一种基于改进密度峰的图像聚类方法及系统
本发明涉及图像数据处理,具体涉及一种基于改进密度峰的图像聚类方法及系统。
背景技术:
1、聚类分析方法是一种无监督学习方法,是机器学习和数据挖掘领域的重要研究方向之一。近年来,聚类分析方法已成功应用于图像处理领域中,例如图像分割、图像识别、图像去噪,而实现上述图像处理功能的关键点在于对图像数据进行聚类。
2、现有技术中在对图像数据进行聚类时,聚类的结果通常依赖于初始聚类中心的选择,不同的初始聚类中心会产生不同的聚类结果。密度峰值聚类是一种基于密度的聚类方法,可以解决上述问题。
3、但密度峰值聚类算法存在一些缺陷:
4、首先,在密度不均匀的数据集上,该算法的聚类效果较差;
5、其次,决策图中选择聚类中心需要人工参与,这增加了算法的主观性:
6、此外,逐点式的分配策略容易引起一个样本点被错误分配将可能导致大量的样本点错误分配的类似“多米诺骨牌效应”的连锁反应;
7、这些缺陷使得密度峰值聚类算法在实际生产中很难发挥出很好的作用。
技术实现思路
1、本发明实现一种利用密度峰聚类算法进行图像处理的方法,并克服密度峰聚类算法在密度不均匀数据集上聚类效果较差、需要人工参与和分配策略易出错的问题。
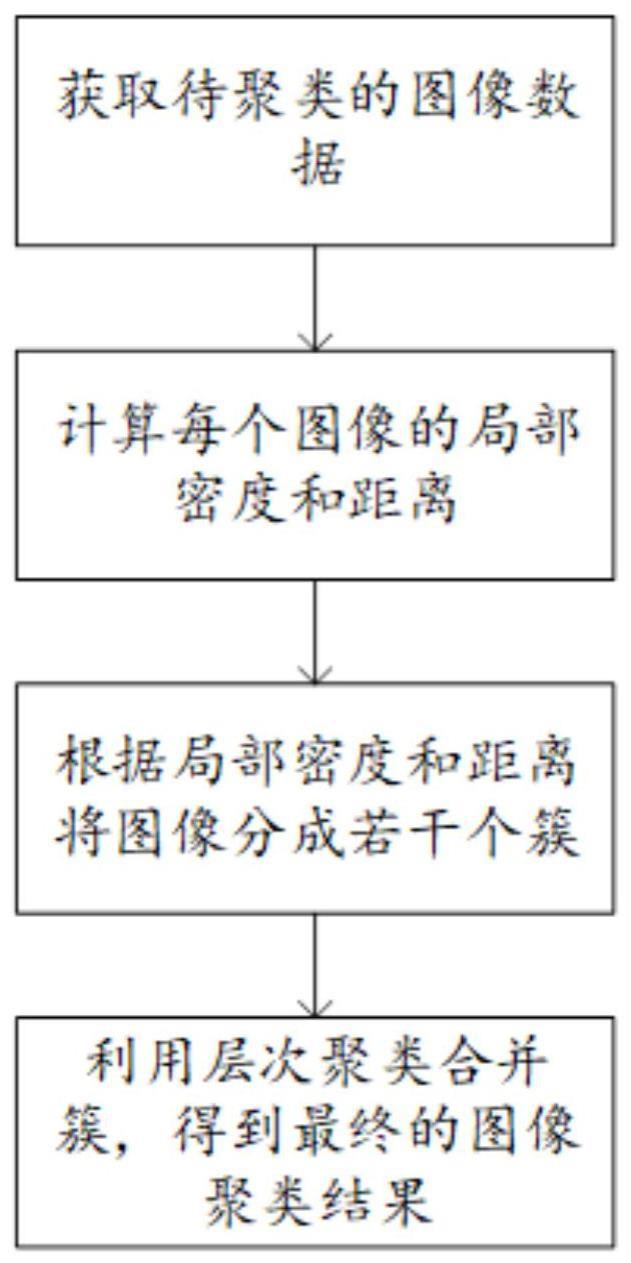
2、为了实现上述目的,本发明采用的技术方案为:一种基于改进密度峰的图像聚类方法,包括以下步骤:
3、步骤1、获取待聚类的图像数据;
4、步骤2、计算每个图像数据的局部密度和距离;
5、步骤3、根据局部密度和距离,将图像分成若干个簇;
6、步骤4、利用层次聚类合并簇,得到最终的图像聚类结果。
7、所述步骤1中,假设所有图像的像素均为g×m,将第1张图像进行灰度化处理,形成大小为g×m的矩阵x1=(x1,x2,...,xm),对剩余的n-1张图像做相同的处理,形成大小为n×m的图像样本集x={x1,x2,…,xn},x1,x2,…,xn表示样本点。
8、所述步骤2中,根据步骤1得到的图像样本集x,首先计算每个样本点的k近邻集,进而获得每个样本的k互近邻集和非k互近邻集,依据每个样本点k互近邻集和非k互近邻集来计算局部密度和距离。
9、所述步骤2包括以下步骤:
10、步骤2.1:对于大小为n×m的图像样本集,记作x={x1,x2,…,xn},计算任意两个样本点xi和xj间的欧式距离:
11、
12、步骤2.2:根据步骤2.1计算得到的欧式距离值,计算每个样本点的k近邻集,k近邻集的定义如下:
13、knn(xi)={xj∈x|d(xi,xj)≤d(xi,xk)}
14、其中,xk是xi第k近的样本点;
15、步骤2.3:根据k近邻集来计算每个样本点的k互近邻集和非k互近邻集,样本点xi的k互近邻集mnn(xi)定义为:
16、mnn(xi)={xj|xj∈knn(xi),xi∈knn(xj)}
17、样本点xi的非k互近邻集nmnn(xi)定义为:
18、
19、步骤2.4:根据k互近邻集和非k互近邻集来计算每个样本点的局部密度,样本点xi的局部密度定义为:
20、
21、步骤2.5:根据k互近邻集和非k互近邻集来计算每个样本点的距离,样本点xi的距离定义为:
22、
23、其中,
24、
25、所述步骤3中,根据步骤2得到的局部密度和距离计算决策值,将决策值不为零的样本点定义聚类中心,再对剩余样本点进行分配。
26、所述步骤3包括以下步骤:
27、步骤3.1:根据步骤1得到的局部密度和距离计算每个样本点的决策值,样本点xi的决策值定义为:
28、γi=ρiδi
29、步骤3.2:将决策值γi不为零的样本点记为聚类中心,假设聚类中心的个数为m,其中,m>c,c是样本的类别数,聚类中心记作cl={cl1,cl2,…,clm}
30、步骤3.3:根据步骤3.2得到的聚类中心cl={cl1,cl2,…,clm},按照原始密度峰值聚类算法的分配策略,将剩余样本点分配到局部密度比它大的最近样本点所在的簇中,得到m个簇,记为cluster={cluster1,cluster2,…,clusterm}。
