一种基于改进型FocalLoss函数的多分类目标检测分割方法及设备与流程
本发明属于机器学习,具体来说是一种基于改进型focalloss函数的多分类目标检测分割方法及设备。
背景技术:
1、在在目标检测和语义分割任务中,根据数据的分布情况可选择恰当的损失函数网络输出和标签进行数值运算,以达到较优的训练效果。特别地,在数据样本不均衡以及样本难易程度不同时,采用classaware-focalloss能起到事半功倍的效果。classaware-focalloss由focalloss改进而来,focalloss由crossentropyloss和binarycrossentropy改进而来,因此首先介绍crossentropyloss,binarycrossentropy和focalloss的功能原理和特点。
2、1、crossentropyloss
3、交叉熵衡量的是两个分布之间的距离,因此可以被用来刻画预测值和标签值的差异情况,主要用于多分类任务,公式如下:
4、
5、其中,n为样本个数,yi为第i个样本的标签真值,pyi’为一个样本的模型输出做了softmax之后的预测值。yi由于是one-hot编码(0001000...),只在真值类别的位置为1,其余位置为0,因此实际计算时,只有为正样本的预测概率值会与1相乘,其余位置的预测概率值与0相乘就省略计算了。
6、2、binarycrossentropy(bce)
7、二进制交叉熵函数衡量预测值和真值差异,主要用于2分类任务,当用于多分类(类别为c)任务时,其实是进行了c个2分类任务。bce公式如下:
8、loss-(ylog(p(x)+(1-y)log(1-p(x))
9、其中p(x)为模型的预测输出并经过了sigmoid函数后的值,由于bce是二分类,只关于正负样本且正负样本和为1,因此经过sigmoid函数后成为预测概率值。y为真值,仅为0或1,对应正样本或负样本。当做二分类时,p(x)维度为(n,1),y维度为(n,1),其中n为样本个数;当采用bce做多分类时,p(x)维度为(n,c),y维度为(n,c),其中n为样本个数,c为类别数,y是真值标签做了one-hot编码之后形成的(n,c),相当于对每一个样本的每一个类别位置上独立地做二分类,再将所有样本的所有位置求平均值就是多分类的loss函数。
10、bce与ce不同的是:在每个样本的每个位置上,-ylog(y^hat)-(1-y)log(1-y^hat),y为0或1都参与计算。而ce这个函数实际上只是在对相gt为1的那个位置的值做约束,希望这一点的预测输出能可能为1;而其他原本gt为0的位置因为y=0,在计算到求和中的时候无论其相应输出位置的值是多少都没有关系而被省略。
