一种基于注意力跳跃连接的人脸属性编辑方法
本发明属于深度学习和计算机视觉,具体涉及一种基于注意力跳跃连接的人脸属性编辑方法。
背景技术:
1、人脸属性编辑是指将人脸图像作为输入并生成具有指定属性的人脸图像的过程,它的目标是编辑一个或者多个属性所在区域的同时保证其他区域的信息不发生变化。到目前为止针对可编辑的人脸属性提出了几种分类,人脸属性一般分为全局属性和局部属性,全局属性与输入人脸图像的整个区域相关,而局部属性的获取只需要考虑脸部的特定区域。例如,年龄是一个全局属性,其属性值由整张人脸决定,而头发是一个局部属性,其属性值由图像中头发的区域决定。chandaliya等人介绍了人脸属性的另一种分类方式,他们根据一个人脸属性所有值的数量分为多元属性和二元属性。基于这种分类方式,发色是一个多元属性(例如棕色、金色和黑色),而性别是一个二元属性(男性和女性)。人脸属性还可以分为连续型和离散型,连续型属性的值可以在两个值之间进行插值,而离散型属性的值只能从有限集合中采样。比如微笑是一个连续型属性,可以通过插值控制微笑的强度,而种族是一个离散型属性,只能从有限的值域中指定属性值。
2、近年来,基于生成模型特别是gan的人脸属性编辑已经取得了显著的成果。基于gan的人脸属性编辑方法通常需要将人脸图片x作为输入,编码器e将x嵌入到潜在空间z中,以获取人脸图片的嵌入表示z=e(x)∈z,后续将使用z来进行属性编辑。根据z的获取和操作方式的不同,可以把基于gan的人脸属性编辑方法大致分为三类:基于图像域转换的方法、基于人脸属性分解的方法和基于潜在空间的方法。
3、基于图像域转换的方法将人脸属性编辑看作图像到图像的转换问题,人脸图像根据属性被分组为不同的图像域,学习域级映射函数来完成图像转换。这种方法根据涉及的图像域的数量,还可以分为双域方法和多域方法。双域方法只能在两个图像域之间进行转换,一个模型只能编辑一种属性;而多域方法可以在多个图像域之间转换,一个模型可以编辑多种属性,大大降低了训练的成本。byeglassesgan是一种单向的双域方法,专门从人脸图片中移除眼镜。它设置了两个解码器,一个用于生成去除眼镜的人脸图片,另一个用于生成眼镜区域的掩码。人脸属性编辑可以被认为是一个无监督的图像转换问题,cyclegan中提出的循环一致性损失是无监督图像转换中使用最广泛的约束之一,可以将源域图像映射到目标域,再从目标域映射回源域,提升了编辑后的人脸图像的质量。wang等人提出一种类似cyclegan结构的模型用于年龄编辑,除了使用循环一致性损失外还引入了新的偏置损失以减少生成图像的伪影,能够使生成的图像更加真实。具有循环结构的btd-net能够编辑化妆属性,它有两个生成网络分别负责添加妆容和移除妆容,并利用了残差块来保留与目标属性无关的信息。由于缺少配对数据,为了保证生成的图像与对应的目标域一致,btd-net为每个生成器使用了两个不同的判别器。双域方法需要针对每个不同的属性重现进行训练,为了用单个框架实现多域之间的转换,一个简单的方法是将多个双域网络聚合为单个模型。