用于训练自然语言处理模型的方法和计算机系统与流程
本申请涉及人工智能技术,特别涉及用于训练自然语言处理模型的方法、计算机系统和用于实施该方法的非暂时性计算机可读存储介质。
背景技术:
1、近年来,业界在自然语言处理领域已经取得了重大突破。训练样本的数量和质量是决定自然语言处理模型性能优劣的重要因素,然而在一些应用场合,受制于场景自身的特点,难以获取足够数量的数据样本,并且数据类型也较为单一,这些将导致模型训练不充分和过拟合等情况。
技术实现思路
1、本申请的一个目的是提供一种用于训练自然语言处理模型的方法和计算机系统,其可在训练样本数量较少的情况下得到高性能的自然语言处理模型。
2、按照本申请的一个方面,提供一种用于训练自然语言处理模型的方法,包括:
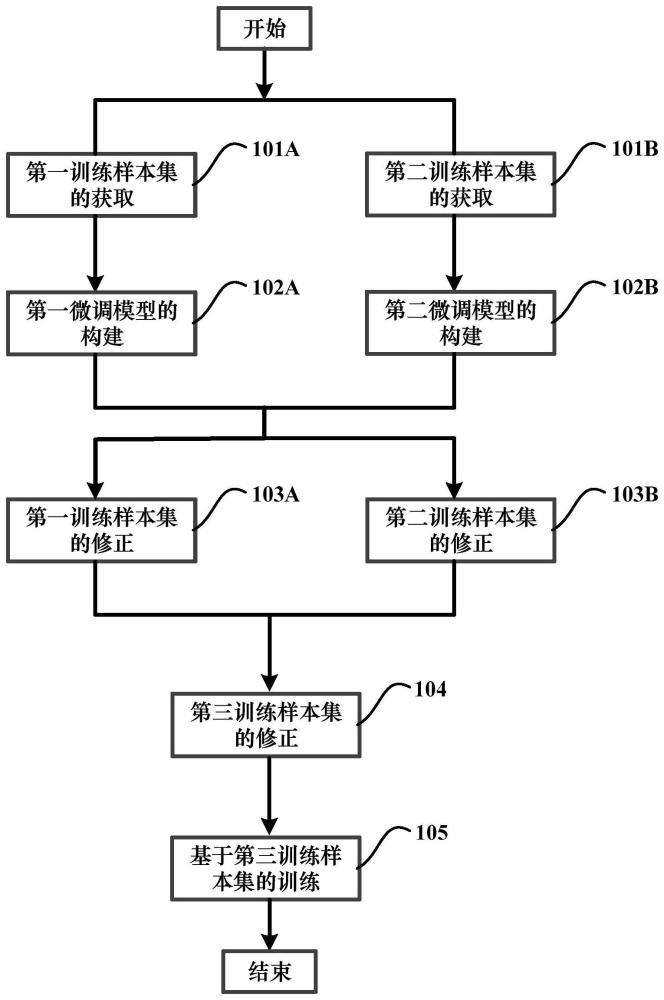
3、获取第一训练样本集;
4、获取第二训练样本集;
5、利用所述第一训练样本集来训练第一自然语言处理模型以得到第一微调模型;
6、利用所述第二训练样本集来训练所述第一自然语言处理模型以得到第二微调模型;
7、利用所述第一微调模型对所述第二训练样本集进行处理以得到经过修正的第二训练样本集;
8、利用所述第二微调模型对所述第一训练样本集进行处理以得到经过修正的第一训练样本集;以及
9、利用第三训练样本集来训练所述第一自然语言处理模型,其中,所述第三训练样本集至少包含所述经过修正的第一训练样本集和所述经过修正的第二训练样本集。
10、可选地,在上述方法中,获取所述第一训练样本集的步骤包括:
11、接收第一情境学习任务指令和第一数据样本;
12、利用第二自然语言处理模型,基于所述第一情境学习任务指令对所述第一数据样本进行分类处理,其中,所述第二自然语言处理模型的泛化能力高于所述第一自然语言处理模型的泛化能力;
13、将经过分类处理的所述第一数据样本作为所述第一训练样本集。
14、可选地,在上述方法中,所述第一情境学习任务指令包含第一标注类型和关于所述第一标注类型的描述,所述分类处理的结果为所述第一数据样本对应的第一标注类型。
15、可选地,在上述方法中,对所述第一数据样本进行分类处理的步骤包括:
16、如果由所述第二自然语言处理模型确定的与所述第一数据样本相对应的第一标注类型包含在所述第一情境学习任务指令中,则以确定的第一标注类型对第一数据样本进行标注;
17、如果由所述第二自然语言处理模型确定的与所述第一数据样本相对应的第一标注类型未包含在所述第一情境学习任务指令中,则接收更新后的第一情境学习任务指令,其中,更新后的第一情境学习任务指令包含该未包含的第一标注类型及其描述;
18、利用所述第二自然语言处理模型,基于更新后的第一情境学习任务指令对所述第一数据样本再次进行分类处理;
19、将经过再次分类处理的所述第一数据样本作为所述第一训练样本集。
20、可选地,在上述方法中,获取所述第二训练样本集的步骤包括:
21、接收第二情境学习任务指令;
22、利用第二自然语言处理模型,基于所述第二情境学习任务指令生成第二数据样本;
23、基于所生成的第二数据样本确定所述第二训练样本集。
24、可选地,在上述方法中,所述第二情境学习任务指令包含关键词、第二标注类型和关于所述第二标注类型的描述,所述第二数据样本具有相应的第二标注类型。
25、可选地,在上述方法中,所述第一情景学习任务指令和所述第二情境学习任务指令涉及用户评论分析场景,所述第一数据样本和所述第二数据样本为用户评论文本。
26、可选地,在上述方法中,所述第一标注类型与所述第二标注类型至少部分相同。