11、由于ce之前还有softmax这个函数,这个函数会让输入的n个类别位置中预测值大的更大,小的更小,并且可以确保最终所有节点的输出的总和为1,这样一来只要对应gt=1的那个节点输出足够靠近1,其他的节点自然输出就会趋近于0了。
12、3、focalloss
13、focalloss是针对训练样本不平衡以及样本难易程度不同提出的,是交叉熵损失函数的变种。公式如下:
14、fl(pt)=-αt((1-pt)γlog(pt)
15、其中,log(pt)部分就是二进制交叉熵的计算,α的作用是给正负样本loss加权重,正样本少,就加大正样本loss的权重,负样本多,降低负样本的loss权重;而γ的作用是,当样本预测值pt比较大时,也就是易分样本,(1-pt)会很小,这样易分样本的loss会显著减小,反之当预测值pt比较小时,也就是难分样本,(1-pt)会很大,这样难分样本的loss会显著增大。于是模型会更关注难分样本loss的优化。
16、focalloss自始至终只用了二分类的交叉熵,当完成多分类任务时,目标类别个数设为c。focal loss是对每个样本的每个类别位置都进行了一次二分类,再将结果求加或者求平均值。也就是说:focal loss提到的解决样本分类不平衡的问题仅仅是将所有样本的所有类别位置看成二分类问题,α也只针对0或1(正或负样本)进行加权,只区分0-1的正负样本问题,这个α所谓解决类别不平衡其实是针对0和1而言的,不是针对c个类别。因此,focal loss并没有解决检测或者分割任务中,目标有多个类别且类别个数不平衡的问题。
技术实现思路
1、1.发明要解决的技术问题
2、本发明提出一种改进的对类别有意识的focalloss函数,该不仅类似focalloss解决了难易样本问题,解决了0-1分类问题(即背景和前景问题),还在此基础上进一步解决了目标的不同类别的不平衡问题。
3、2.技术方案
4、为达到上述目的,本发明提供的技术方案为:
5、本发明的一种基于改进型focalloss函数的多分类目标检测分割方法,所述方法采用的函数为
6、classawarefl(pt)=-βcαt(1-pt)γlog(pt)
7、其中,pt为正或负样本概率值,log(pt)为bce的结果;
8、t取值为0或1,表示这个p是正样本或负样本;
9、α根据t而决定是正样本因子或负样本因子,γ为难易程度的放大系数;
10、c表示目标类别;
11、新增的βc权重项为根据数据集的统计结果,将所有的检测目标个数按从小到大的顺序排列,根据个数设置目标类别的权重因子,个数大的类别权重小,个数小的类别权重大,设置好的权重因子顺序存储到一个列表中。
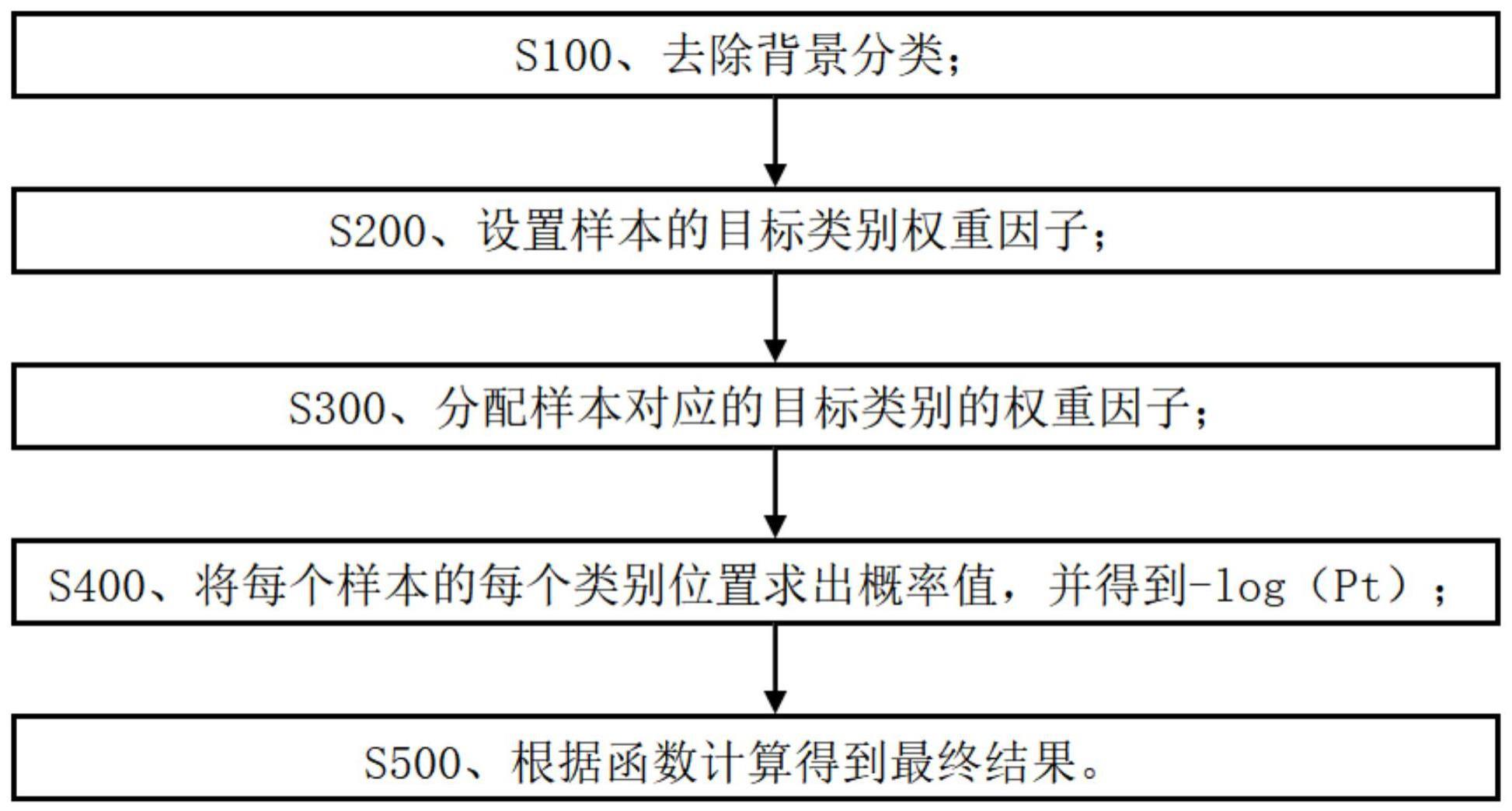
12、一种基于改进型focalloss函数的多分类目标检测分割方法,所述方法步骤如下:
13、s100、去除背景分类;
