一种面向近似最近邻搜索的近邻图更新方法
本发明涉及数据查询,尤其涉及一种面向近似最近邻搜索的近邻图更新方法。
背景技术:
1、随着信息技术的不断发展,图像、视频和文本等数据呈现爆炸式增长。这些数据通过深度学习方法被表征为高维向量,存储在向量数据库系统中。因此,如何从海量的高维向量数据中快速检索出有效信息是当前研究的热点。然而,最近邻搜索算法在面对高维数据时,会产生“维度灾难”的问题,使其搜索性能低下。近似最近邻搜索方法能够平衡搜索准确率与速度,以满足实际需求。其中,基于近邻图的近似最近邻搜索算法具有高速度和高精度的特点,因此当前的向量数据库系统(例如milvus,qdrant,zilliz等)核心索引结构均为近邻图——hnsw。然而,现有的向量数据库系统仍存在一些不足:其核心hnsw是针对静态数据而设计的,很难适应数据的动态变化。例如,在某购物app的“拍立淘”功能中,商家上传商品图片以建立索引。当商家更改商品图片时,该购物app需要删除过期顶点并插入相应的新顶点。目前向量数据库系统中hnsw是针对静态数据而设计的,无法应对现实世界中用户与系统交互所带来的数据更新问题。因此,对于向量数据库系统,近邻图的更新方法是一个必须实现的方法,其直接影响向量数据库的适用范围。
2、文献“malkov y a,yashunin d a.efficient and robust approximate nearestneighbor search using hierarchical navigable small world graphs[j].ieeetransactions on pattern analysis and machine intelligence,2018,42(4):824-836.”提出了一种增量式的索引结构。它不断将数据集中的向量插入到近邻图中,并基于当前图选择出候选邻居集合,根据相对邻域图的选边策略消除所有三角形的最长边,将图的平均出度降低到与维数相关的常数,从而构成一个近邻图。hnsw算法提出mask方法进行删除,主要思路是对过期节点标记为已删除,当我们执行最佳优先搜索时,仍然会访问标记“删除”的顶点,从而保留原始近邻图的连通性。
3、文献“wang j,yi x,guo r,et al.milvus:apurpose-built vector datamanagement system[c]//sigmod/pods'21:international conference on managementof data.2021.”是一个专门构建的数据管理系统,用于有效管理大规模向量数据。milvus支持向量相似性搜索的简单和复杂查询处理,但是其核心索引结构不支持数据的动态变化,这极大限制了milvus的适用场景。