随着更多的人脸属性被考虑在内,计算开销将变得越来越大。因此,大多数多域方法引入属性标签向量来完成多域间的转换,其中ai(i=1,2,…,n)表示第i个属性的值。icgan使用属性标签向量作为条件信息,向量中每个元素的值都是二进制值,即a={0,1}n,其中ai=1(ai=0)表示第i个人脸属性存在(不存在)。但icgan对人脸图片的嵌入表示施加了过多的约束,不仅导致了信息的丢失,还限制其原有的表示能力。为了解决约束过多的问题,attgan使用了属性分类器来保证生成的编辑结果即有正确的目标属性,又保留了无关属性。relgan提出了相对属性标签向量,使模型只关注需要改变的特征而不用知道图片的全部特征,防止模型过分强调某些不需要的特征,并且提出了插值判别器来实现对属性的细粒度连续控制。choi等人提出了stargan用以学习多个域之间的映射,只需一个生成器和一个域对应的标签。starganv2通过目标属性标签索引映射的样式编码来学习属性的混合样式,它沿用了stargan的假设即图像域是共享相同属性标签的图像集合,因此使用这种混合样式进行人脸属性编辑时,虽然能产生丰富多样的属性样式,但是经常会引入其他无关属性的样式,导致其他属性的样式一并发生了改变。
4、基于人脸属性分解的方法将人脸图片x根据每种属性编码到单独的潜在空间中,每个潜在空间中的嵌入表示负责控制x的不同属性。不同于基于图像域转换的方法,这类方法能够捕获图像的属性域内变化,即属性的多种样式,从而生成具有细粒度可控和灵活性的编辑结果。d2ae使用两个独立的分支分别对身份信息和属性信息进行编码,并将对抗思想引入身份分类器中,以此防止无关属性的信息被修改。sensoriumin用人脸图像的几何结构代替低维的潜在编码进行操作,这种几何结构的本质是由人脸纹理的几种相互独立的2维表征所描述的,因此也能抑制无关属性的变化。elegant交换两张图像的目标属性信息,在高分辨率的人脸图像间实现了属性样式迁移。
5、基于潜在空间的方法在编辑真实图片时,首先需要利用gan反转技术,将真实图片嵌入到预训练gan网络g*的潜在空间中得到潜在编码z=g-1(x)(g-1表示gan反转操作),对z进行线性或者非线性变化得到利用预训练的gan网络生成编辑后的图片这种方法可以编辑高分辨率的人脸图像且不用从头开始训练,因此近年来受到研究人员的广泛关注。潜在编码z可能会包含非目标属性的信息,在操作潜在编码z中的目标属性信息的同时,可能会改变其他无关属性的信息,即发生了属性纠缠问题。例如化妆与性别这两种属性在语义上高度相关,编辑化妆属性的同时,性别属性也会受到影响。除了属性间的语义联系,特征纠缠也是导致属性纠缠问题的一个原因。特征纠缠是指在生成器潜在空间中的嵌入表示含有多种属性的信息,导致编辑后的图像不仅修改了目标属性,还可能改变了其他无关属性。interfacegan提出可以针对二元属性学习一个超平面,通过对潜在编码进行简单的线性插值来操作人脸属性。在同时编辑多个属性时,可以通过子空间投影避免属性纠缠现象。但它只能对指定的一组属性用子空间投影进行解纠缠,未指定的无关属性还是会发生纠缠。在寻找非二元属性的编辑方向时,advstyle提出了一种对抗的方法来发现gan的潜在空间中任意属性的编辑方向,从而对非二元属性进行直观的编辑。但是在编辑真实图像时需要依赖gan反转技术,将真实图像转换为潜在编码,编辑结果中身份信息会发生较大的变化。大多数方法需要一个训练好的gan以提供含有丰富语义的潜在空间,无法进行端到端的训练。
