一种基于时序信息引导混合专家的零样本视频问答方法与流程
本发明设计视频问答,具体涉及一种基于时序信息引导混合专家的零样本视频问答方法。
背景技术:
1、目前绝大多数视频问答任务中,采用的方法都是依赖全监督的设定,即需要在标注良好的视频问答数据集上进行训练,这种方法包括两个弊端:第一,为了得到一个标注良好的视频问答数据集需要投入大量人力物力;第二,在全监督设定下训练的模型,当遇到来自不同于训练集数据域的其他数据时,结果会表现得很差,泛用性不强。
2、零样本视频问答可以在一定程度上摆脱对良好标注的视频问答数据集的依赖,因为大规模语言模型强大的泛化能力和推理能力,目前的零样本视频问答大多结合大规模语言模型进行推理;但是该方法不能良好地为语言模型结合视频信息感知能力,同时不能有效提高在视频问答任务的泛化性。
技术实现思路
1、针对现有技术中的上述不足,本发明提供一种基于时序信息引导混合专家的零样本视频问答方法,引入时序模块来提取视频中的时序信息,提升大规模语言模型对视频中时序信息的感知能力;同时提出一个基于视频时序信息引导的混合专家模块来提升模型在零样本视频问答任务上的泛化能力。
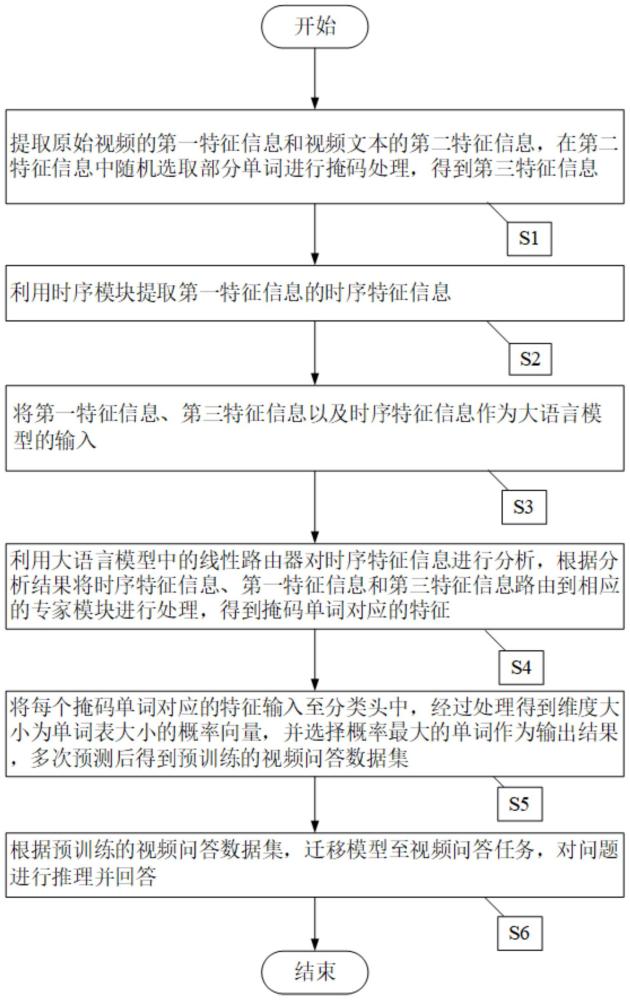
2、为了达到上述发明目的,本发明采用的技术方案为:一种基于时序信息引导混合专家的零样本视频问答方法,包括以下步骤:
3、s1:提取原始视频的第一特征信息和视频文本的第二特征信息,在第二特征信息中随机选取部分单词进行掩码处理,得到第三特征信息;
4、s2:利用时序模块提取第一特征信息的时序特征信息;
5、s3:将第一特征信息、第三特征信息和时序特征信息作为大语言模型的输入;
6、s4:利用大语言模型中的线性路由器对时序特征信息进行分析,根据分析结果将时序特征信息、第一特征信息和第三特征信息路由到相应的专家模块进行处理,得到掩码单词对应的特征;
7、s5:将每个掩码单词对应的特征输入至分类头中,经过处理得到维度大小为单词表大小的概率向量,并选择概率最大的单词作为输出结果,多次预测后得到预训练的视频问答数据集;
8、s6:将预训练的视频问答数据集,迁移模型至视频问答任务,对视频问题进行推理并回答。
9、本发明的技术方案的有益效果为:本发明基于大语言模型,引入时序模块和混合专家模块,能够提升大语言模型对视频中时序信息的感知能力和模型在零样本视频问答任务上的泛化能力,同时训练时以掩码语言建模为训练任务进行预训练,使得模型在视频文本数据集上训练得到一个具有对视频语言具有强理解能力和泛化能力的模型。
10、进一步地:所述s1的具体步骤如下:
11、s11:利用视觉编码器提取原始视频中视频帧的图像特征得到第一特征信息;
12、s12:将视频文本描述进行分词,得到多个词元;
13、s13:使用大语言模型中的单词嵌入转换器,将各个词元转换为带有语义信息的第二特征信息;
14、s14:在第二特征信息中随机选取单词进行掩码处理,得到第三特征信息。
15、上述进一步的有益效果为:将视频和文本转换为具有语义信息的特征向量,使得模型可以理解两个模态的数据信息,有助于模型的训练与迁移。
16、进一步地:所述s2的具体步骤为:
17、s21:将第一特征信息作为时序模块的输入;
18、s22:利用一维卷积网络对第一特征信息进行沿时间维度的卷积操作,得到第一特征信息的卷积特征;
19、s23:为第一特征信息的卷积特征添加上显式的时序位置嵌入,并与一个可学习的cls向量一起输入到多头注意力模块中,得到时序特征信息。
20、上述进一步方案的有益效果为:通过时序模块对第一特征信息进行处理得到时序特征信息,作为后续线性路由器对专家模块的选择依据。
21、进一步地:所述卷积操作的表达式如下:
22、
23、其中,为经卷积操作后的第t帧特征,δt为一个时间步,t为当前第t帧,ft+δt为第t+δt帧的第一特征信息,wconv为一维卷积核的参数,bconv为一维卷积核的偏移。