31、所述步骤4中,利用层次聚类算法对步骤3得到的m个聚类中心进行聚类,同时合并簇,得到最终聚类结果。
32、所述步骤4包括以下步骤:
33、步骤4.1:根据步骤3得到的聚类中心cl={cl1,cl2,…,clm},初始化,令di={cli};
34、步骤4.2:计算di和dj间的相似度:
35、
36、其中,p表示di集合元素的个数,q表示dj集合元素的个数;
37、步骤4.3:假设sij是s中值最大的元素,合并聚类中心cli和clj对应的簇clusteri和clusterj,同时di={cli,clj},簇的数量减少为m-1;
38、步骤4.4:重复步骤4.2和4.3,直到簇的数量减少至c,得到最终的图像聚类结果。
39、一种基于改进密度峰的图像聚类系统,包括处理器和存储器,所述存储器上存储有所述基于改进密度峰的图像聚类方法的计算机可读指令,所述处理器连接处理器并执行计算机可读指令。
40、本发明基于改进密度峰的图像聚类方法,包括基于k互近邻重新定义局部密度和距离,增强算法在密度不均匀数据集上的聚类效果,利用层次聚类,避免聚类中心点的选取和类似“多米诺骨牌效应”的连锁反应,克服了密度峰聚类算法的主要缺陷,包括在密度不均匀的数据集上,该算法的聚类效果较差,决策图中选择聚类中心需要人工参与,逐点式的分配策略容易引起一个样本点被错误分配将可能导致大量的样本点错误分配的连锁反应等问题。
技术特征:
1.一种基于改进密度峰的图像聚类方法,其特征在于,包括以下步骤:
2.根据权利要求1所述基于改进密度峰的图像聚类方法,其特征在于:所述步骤1中,假设所有图像的像素均为g×m,将第1张图像进行灰度化处理,形成大小为g×m的矩阵x1=(x1,x2,...,xm),对剩余的n-1张图像做相同的处理,形成大小为n×m的图像样本集x={x1,x2,…,xn},x1,x2,…,xn表示样本点。
3.根据权利要求2所述基于改进密度峰的图像聚类方法,其特征在于:所述步骤2中,根据步骤1得到的图像样本集x,首先计算每个样本点的k近邻集,进而获得每个样本的k互近邻集和非k互近邻集,依据每个样本点k互近邻集和非k互近邻集来计算局部密度和距离。
4.根据权利要求3所述基于改进密度峰的图像聚类方法,其特征在于:所述步骤2包括以下步骤:
5.根据权利要求4所述基于改进密度峰的图像聚类方法,其特征在于:所述步骤3中,根据步骤2得到的局部密度和距离计算决策值,将决策值不为零的样本点定义聚类中心,再对剩余样本点进行分配。
6.根据权利要求5所述基于改进密度峰的图像聚类方法,其特征在于:所述步骤3包括以下步骤:
7.根据权利要求6所述基于改进密度峰的图像聚类方法,其特征在于:所述步骤4中,利用层次聚类算法对步骤3得到的m个聚类中心进行聚类,同时合并簇,得到最终聚类结果。
8.根据权利要求7所述基于改进密度峰的图像聚类方法,其特征在于:所述步骤4包括以下步骤:
9.一种基于改进密度峰的图像聚类系统,其特征在于:包括处理器和存储器,所述存储器上存储有如权利要求1-8中所述基于改进密度峰的图像聚类方法的计算机可读指令,所述处理器连接处理器并执行计算机可读指令。
技术总结
本发明揭示了利用密度峰聚类算法进行图像处理的方法和系统,包括如下步骤:S1、获取待聚类的图像数据;S2、计算每个图像数据的局部密度和距离;S3、根据图像的局部密度和距离将图像划分为若干簇;S4、利用层次聚类合并簇,得到最终的图像聚类结果。上述方案无需指定初始图像数据(即初始聚类中心),聚类结果也与选取的初始图像数据无关,因此可以解决现有技术中在对图像数据进行聚类时,因初始聚类中心选择不合理导致图像处理失败的问题。
技术研发人员:黄帆,孙丽萍,郑子昂,任威,罗永龙
受保护的技术使用者:安徽师范大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!