一种面向神经辐射场模型的数字水印方法
本发明涉及一种方法,具体为一种面向神经辐射场模型的数字水印方法,属于计算机。
背景技术:
1、基于隐式表示的3d渲染技术目前已经成为计算机视觉研究最热门的领域之一。神经隐式表达利用神经网络表示数据的思路,使得网络本身成为与数据等价的资产。可以预测,在不远的将来我们将看到更多的3d数据通过神经隐式表达的方式以神经网络的格式出现,保护隐式表示的3d数据的成为一个亟待解决的问题。
2、传统的3d水印根据嵌入方式不同,可以分为几何水印和拓扑水印。基于几何特征的3d数字水印是对3d形状进行平移、旋转、缩放等操作,在变换过程中嵌入水印信息。而基于拓扑特征的3d数字水印则针对模型间数据同步的问题,形成了一种基于拓扑不变量的鲁棒性水印。3d模型参数水印是一种基于定向权重的3d数字内容编辑技术,通常通过嵌入方向技术、权重嵌入技术和特征点插入技术来实现。3d模型参数水印具有隐蔽性强、嵌入信息容量大和操作简单的优势,但由于水印信息在参数中,从而存在水印的提取比较困难,提取的水印精度不够的问题,为此,提出一种面向神经辐射场模型的数字水印方法。
技术实现思路
1、有鉴于此,本发明提供一种面向神经辐射场模型的数字水印方法,以解决或缓解现有技术中存在的技术问题,至少提供一种有益的选择。
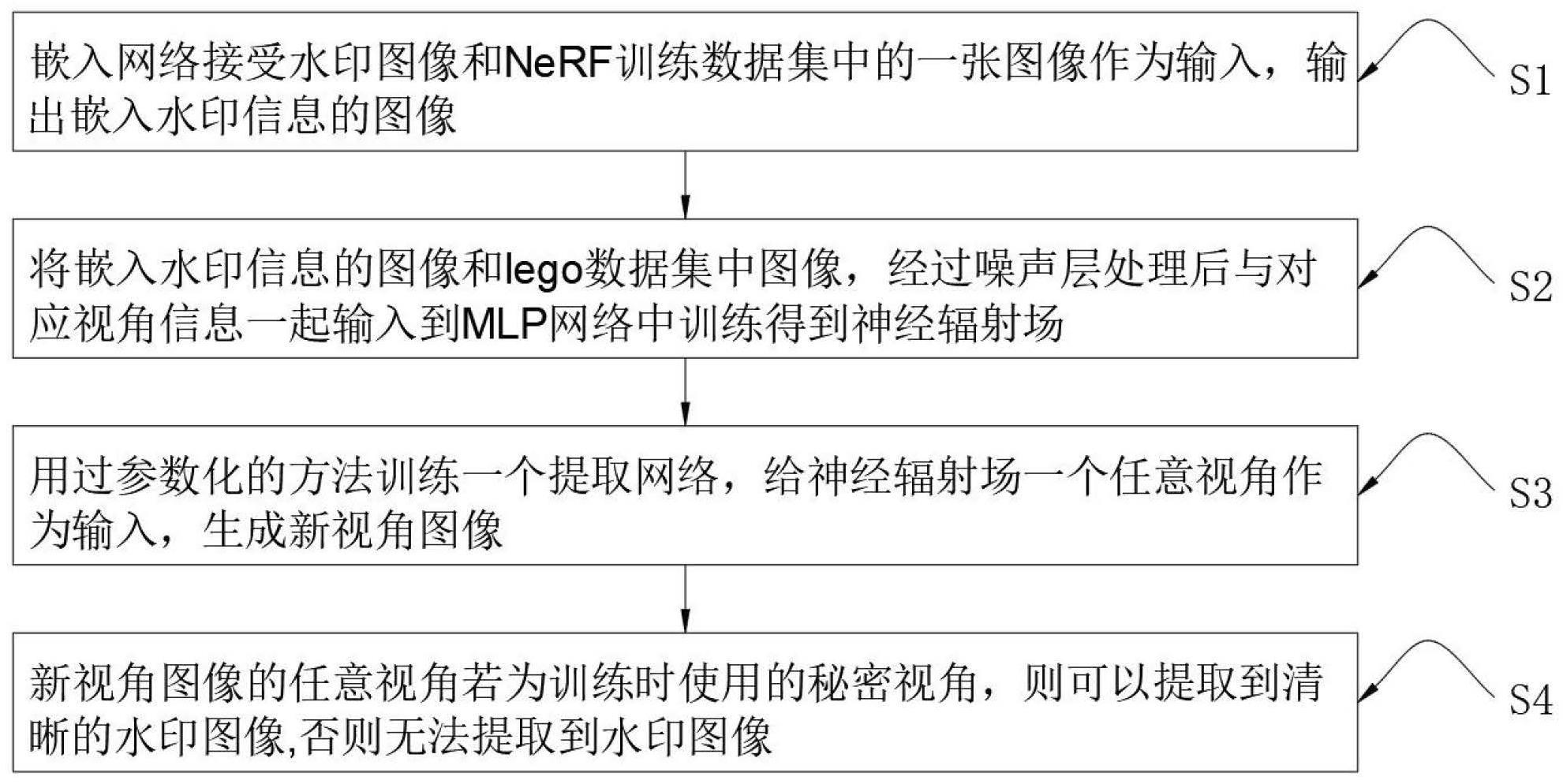
2、本发明实施例的技术方案是这样实现的:一种面向神经辐射场模型的数字水印方法,包括以下步骤:
3、s1:嵌入网络接受水印图像和nerf训练数据集中的一张图像作为输入,输出嵌入水印信息的图像;
4、s2:将嵌入水印信息的图像和lego数据集中图像,经过噪声层处理后与对应视角信息一起输入到mlp网络中训练得到神经辐射场;
5、s3:用过参数化的方法训练一个提取网络,给神经辐射场一个任意视角作为输入,生成新视角图像;
6、s4:新视角图像的任意视角若为训练时使用的秘密视角,则可以提取到清晰的水印图像,否则无法提取到水印图像,以此证明神经辐射场数据的所有权。
7、进一步优选的,在s1中,嵌入网络输入尺寸大小为3×w×h的水印信息和lego数据集中的图像k,将水印图像w也经过一个输出通道为32的卷积层conv得到尺寸大小32×w×h的特征图a,再将图像k经过一个输出通道为32的卷积层conv得到尺寸大小32×w×h的特征图b,特征图a和特征图b的公式为:
8、a=conv3->32(a)
9、b=conv3->32(k)