27、可选地,在上述方法中,利用所述第一微调模型对所述第二训练样本集进行处理的步骤包括:
28、利用所述第一微调模型对所述第二训练样本集进行分类处理;
29、从所述第二训练样本集中剔除标注类型与所述第一微调模型确定的分类处理结果不一致的数据样本以得到经过修正的第二训练样本集。
30、可选地,在上述方法中,利用所述第二微调模型对所述第一训练样本集进行处理的步骤包括:
31、利用所述第二微调模型对所述第一训练样本集进行分类处理;
32、从所述第一训练样本集中剔除标注类型与所述第二微调模型确定的分类处理结果不一致的数据样本以得到经过修正的第一训练样本集。
33、可选地,在上述方法中,所述第三训练样本集还包含从所述第一训练样本集和所述第二训练样本集中剔除的、经过人工标注的数据样本。
34、可选地,在上述方法中,所述第一训练样本集和第二训练样本集包含的样本数量在103~104的数量级。
35、可选地,在上述方法中,所述第一自然语言处理模型的参数数量在109~1010的数量级,所述第二自然语言处理模型的参数数量在1012~1013的数量级。
36、按照本申请还有一个方面,提供一种用于训练自然语言处理模型的计算机系统,包括一个或多个服务器,每个服务器包括:
37、至少一个存储器;
38、至少一个处理器;以及
39、存储在所述存储器上并可在所述处理器上运行的计算机程序,该计算机程序在一个或多个服务器的处理器上的运行导致下列操作:
40、获取第一训练样本集;
41、获取第二训练样本集;
42、利用所述第一训练样本集来训练第一自然语言处理模型以得到第一微调模型;
43、利用所述第二训练样本集来训练所述第一自然语言处理模型以得到第二微调模型;
44、利用所述第一微调模型对所述第二训练样本集进行处理以得到经过修正的第二训练样本集;
45、利用所述第二微调模型对所述第一训练样本集进行处理以得到经过修正的第一训练样本集;以及
46、利用第三训练样本集来训练所述第一自然语言处理模型,其中,所述第三训练样本集至少包含所述经过修正的第一训练样本集和所述经过修正的第二训练样本集。
47、按照本申请还有一个方面,提供一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,其特征在于,通过由处理器执行所述指令来实现如上所述的方法。
48、在本申请的一些实施例中,通过引入具有较强泛化能力的大语言模型来生成数据样本,可以弥补训练样本数量不足的缺憾。在本申请的另外一些实施例中,通过借助于具有较强泛化能力的大语言模型对从实际应用场景获取的训练样本集进行标注来减少标注工作量。在本申请的还要一些实施例中,还通过“交叉”方式来微调处理从实际应用场景获取的训练样本集和由强泛化能力的大语言模型生成的训练样本集,进一步提高了训练样本的质量。
技术特征:
1.一种用于训练自然语言处理模型的方法,包括:
2.如权利要求1所述的方法,其中,获取所述第一训练样本集的步骤包括:
3.如权利要求2所述的方法,其中,所述第一情境学习任务指令包含第一标注类型和关于所述第一标注类型的描述,所述分类处理的结果为所述第一数据样本对应的第一标注类型。
4.如权利要求3所述的方法,其中,对所述第一数据样本进行分类处理的步骤包括:
5.如权利要求2所述的方法,其中,获取所述第二训练样本集的步骤包括:
6.如权利要求5所述的方法,其中,所述第二情境学习任务指令包含关键词、第二标注类型和关于所述第二标注类型的描述,所述第二数据样本具有相应的第二标注类型。
