一种考虑填补顺序的线损异常辨识与修正方法及系统
本发明涉及线损管理以及数据分析,特别是一种考虑填补顺序的线损异常辨识与修正方法及系统。
背景技术:
1、随着各类敏感负荷投入电网,电压暂降(含电压短时间中断)等电力扰动可能造成用户生产中断,敏感设备不能获得所需质量的电能。电压暂降可能不会导致其停机,但会影响甚至破坏工业用户设备或工业生产线的连续工作,对工业用户造成的经济损失和危害是十分严重的。
2、现有的损失评估方法,在评价方法和影响因素的考虑等方面存在一些缺陷。一是没有考虑到敏感设备所在线路上配备的保护装置的动作时间,没有区分电压暂降是否会造成设备发生停机事故;二是电压暂降持续时间受到季节、工业类型等多种因素的影响,目前的损失评估方法忽略了对历史电压暂降大数据的分析和挖掘,并未将其应用到对损失的评估中,评价方法缺乏准确性。
技术实现思路
1、鉴于现有的人工操作失误、设备采集故障导致的线损数据异常问题,提出了本发明。
2、因此,本发明所要解决的问题在于实现异常线损数据的精准辨识,并提出一种考虑填补顺序的线损异常数据修正框架,实现线损异常数据最优填补顺序的决策并异常数据修正方法,灵活筛选异常数据源近邻节点,提高异常数据的修正精度。
3、为解决上述技术问题,本发明提供如下技术方案:
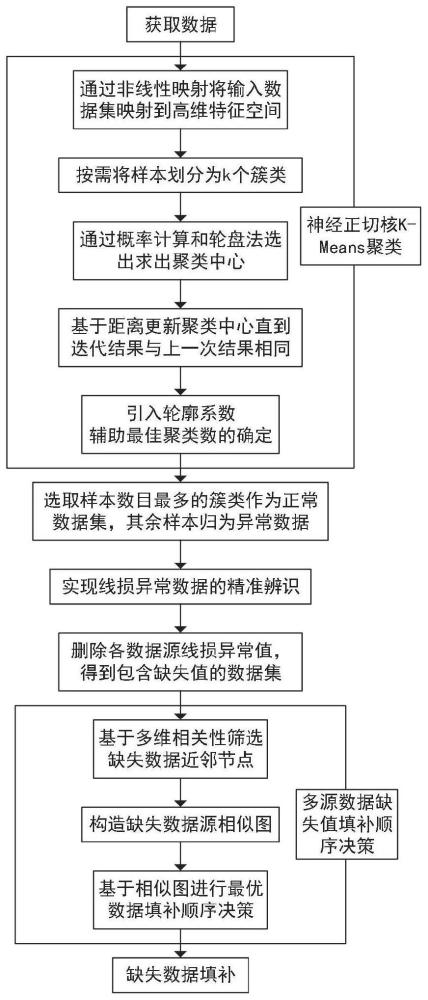
4、第一方面,本发明实施例提供了一种考虑填补顺序的线损异常辨识与修正方法,其包括通过神经正切核函数对原始线损数据集进行高维映射,获得核矩阵;基于聚类中心概率公式和轮盘法来选择k个初始聚类中心,并计算初始聚类结果;计算簇内最小距离与簇间最大距离的倒数之和的最小值,通过迭代更新聚类中心获得最终聚类结果;根据轮廓系数计算公式,计算当前k值的轮廓系数;对每个数据源的历史数据应用神经正切核k-means聚类算法进行分析和预处理;使用多维相似度计算方法计算数据源间的相似度,并筛选缺失数据源近邻节点;基于缺失数据源的近邻节点筛选结果计算顶点权重,并构造以缺失数据源为中心的相似图;通过计算联合概率、更新顶点权重值和寻找最佳填补顺序的贝叶斯网络问题求解方法,确定最优填补顺序;基于最优填补顺序使用近邻填补算法,在缺失数据源的相似图上进行数据填补以修正线损异常数据。
5、作为本发明所述考虑填补顺序的线损异常辨识与修正方法的一种优选方案,其中:神经正切核函数的具体公式如下:
6、
7、其中,(x,x')为输入数据,f(θ,x,x')为全连接神经网络,θ为神经网络中的参数集合,为全连接神经网络,x、x'为输入数据。
8、作为本发明所述考虑填补顺序的线损异常辨识与修正方法的一种优选方案,其中:基于聚类中心概率公式和轮盘法来选择k个初始聚类中心包括以下步骤:计算初始聚类中心,并确定每个样本被选为下一个聚类中心的概率;通过轮盘法选出下一个聚类中心,重复步骤直至选出k个聚类中心;将神经正切核函数代入,得到核k-means聚类目标函数;所述每个样本被选为下一个聚类中心的概率的具体公式如下:
9、
10、其中,xi为样本点,r(xi)为每个样本点xi与c1的距离,x为输入空间。
11、所述聚类目标函数的具体公式如下:
12、
13、其中,为第j个样本,为第i个聚类中心,ci为第i个簇中样本个数,xj为输入空间x中m维的样本,k为簇的个数,表示在高维特征空间中,第j个样本到第i个聚类中心的欧氏距离的平方,具体公式如下:
14、
15、其中,为第j个样本,为第i个聚类中心,ci为第i个簇中样本个数,xj为输入空间x中m维的样本。
16、作为本发明所述考虑填补顺序的线损异常辨识与修正方法的一种优选方案,其中:计算当前k值的轮廓系数的具体公式如下:
17、
18、
19、
20、其中,s为单个样本的轮廓系数,a为类ci中样本与所有其他点之间的平均距离,b为类cl中样本与距离最近的类ci中样本中所有点之间的平均距离,ci为类ci的质心,cl为类cl的质心,m和n分别表示类ci和cl中的样本个数,xi为样本点。