10、将特征图a和特征图b进行拼接后经过输出通道数为32的卷积层得到特征图c,特征图c的公式为:
11、c=conv32+32->32(cat(a,b))。
12、进一步优选的,在s1中,为充分提取图像特征,在提取网络中采用了密集连接技术,通过密集连接加强特征的传递,增强嵌入网络对图像深层次特征的提取能力,依次将a、b和c进行拼接经过卷积层得到特征图d,特征图d的公式为:
13、d=conv32+32+32->32(cat(a,b,c))
14、再将a、b、c和d拼接经过输出通道为3的卷积层,输出与图像k一样大小的图像k’,k’的公式为:
15、k'=conv32+32+32+32->3(cat(a,b,c,d))
16、嵌入网络中,卷积核大小为3×3,步长为1,填充为1,使用relu作为激活函数再使用bn(batch normalization)层对数据进行归一化处理。
17、进一步优选的,在s2中,引入噪声层对模型进行处理,对构建模型的输入数据添加噪声以模拟对网络参数本身的修改;模拟nerf受到噪声攻击的过程,设置高斯噪声、椒盐噪声、speckle噪声、泊松噪声以模拟不同类型的失真。
18、进一步优选的,在s3中,提取网络输入尺寸3×w×h图像s,经过一个输出通道为32的卷积层得到特征图e,e经过一次卷积得到特征图f,将e和f拼接得到特征图g,再将e、f、g拼接并进行一次卷积后得到清晰水印图像w’,基本流程如下式所示:
19、e=conv3->32(s)
20、f=conv32->32(e)
21、g=conv32+32->32(cat(e,f))
22、w'=conv32+32+32->d(cat(e,f,g))
23、提取网络卷积核设置与嵌入网络相同,最后一层卷积后输出3×w×h的水印图像;训练好提取网络后,保存模型参数,输入经过nerf其他视角生成的图像则无法提取水印图像。
24、进一步优选的,在s4中,在nerf中输入空间点的3d坐标位置x=(x,y,z)和方向d=(θ,φ),输出空间点的颜色c=(r,g,b)和对应位置的密度σ;
25、先对x和d进行位置信息编码,再将x输入到mlp网络中,并输出σ和一个256维的中间特征,中间特征和d再一起输入到全连接层中预测颜色,最后通过体渲染生成2d图像。
26、进一步优选的,在s4中,利用三维重建得到的3d点的像素值c和体密度σ,沿着观测方向上的一条射线进行像素点采样加权叠加得到最终的2d图像像素值,公式为:
27、
