一种利用LLM实现知识库精准输出的方法、介质及系统与流程
本发明属于知识库精准输出,具体而言,涉及一种利用llm实现知识库精准输出的方法、介质及系统。
背景技术:
1、随着互联网的快速发展,网络上形成了海量的文本知识库,这为人们学习和获取知识提供了极大的便利。但是,如何从繁杂的网络文本中快速准确地获取所需知识,仍然是一个待解决的难题。传统的基于词向量的文本匹配方法,匹配准确度较低。近年来,大语言模型(llm)技术获得了长足的发展,在自然语言理解任务上展现了强大的能力,llm即大规模语言模型,是一种基于深度学习的自然语言处理模型,它能够学习到自然语言的语法和语义,从而可以生成人类可读的文本。所谓"语言模型",就是只用来处理语言文字(或者符号体系)的 ai 模型,发现其中的规律,可以根据提示 (prompt),自动生成符合这些规律的内容。llm 通常基于神经网络模型,使用大规模的语料库进行训练,比如使用互联网上的海量文本数据。这些模型通常拥有数十亿到数万亿个参数,能够处理各种自然语言处理任务,如自然语言生成、文本分类、文本摘要、机器翻译、语音识别等。而如何利用llm的强大语言理解能力,实现对大规模文本知识库的精准检索和表达,是一个值得探索的课题。目前,利用llm实现知识库精准输出的相关技术还不够成熟。现有的方法主要基于语义匹配的策略,利用llm对问题和知识库进行编码,然后计算编码之间的相似度,选择相似度最高的知识文本作为输出。这种方法存在两个问题:1)依赖语义匹配,不能充分利用llm的语言生成能力;2)匹配过程中无法考虑上下文语义,导致输出不够准确。为实现知识库的精准输出,需要研究如何更好地利用llm的语言理解与生成双重能力,在充分理解语义的基础上,生成符合语境的知识表达。这需要在编码语义表示的基础上,进一步引入语境建模,使llm充分理解问题的语义及语境信息,从而产生准确、流畅、符合上下文语义的知识表达。
2、总体而言,现有技术无法有效解决知识库精准输出的问题,急需一种新的技术方案,以更好地发挥llm的语言理解与生成能力,实现对大规模知识库的精准检索和表达。
技术实现思路
1、有鉴于此,本发明提供一种利用llm实现知识库精准输出的方法、介质及系统,解决了现有技术不能发挥llm的语言理解与生成能力,无法实现对大规模知识库的精准检索和表达的技术问题。
2、本发明是这样实现的:
3、本发明的第一方面提供一种利用llm实现知识库精准输出的方法,包括以下步骤:
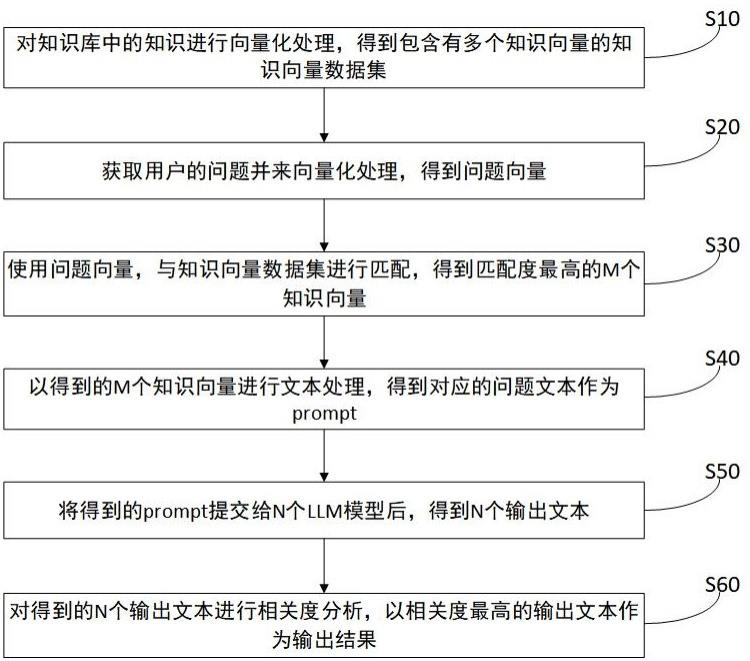
4、s10、对知识库中的知识进行向量化处理,得到包含有多个知识向量的知识向量数据集;
5、s20、获取用户的问题并来向量化处理,得到问题向量;
6、s30、使用问题向量,与所述知识向量数据集进行匹配,得到匹配度最高的m个知识向量;
7、s40、以得到的m个知识向量进行文本处理,得到对应的问题文本作为prompt;
8、s50、将得到的prompt提交给n个llm模型后,得到n个输出文本;
9、s60、对得到的n个输出文本进行相关度分析,以相关度最高的输出文本作为输出结果。
10、在上述技术方案的基础上,本发明的一种利用llm实现知识库精准输出的方法还可以做如下改进:
11、其中,所述对得到的n个输出文本进行相关度分析,以相关度最高的输出文本作为输出结果的步骤,具体是:
12、s61、对得到n个输出文本进行向量化处理得到n个输出向量;
13、s62、将每个输出向量与知识库进行相关度分析,得到每个输出向量的相关度;
14、s63、若相关度最大的输出向量的相关度大于相关度阈值,则将相关度最大的输出向量对应的输出文本作为输出结果;若不存在大于相关度阈值的输出向量,则重复执行步骤s40-s60或调整m的值后重复执行步骤s30-s60,直到得到符合相关度要求的输出文本或超过最大循环次数;若超过最大循环次数则以历次循环中相关度最高的输出向量对应的输出文本作为输出结果。