24、上述进一步方案的有益效果为:时序模块通过卷积操作,使得视频中每一帧特征捕获了相邻两帧的信息,从而提取了视频的局部信息。
25、进一步地:所述时序特征信息的计算表达式如下:
26、
27、fp=fconv+ptemp
28、其中,ftemp为时序特征,wq,wk和wv均为可学习的映射参数,q为可学习的cls向量,fp为添加了时序位置嵌入的卷积特征,fconv为第一特征信息的卷积特征,ptemp为时序位置嵌入,softmax(.)函数将输入转换为概率向量。
29、上述进一步方案的有益效果为:通过将cls向量与卷积特征输入到多头注意力中,cls向量与每个帧经过卷积后的特征进行交互,最终得到关于视频的全局特征,便于后续分析处理。
30、进一步地:所述大语言模型包括单词转换嵌入器、分类头以及带有混合专家模块的transformer层;
31、所述单词转换嵌入器,用于将视频文本描述进行分词,得到的多个词元,并将各词元转换为带有语义信息的第二特征信息;
32、所述分类头,用于最终将掩码单词对应的输出特征映射为对应词汇表的概率向量;
33、所述带有混合专家模块的transformer层,用于根据提取的视频时序特征,将第一特征信息、第三特征信息和时序特征信息路由到不同的专家模块进行处理,得到掩码单词的对应特征。
34、上述进一步方案的有益效果为:基于大语言模型,使用了带有混合专家模块的transformer层并引入时序特征的分析,提升大语言模型对视频中时序信息的感知能力和模型在零样本视频问答任务上的泛化能力。
35、进一步地:所述带有混合专家模块的transformer层,包括至少一个专家模块以及线性路由器;所述线性路由器,用于根据提取的视频时序特征,将第一特征信息、第三特征信息和时序特征信息路由到不同的专家模块进行处理;所述各专家模块,用于对第一特征信息、第三特征信息和时序特征信息进行分析,得到掩码单词的对应特征信息。
36、上述进一步的有益效果为:使用线性路由器对时序特征信息进行处理,为大语言模型引入了视频时序感知能力,同时使用混合专家模块,根据线性路由器的分析结果采用不同的专家模块,提高了模型在时序层面的泛化能力。
37、进一步地:所述线性路由器的表达式如下:
38、sgate=softmax(g(ftemp))
39、g(ftemp)=wgftemp+δ·softplus(wnoiseftemp)
40、其中,sgate为选择各个专家模块的概率向量,所述概率向量为4维,对应4个专家模块,ftemp为时序特征,wg和wnoise均为线性层中的可学习参数,δ为高斯噪声,g(.)函数为线性路由器的函数,softmax(.)为softmax函数。
41、上述进一步方案的有益效果为:根据时序特征计算选择各个专家模块的概率向量,并根据概率向量将第一特征信息输入进选择的专家模块,使得具有不同时序特性的视频能够被输入到相应特定的专家模块中进行处理。
42、进一步地:所述分类头的目标优化函数表达式如下:
43、
44、其中,是交叉熵损失函数的值,x表示被掩码的单词,p(x|s\m(s))表示分类头输出的概率向量,s\m(s)表示输入句子中除开被掩码掉单词的其他所有单词。
45、上述进一步的有益效果为:使用该公式将高维的特征向量转换为词汇表大小的维度,便于根据概率向量的概率值选择最合适的答案作为模型输出。
46、本发明的有益效果为:本发明不需要在视频问答数据集上进行训练,而是在其他数据集上训练,然后直接在视频问答任务上进行推理,无需样本训练;本发明基于目前视频问答工作过于依赖标注良好数据集的弊端,以及目前零样本视频问答方法未能良好地结合视频时序信息和未能研究如何提升模型泛化能力的问题,提出了一个能够提取视频时序信息的模块,为大语言模型引入视频时序感知能力;同时提出的混合专家模块,提高了模型在时序层面的泛化能力;本发明在多个传统多模态任务上达到最佳性能,具有强理解能力和泛化能力。
- 还没有人留言评论。精彩留言会获得点赞!