4、尽管文献“malkov y a,yashunin d a.efficient and robust approximatenearest neighbor search using hierarchical navigable small world graphs[j].ieee transactions on pattern analysis and machine intelligence,2018,42(4):824-836.”所述方法在搜索向量时表现出良好的性能,但无法很好地支持近邻图方法的更新。在现实应用中,数据库可以利用近邻图来维护特征向量之间的相似关系。随着时间的推移,这些特征向量需要进行调整。然而,基于近邻图的算法只能处理静态数据,无法支持现实场景中特征向量的动态变化。
技术实现思路
1、本发明要解决的技术问题是针对上述现有技术的不足,提供一种面向近似最近邻搜索的近邻图更新方法,以解决现有的近似最近邻搜索无法应对现实世界中用户与向量数据库系统交互所带来的数据更新问题。
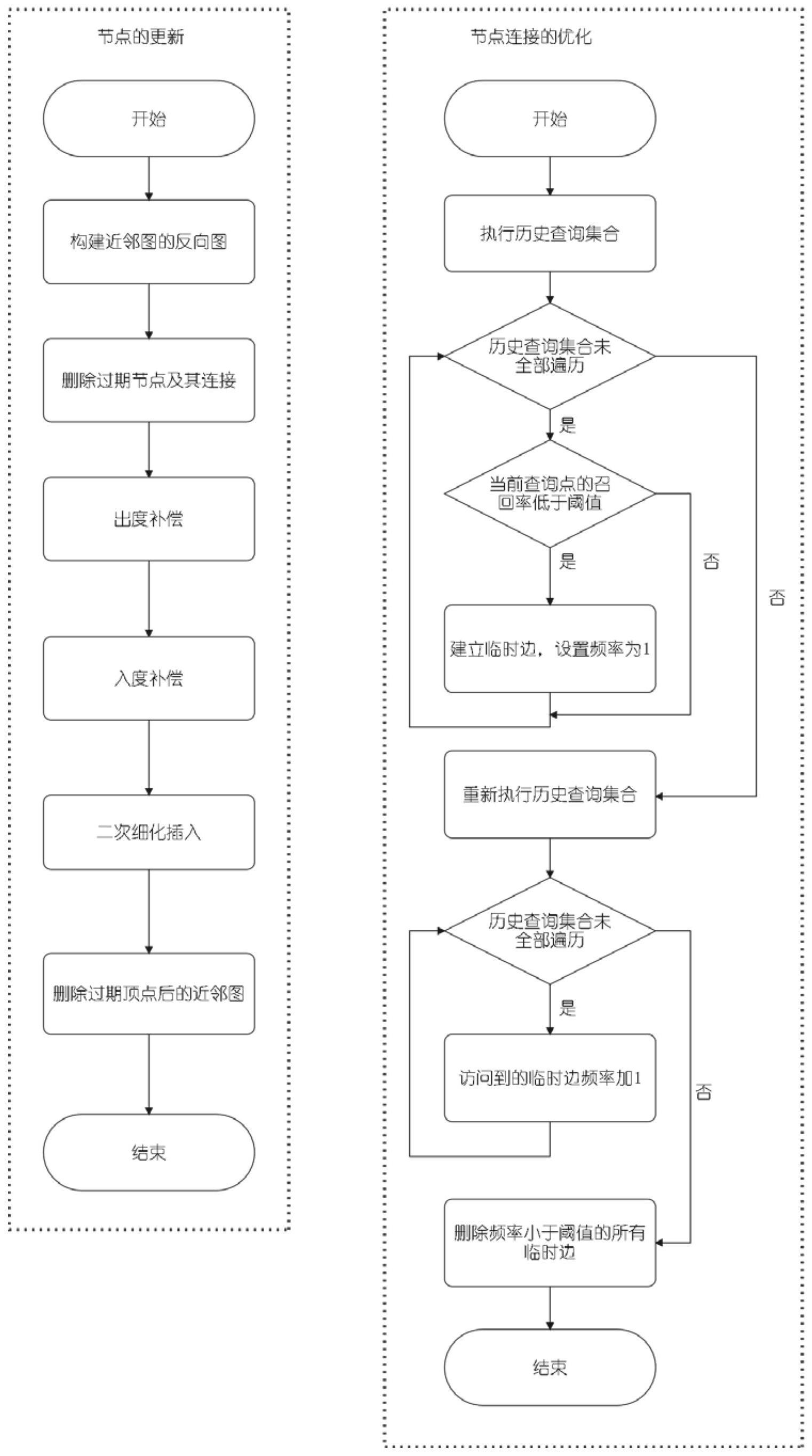
2、为解决上述技术问题,本发明所采取的技术方案是:一种面向近似最近邻搜索的近邻图更新方法,包括以下步骤:
3、步骤1:根据向量数据库系统内的数据序列,构建近邻图g及其反向图g′;
4、构建近邻图时,同时构建其反向图,用于获得近邻图中过期顶点的前驱邻居顶点的信息,即近邻图中每个顶点的前驱邻居顶点等于反向图中对应顶点的后继邻居顶点;
5、步骤2:删除近邻图中过期顶点及其连接边;
6、给定一个过期顶点ev,首先获得它的前驱邻居顶点集合nin(ev)和后继邻居顶点集合nout(ev);对于每个前驱邻居顶点pnj∈nin,在近邻图g上删除边<pnj,ev>,在反向图g′上删除边<ev,pnj>;对于每个后继邻居顶点snk∈nout,在近邻图g上删除边<ev,snk>,在反向图g′上删除边<snk,ev>;最后删除完过期顶点ev与所有前驱邻居和后继邻居构成的边,就得到了删除过期顶点之后的近邻图g和反向图g′;
7、步骤3:补偿过期顶点的前驱邻居顶点的出度;
8、首先在近邻图中获取过期顶点的所有前驱邻居顶点,其次,对于过期顶点的每个前驱邻居顶点,通过贪婪算法获取距离该前驱邻居顶点最近的l个顶点及其一阶邻域作为候选邻居集合,并按照距离利用优先队列对l个顶点进行升序排列,得到优先队列;
9、步骤4:基于最小角度最大化的边选择策略进行边的选择;