技术实现思路
1、在基于编码器解码器架构的人脸属性编辑模型中,一般需要通过编码器对输入图像进行特征提取,获得与目标属性相关的特征表示或者与目标属性无关的特征表示,然后基于特征表示进行图像域的转换,最后将转换后的特征表示输入到解码器中生成编辑后的图像。编码器深度的增大虽然能够让模型对图片充分理解并得到完整表达目标属性的特征表示,但在维度被高度压缩的过程中会损失大量原始信息,导致重构的图像质量低下。此外在编辑全局属性例如微笑时,可能会涉及到嘴唇、眼睛、眉毛甚至脸部肌肉,由于卷积核的感受野有限,很难捕捉图片中长距离区域像素之间的关系,导致全局属性的编辑效果不能满足预期。本发明的目的在于提供一种基于注意力跳跃连接的人脸属性编辑方法,能够通过引入注意力跳跃连接到人脸属性编辑模型中以解决上述问题,本发明的目的是为了得到一个具有高质量强可控的人脸属性编辑模型。
2、为实现上述目的,本发明提供如下技术方案:一种基于注意力跳跃连接的人脸属性编辑方法,包括以下步骤:
3、步骤一:将人脸属性数据集中的属性标签进行重新划分,并将数据集划分为训练集和测试集,对训练集的图像进行预处理;
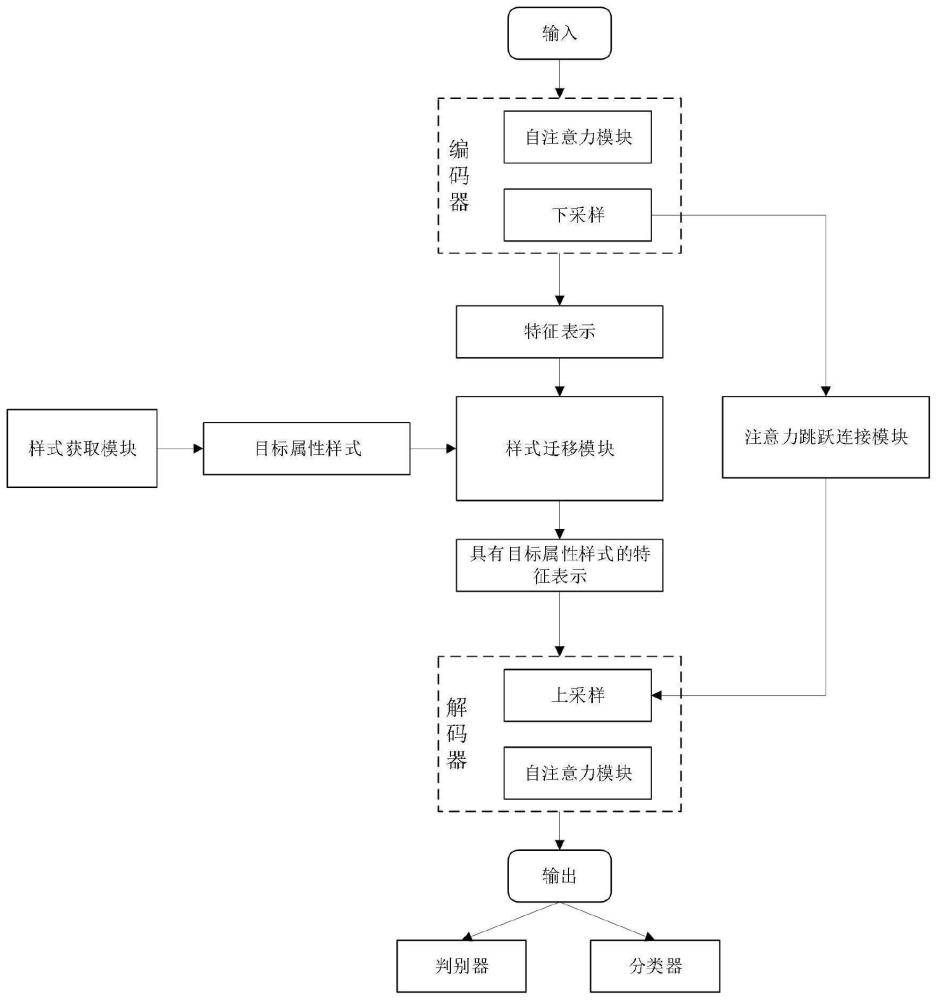
4、步骤二:构建人脸属性编辑模型,包括编码器、解码器、判别器、分类器、样式迁移模块、样式获取模块、自注意力模块和注意力跳跃连接模块;
5、步骤三:将所述步骤一获得的图像经过融合了自注意力模块的编码器得到含有属性信息的特征表示,通过自注意力模块能够在提取全局属性信息时将长距离依赖关系融合进编码器输出的特征表示中;
6、步骤四:通过样式获取模块获取待迁移的目标属性样式,其中样式获取模块有两种获取目标属性样式的方式,一种是通过随机向量生成目标属性样式,另一种是通过参考图像提取目标属性样式;
7、步骤五:将所述步骤三得到的特征表示和步骤四得到的目标属性样式输入到样式迁移模块中,将目标属性样式迁移到特征表示中得到具有目标属性样式的特征表示;
8、步骤六:将所述步骤五得到的特征表示通过解码器进行上采样以得到具有目标属性的人脸图像,上采样的过程中在编码器和解码器对称的各层均添加了注意力跳跃连接模块,解码器将通过跳跃连接传递过来的信息作为上采样时细节信息的补充;
9、步骤七:将步骤六得到的人脸图像输入到判别器和分类器中,通过对抗损失和分类损失保证经步骤六得到的人脸图像更加真实且满足对属性编辑结果的预期。
10、进一步的,所述步骤三包括:
11、采用的自注意力模块从全局学习输入图像中不同位置之间的空间关系,捕捉到每个像素点的上下文信息;在自注意力模块中将前一个卷积层的输出作为自注意力模块的输入,用三个卷积分别作为参数wq、wk和wv用于计算得到q=wqf、k=wkf和v=wvf,q和k的通道数均降低到原来的八分之一,其中n=w×h;然后根据q和k进行softmax得到注意力权重系数最后利用权重系数对v进行加权得到自注意力模块的输出f′=vw。
12、进一步的,所述步骤五包括:
13、在进行样式迁移时利用目标属性样式的均值和方差对去风格化后的特征表示进行风格化,表达式如下:
14、
15、式中σ表示标准差,μ表示均值,x表示特征表示且通过自身的均值和方差进行去风格化,y表示目标属性样式且需要迁移样式到特征表示x上;
16、adain是一种全局操作,为了抑制全局信息在风格迁移过程中被修改,并不直接使用迁移后的特征表示m,而是对它使用sigmoid激活函数得到一个注意力权重模板σ(m),利用注意力权重模板表示目标属性区域和其他区域的重要程度,在空间上保证迁移的过程中只修改目标属性所在区域,表达式如下:
17、σ(m)·f+(1-σ(m))·conv(m)
18、式中σ(m)·f表示源图像中与目标属性无关区域的信息,(1-σ(m))·conv(m)表示样式迁移后目标属性所在区域的信息,conv是为了让迁移后的特征表示m的维度与f一致的卷积操作。
19、进一步的,所述步骤六包括:
20、编码器对输入图片进行下采样的过程中会得到很多中间特征向量l∈{1,2,…,l},l指编码器的网络层数,每个中间特征包含目标属性相关的信息frel,enc和目标属性无关的信息funl,enc;解码器根据第l-1层的输出作为第l层的输入进行上采样前,通过注意力跳跃连接模块将fl,enc进行过滤后得到目标属性无关的信息funl,enc,最后把fl,dec和funl,enc在通道维度上进行拼接后得到表达式如下:
21、fl,dec'=concat(fl,enc·sigmoid(conv(asc(fl,enc,fl,dec))),fl,dec)
22、式中asc(·,·)目的是计算编码器某层的特征图和解码器某层的特征图之间的相似度,利用该相似度进一步计算出选择目标属性无关信息的权重系数,相似度的计算方式如下:
23、asc(fl,enc,fl,dec)=relu(wqfl,dec+wkfl,enc)
24、式中wq和wk是两个可学习的参数,获得相似度后利用卷积恢复通道数量并使用sigmoid得到权重系数,注意力跳跃连接模块作用在不同尺度的特征图之间,帮助生成器聚合来自多尺度特征图的信息。
25、与现有技术相比,本发明的有益效果是:
26、本发明在编码器和解码器利用卷积神经网络提取图像特征的过程中引入自注意力机制,有利于模型获取长距离依赖关系,进一步提升模型的属性解耦能力。此外在基于编码器解码器的架构上引入了跳跃连接,让解码器进行上采样时利用编码器传递过来的细节信息进行补充,并在跳跃连接中引入了信息过滤模块,在注意力机制的引导下选择性地丢弃与目标属性有关的信息,只保留与目标属性无关的信息,从而提升图像生成质量并且不会对编辑能力造成负面影响。
- 还没有人留言评论。精彩留言会获得点赞!