15、对m进行调整,一般是将m+1。
16、进一步的,所述若不存在大于相关度阈值的输出向量,则重复执行步骤s40-s60,直到得到符合相关度要求的输出文本或超过最大循环次数的步骤,还包括在重复执行步骤s40后对prompt进行优化的步骤,具体是:
17、步骤1、将上一循环得到的n个输出文本利用llm进行总结,得到n个总结文本;
18、步骤2、将prompt与得到的n个总结文本合并,得到n个合并文本;
19、步骤3、将n个合并文本与用户的问题进行相关度分析,以相关度最高的合并文本作为目标文本;
20、步骤4、将目标文本提交给生成所述目标文本的llm模型,分析生成新的prompt替换原来的prompt,实现prompt的优化。
21、其中,所述n个llm均采用api调用的方式。
22、其中,所述对知识库中的知识进行向量化处理以及获取用户的问题并来向量化处理的步骤中,向量化的方法为采用word2vec将知识库中的知识文本或用户的问题文本处理为向量。
23、其中,所述使用问题向量,与所述知识向量数据集进行匹配,得到匹配度最高的m个知识向量,的步骤具体为:计算所述问题向量和所述知识向量数据集中每一个知识向量进行相似度计算,选定m个匹配度最高的m个知识向量作为问题匹配结果,其中相似度计算的方法为余弦相似度。
24、其中,所述以得到的m个知识向量进行文本处理,得到对应的问题文本作为prompt的步骤,具体包括:
25、将得到的m个知识向量映射为自然语言,转换为文本表达;
26、将文本表达得到的文本拼接为一个prompt序列。
27、其中,m=5;n=3。
28、本发明的第二方面提供一种计算机可读存储介质,所述计算机可读存储介质中存储有程序指令,所述程序指令运行时,用于执行上述的一种利用llm实现知识库精准输出的方法。
29、本发明的第三方面提供一种利用llm实现知识库精准输出系统,包含上述的计算机可读存储介质。
30、具体的,本发明提出的一种利用llm实现知识库精准输出的方法,通过语义匹配获取候选知识,并利用llm的生成能力进行多轮交互求精,实现了知识库文本的精准检索和表达。该方法具有以下技术效果:
31、1. 提高了知识检索的准确率
32、本发明通过向量化表示问句和知识,计算向量间相似度进行初步匹配,可以提高与问句相关的知识被检索到的概率,避免大量不相关知识的干扰。相比仅依赖关键词匹配的传统方法,本发明的向量匹配显著提升了知识检索的准确率。
33、2. 增强了知识表达的正确性和流畅性
34、通过将匹配到的知识向量作为prompt,提交给llm生成响应文本,可以充分发挥llm的语言生成能力,产生符合语境的知识表达。相比直接输出检索到的知识文本,本发明合成的响应文本在语法、语义上都更加通顺、准确。
35、3. 实现了知识输出的迭代优化
36、本发明设计了基于相关度分析的多轮交互机制,可以迭代优化知识表达,直到满足精度要求。同时,还可以通过总结prompt的优化进一步提升每轮的效果。这种渐进求精的策略明显提高了知识表达的质量。
37、4. 极大提升了知识库的利用效率
38、通过语义匹配快速定位相关知识,再辅以llm的生成能力进行知识表达,本发明极大提升了海量知识库的利用效率。用户可以迅速获得所需知识,而无需逐字阅读整个知识库。
39、5. 方法具有较强的可拓展性
40、本发明的框架具有模块化设计,向量表示、语义匹配、语言生成等每个模块都可以灵活调整,如采用更先进的向量表示和匹配算法、集成多个llm等。因此,本方法具有较强的可拓展性和可优化空间。
41、总体来说,本发明利用llm实现知识库精准输出的方法,通过语义匹配与语言生成的有机结合,实现了对大规模文本知识库的高效准确地检索和表达。该方法提高了知识服务的质量,为知识获取提供了有效的新型解决方案,具有重要的技术进步意义。相信随着核心技术的不断进步,本发明的应用前景非常广阔。
- 还没有人留言评论。精彩留言会获得点赞!