10、在边的选择阶段,首先使用二分算法,选择一个角度阈值;其次,从优先队列中依次取出距离最近的候选邻居,并计算顶点间的夹角;如果从优先队列中选择的顶点与近邻图中已经存在的邻居的最小夹角大于阈值,则将该顶点添加到邻居集合中;如果在该角度阈值上,不能选取设定数量的邻居顶点,这可能导致在某些方向上没有邻居;此时,应该减小角度阈值,并重新选取邻居顶点;如果在该角度阈值上,已经选取了设定数量的邻居,记录下当前角度阈值;此时,应该增大角度阈值,并重新选择邻居顶点;若增大角度后,仍能够选取设定数量的邻居,则说明角度阈值太小;否则,当前角度阈值即为最佳角度阈值;最后,输出在最佳角度阈值下产生的邻居顶点集合;
11、步骤5:补偿过期顶点的后继邻居顶点的入度;
12、将过期顶点的后继邻居顶点增加入度的问题,在反向近邻图中转化为了过期顶点的前驱邻居顶点增加出度的问题;具体来说,将反向图中的过期顶点的所有出度小于阈值的前驱邻居顶点视为新顶点重新插入到反向图中,并按照阈值确定新顶点的邻居个数;反向图所选择的邻居顶点的入度不能超过近邻图的最大出度限制;
13、步骤6:对插入的新顶点进行二次细化;
14、对插入的新顶点进行二次细化,即新插入的顶点到达设定数目之后,基于所有顶点为所有新插入的顶点重新选择邻居,进一步改善近邻图结构;
15、步骤7:基于历史查询优化近邻图结构;
16、首先计算近邻图的历史查询集合的召回率;如果历史查询集合某个查询点的召回率低于阈值,则将其作为临时点插入到近邻图中,并按照基于最小角度最大化的边选择策略为这些临时点选择邻居,并建立双向边;同时,将临时点的访问频率设置为1;由于临时点分布更接近查询点分布,临时点之间不能相互连接;接下来,重新执行历史查询;当访问到临时顶点的一阶邻域时,该临时顶点的访问频率加1;最后,删除访问频率低于设定阈值的所有临时顶点及其连接。
17、采用上述技术方案所产生的有益效果在于:本发明提供的一种面向近似最近邻搜索的近邻图更新方法,首先解决了hnsw的mask算法删除节点所带来的内存和效率问题。其次,通过设计最小角度最大化的边选择策略和历史查询引导的插入算法,解决了以往近邻图邻居节点分布不均匀和对数据集过拟合的问题,提高了搜索效率。最后,按照本发明提出的删除和插入方法消除了因更新带来的性能下降的问题,支持流式更新,避免了因更新而重建近邻图,这增大了向量数据库的适用范围。
18、本发明方法解决了anns现有图形算法仅支持静态索引的问题,无法反映许多关键现实场景所需的语料库实时变化。在这种情况下,保留过期节点会浪费时间,降低搜索精度和效率,并会产生内存问题,而移除这些节点及其边则会破坏图的连通性,导致搜索阶段效率低下。本发明通过更好的边补偿过期节点的近邻来保证近邻图的连通性,实现顶点信息的删除,同时通过更优的边选择策略和历史查询优化完成对新节点的插入,完成近邻图的更新,而不需要重新构建索引。这种更新算法可以实时将语料库更新反映到索引中,而不会影响搜索性能。
- 还没有人留言评论。精彩留言会获得点赞!