21、若当前k值小于预设的上限值,则k值加1,重复步骤;若当前k值达到预设的上限值,则退出循环,并输出不同k值所对应的轮廓系数;选取轮廓系数最大的k值作为最佳聚类数,并输出其聚类结果。
22、作为本发明所述考虑填补顺序的线损异常辨识与修正方法的一种优选方案,其中:计算数据源间的相似度的具体公式如下:
23、
24、其中,分别表示数据源si和sk在时间、空间和属性维度上的相似度,simik为数据源si和sk之间的多维相似度。
25、数据源si和sk在时间维度上的相似度计算公式如下:
26、
27、其中,为t时刻数据源si中待填补数据的时间邻域,为数据源sk中的属性邻域,为t时刻数据源si中待填补数据的时间邻域为其前t-s个时间点的数据,为数据源sk中的时间邻域。
28、数据源si和sk在空间维度上的相似度计算公式如下:
29、
30、其中,ρ为调整参数,且ρ∈(0,1),为待筛选的节点,m为每条感知数据包含的多维属性。
31、在求得数据源间的多维相似度之后,人为设定多维相似度阈值,删除小于给定阈值的节点,从而筛选出各缺失数据源的近邻节点。
32、作为本发明所述考虑填补顺序的线损异常辨识与修正方法的一种优选方案,其中:计算顶点权重的计算公式如下:
33、
34、其中,n(si)为数据源si的相对完整近邻节点集合,simik为数据源si和sk的多维相似度,si和sk均为数据源,simik为数据源si和sk之间的多维相似度。
35、作为本发明所述考虑填补顺序的线损异常辨识与修正方法的一种优选方案,其中:确定最优填补顺序包括以下步骤:根据缺失数据源相似图确定填补顺序,并将无向加权相似图即可转化为一个有向加权相似图;将有向加权相似图转化为一个贝叶斯网络,其中顶点权重为贝叶斯网络中每个顶点的先验概率,边权重为两个顶点间的条件概率;将贝叶斯网络输出联合概率作为相应填补顺序的置信度;根据已填补的缺失值作为后续填补过程的参考依据,动态更新后填补的缺失数据源的近邻节点和顶点权重值;根据置信度大小选取最优填补顺序,使填补误差最小;所述顶点权重值的具体公式如下:
36、
37、其中,si为缺失数据源,sn(i)为可用于缺失数据源填补的缺失近邻节点集合,为顶点权重,simij为数据源si和sj的多维相似度,sj为近邻节点。
38、第二方面,本发明实施例提供了一种考虑填补顺序的线损异常辨识与修正系统,其包括神经正切核k-means聚类模块,用于对每个数据源的历史数据,应用神经正切核k-means聚类算法进行分析和预处理;多维相似度计算模块,用于计算每个数据源在时间、空间和属性维度上的相似,并根据多维相似度阈值删除小于给定阈值的节点,从而筛选出各缺失数据源的近邻节点;顶点权重计算模块,用于根据缺失数据源的相对完整近邻节点集合和数据源和近邻节点的多维相似度计算顶点权重;近邻填补算法模块,用于在缺失数据源的相似图上进行数据填补以修正线损异常数据。
39、第三方面,本发明实施例提供了一种计算机设备,包括存储器和处理器,所述存储器存储有计算机程序,其中:所述计算机程序指令被处理器执行时实现如本发明第一方面所述的考虑填补顺序的线损异常辨识与修正方法的步骤。
40、第四方面,本发明实施例提供了一种计算机可读存储介质,其上存储有计算机程序,其中:所述计算机程序指令被处理器执行时实现如本发明第一方面所述的考虑填补顺序的线损异常辨识与修正方法的步骤。
41、本发明有益效果为:本发明通过神经正切核k-means聚类实现了线损异常数据的精准辨识,考虑在神经正切核k-means聚类的基础上引入轮廓系数,辅助神经正切核k-means聚类进行最佳聚类数的确定;其次,提出一种基于考虑填补顺序的线损异常数据修正框架,将已填补的缺失值作为后续填补过程的参考依据,将填补顺序决策问题转化为寻优问题,实现线损异常数据最优填补顺序的决策;最后,提出一种基于近邻节点的异常数据修正方法,在填补顺序确定后,已填补的缺失值可以作为后续填补过程的参考依据,此时后填补的缺失数据源的近邻节点也会动态更新,顶点权重也随之更新。提高了异常数据的修正精度。
- 还没有人留言评论。精彩留言会获得点赞!