,陈旭阳,杨旭川
受保护的技术使用者:重庆觉晓科技有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!