7.如权利要求5所述的方法,其中,所述第一情景学习任务指令和所述第二情境学习任务指令涉及用户评论分析场景,所述第一数据样本和所述第二数据样本为用户评论文本。
8.如权利要求5所述的方法,其中,所述第一标注类型与所述第二标注类型至少部分相同。
9.如权利要求5所述的方法,其中,利用所述第一微调模型对所述第二训练样本集进行处理的步骤包括:
10.如权利要求9所述的方法,其中,利用所述第二微调模型对所述第一训练样本集进行处理的步骤包括:
11.如权利要求10所述的方法,其中,所述第三训练样本集还包含从所述第一训练样本集和所述第二训练样本集中剔除的、经过人工标注的数据样本。
12.一种计算机系统,包括一个或多个服务器,每个服务器包括:
13.如权利要求12所述的计算机系统,其中,所述计算机程序在一个或多个服务器的处理器上的运行使得按照下列方式获取所述第一训练样本集:
14.如权利要求13所述的计算机系统,其中,所述第一情境学习任务指令包含第一标注类型和关于所述第一标注类型的描述,所述分类处理的结果为所述第一数据样本对应的第一标注类型。
15.如权利要求14所述的计算机系统,其中,所述计算机程序在一个或多个服务器的处理器上的运行使得按照下列方式对所述第一数据样本进行分类处理:
16.如权利要求13所述的计算机系统,其中,所述计算机程序在一个或多个服务器的处理器上的运行使得按照下列方式获取所述第二训练样本集:
17.如权利要求16所述的计算机系统,其中,所述第二情境学习任务指令包含关键词、第二标注类型和关于所述第二标注类型的描述,所述第二数据样本具有相应的第二标注类型。
18.如权利要求16所述的计算机系统,其中,所述第一情景学习任务指令和所述第二情境学习任务指令涉及用户评论分析场景,所述第一数据样本和所述第二数据样本为用户评论文本。
19.如权利要求16所述的计算机系统,其中,所述第一标注类型与所述第二标注类型至少部分相同。
20.如权利要求16所述的计算机系统,其中,所述计算机程序在一个或多个服务器的处理器上的运行使得按照下列方式利用所述第一微调模型对所述第二训练样本集进行处理:
21.如权利要求20所述的计算机系统,其中,所述计算机程序在一个或多个服务器的处理器上的运行使得按照下列方式利用所述第二微调模型对所述第一训练样本集进行处理:
22.如权利要求21所述的计算机系统,其中,所述第三训练样本集还包含从所述第一训练样本集和所述第二训练样本集中剔除的、经过人工标注的数据样本。
23.一种非暂时性计算机可读存储介质,所述计算机可读存储介质中存储有指令,其特征在于,通过由处理器执行所述指令来实现如权利要求1-12中任意一项所述的方法。
技术总结
本申请涉及人工智能技术,特别涉及用于训练自然语言处理模型的方法、计算机系统和用于实施该方法的非暂时性计算机可读存储介质。按照本申请的一个方面,提供一种用于训练自然语言处理模型的方法包括:获取第一训练样本集;获取第二训练样本集;利用第一训练样本集来训练第一自然语言处理模型以得到第一微调模型;利用第二训练样本集来训练第一自然语言处理模型以得到第二微调模型;利用第一微调模型对第二训练样本集进行处理以得到经过修正的第二训练样本集;利用第二微调模型对第一训练样本集进行处理以得到经过修正的第一训练样本集;利用第三训练样本集来训练第一自然语言处理模型,第三训练样本集至少包含经过修正的第一和第二训练样本集。
技术研发人员:曾泽华,邱雪涛,彭树远
受保护的技术使用者:中国银联股份有限公司
技术研发日:
技术公布日:2024/3/17
- 还没有人留言评论。精彩留言会获得点赞!