14、s200、设置样本的目标类别权重因子;
15、s300、分配样本对应的目标类别的权重因子;
16、s400、将每个样本的每个类别位置求出概率值,并得到-log(pt);
17、s500、根据函数计算得到最终结果。
18、优选的,所述步骤s100具体为:
19、确定目标类别个数为c,背景为一个别类,总类别个数为c+1;
20、确定标签真值维度为(n),n的取值范围0-c的整数;
21、将标签真值onehot之后把[-1]项去掉,即去掉背景分类;保存onehot之后标签真值作为后续focal loss部分的输入项,也保存未onehot的真值,用target表示,主要为样本的目标分配对应的类别权重因子。
22、优选的,所述步骤s200具体为:
23、根据数据集目标类别的分布情况,设置目标类别权重因子,类别个数大的权重因子小,类别个数小的权重因子大,将权重因子按类别顺序保存到列表中。
24、优选的,所述步骤s300具体为:
25、为一个batch(批量)的所有样本的分配目标类别的权重因子,在权重列表中索引每个目标的类别值(保存在target中),就得到了每个样本对应的目标类别权重因子βc。
26、优选的,所述步骤s400具体为:
27、将每个样本的每个类别位置求出概率值,与步骤s100中onehot对应位置做bec得到-log(pt),其中t取值为0或1,p表示是正样本还是负样本。
28、优选的,所述步骤s500具体为:
29、根据步骤s400中的-log(pt)确定α和γ,所述α根据t而决定是正样本因子或负样本因子,γ为难易程度的放大系数;
30、将参数代入所述改进型focalloss函数计算得到最终结果。
31、一种电子设备,包括:至少一个处理器和存储器;其中,所述存储器存储有计算机执行指令;在所述至少一个处理器执行所述存储器存储的计算机执行指令,使得所述至少一个处理器执行所述的多分类目标检测分割方法。
32、一种计算机可读存储介质,其上存储有计算机程序,在所述计算机程序被处理器运行时控制所述存储介质所在设备执行所述的多分类目标检测分割方法。
33、3.有益效果
34、采用本发明提供的技术方案,与现有技术相比,具有如下有益效果:
35、本发明的一种基于改进型focalloss函数的多分类目标检测分割方法,所述方法步骤如下:s100、去除背景分类;s200、设置样本的目标类别权重因子;s300、分配样本对应的目标类别的权重因子;s400、将每个样本的每个类别位置求出概率值,并得到-log(pt);s500、根据函数计算得到最终结果。本发明可以解决当数据集目标基数达到一定程度时,让较少个数的类别目标被重视,在不影响原有的正负样本平衡和难易平衡的规律下,进一步提升较少个数的类别目标的检测率和分割率。
- 还没有人留言评论。精彩留言会获得点赞!