28、式中,r(t)为根据相机光心位置o及视角方向d得到的一条射线r(t)=o+td,t(t)表示该射线从近端tn到远端边界tf这段路径上的累计透光度。
29、进一步优选的,在s4中,训练过程中将体渲染得到的像素点与原视角图像作均方误差l2对网络进行优化,采用分级表征渲染的思想以提高渲染效率,即同时优化粗网络cc(r)和细网络cf(r),以利用粗网络的权值分布更好地在细网络中分配样本;
30、
31、式中,r表示输入视图中所有的光线,c(r)表示输入视图的真实像素值,表示预测像素值;
32、选取一个特定视角的相机参数m作为密钥,把相机坐标系下的点变换到世界坐标系下,将相机坐标系下的3d坐标映射到2d的图像平面。
33、进一步优选的,在s4中,通过损失函数来衡量预测值与真实值之间差异,损失函数主要包括两个部分,载体图像内容损失le和水印图像内容损失ld;
34、le为载体图像和包含水印图像的均方误差,公式为:
35、
36、其中,α为权重参数,k为载体图像,k’为包含水印图像。
37、进一步优选的,在s4中,ld为水印图像内容损失,公式如下:
38、
39、式中β,γ和μ为权重参数,w为原始水印图像,w’为提取的水印图像。lssim为结构相似性ssim损失,lmsssim为多尺度结构相似性ms-ssim损失。
40、ssim和ms-ssim的计算公式如下所示:
41、
42、
43、上述式中μx和σx分别为图像x的均值和方差,μy和σy分别为图像y的均值和方差,σxy为x和y的协方差;m表示不同尺度,βm和γm表示图像之间的相对重要性,βm=γm=1,c1,c2为常数,k1默认取值0.01,k2取值0.03,l为像素值的动态范围,取值为255。
44、本发明实施例由于采用以上技术方案,其具有以下优点:
45、一、本发明通过将面向神经辐射场的3d模型水印算法看作是一种特殊的神经网络模型水印,设计实现了一个黑盒模型水印算法,实现了对隐式表示的3d模型版权的保护;运用过参数化的方法,通过训练一个简单的网络实现特定视角渲染图像的水印提取;
46、二、本发明利用nerf模型的视角输入,将秘密视角作为水印提取的密钥信息,由于新视角合成的连续性,巨大的密钥空间,保障了水印信息的安全;通过引入对训练图像的噪声层,模拟了对隐式表达网络的噪声处理,使得该方法具有鲁棒性。
47、上述概述仅仅是为了说明书的目的,并不意图以任何方式进行限制。除上述描述的示意性的方面、实施方式和特征之外,通过参考附图和以下的详细描述,本发明进一步的方面、实施方式和特征将会是容易明白的。
- 还没有人留言评论。精彩留言会获得点赞!