一种注意力视觉问答方法、装置、电子设备及存储介质
本发明涉及注意力视觉问答,尤其涉及一种注意力视觉问答方法、装置、电子设备及存储介质。
背景技术:
1、多模态视觉问答(multimodal visual question answering,vqa)是一个结合计算机视觉领域和计算机自然语言领域的一个任务,其需要解决的就是对特定的一张图片提出一个特定的问题,推理出答案。在多模态vqa任务中,计算机需要理解自然语言问题的含义以及图像或视频中的内容,然后生成正确的答案。这项任务可以应用于许多实际场景,例如机器人导航、智能客服和自然语言交互系统等领域。
2、注意力机制是一种重要的深度学习技术,已经广泛应用于各种任务中,包括自然语言处理、计算机视觉等领域。在vqa任务中,注意力机制可以帮助模型有效地捕捉图像和自然语言问题中的关键信息,并将二者合理地融合起来,从而提高模型的性能。
3、在传统的vqa模型中,常常采用一种称为“软注意力”的机制,即对图像和自然语言问题的特征进行加权平均。这种方法可以有效地融合不同来源的信息,但并没有考虑到不同部分的重要性差异,容易导致一些不重要的信息对答案的影响。
4、为了解决这个问题,近年来出现了一些新的注意力机制,如自适应注意力、区域注意力和多模态交互注意力等。这些方法可以根据不同任务的特点和数据的特征进行灵活地设计,并在vqa任务中取得了很好的效果。
5、例如,自适应注意力可以对自然语言问题中的不同部分进行不同程度的加权,从而更加准确地捕捉问题的含义;区域注意力可以对图像中不同区域进行不同程度的加权,从而更加准确地捕捉图像中的关键信息;多模态交互注意力可以对图像、视频和自然语言问题进行交互式的加权,从而更加准确地捕捉多模态数据之间的关联性。
6、尽管注意力机制在vqa任务中得到了广泛应用,并且在一定程度上提高了模型的性能,但是仍然存在一些问题。
7、首先,当前的注意力机制主要是基于“软注意力”机制,即对图像和自然语言问题中的特征进行加权平均。这种方法通常被训练成选择性地关注卷积神经网络(cnn)的一个或多个层的输出,虽然可以有效地融合不同来源的信息,但是该方法很少考虑如何确定受到关注的图像区域,没有考虑到不同部分的重要性差异,容易导致一些不重要的信息对答案的影响。
8、再次,当前的注意力机制主要是单向的,即只考虑自然语言问题对图像的注意力或图像对自然语言问题的注意力。这种方法忽略了多模态数据之间的复杂关系,容易导致模型对一些关键信息的忽略。
9、除此之外,多模态的交互的注意力通过在不同模态之间引入注意力机制,可以使得模型更加准确地捕捉不同模态的交互关系。
10、但基于不同模态的细粒度的提取还是不够,基于问题文本的关键信息的提取依然存在一定的冗余性,依然存在一些无关的信息,对于关键信息的能力欠缺。同样,对于图像的关键信息,先前的方法大多只是对对象之间的简单关系进行建模,这导致许多复杂的问题无法正确回答,因此无法提供足够的知识。并且先前的方法很少利用视觉外观特征与关系特征的协调配合。
技术实现思路
1、本发明提供了一种注意力视觉问答方法、装置、电子设备及存储介质,用于解决现有的注意力视觉问答方法答案预测效果较差的技术问题。
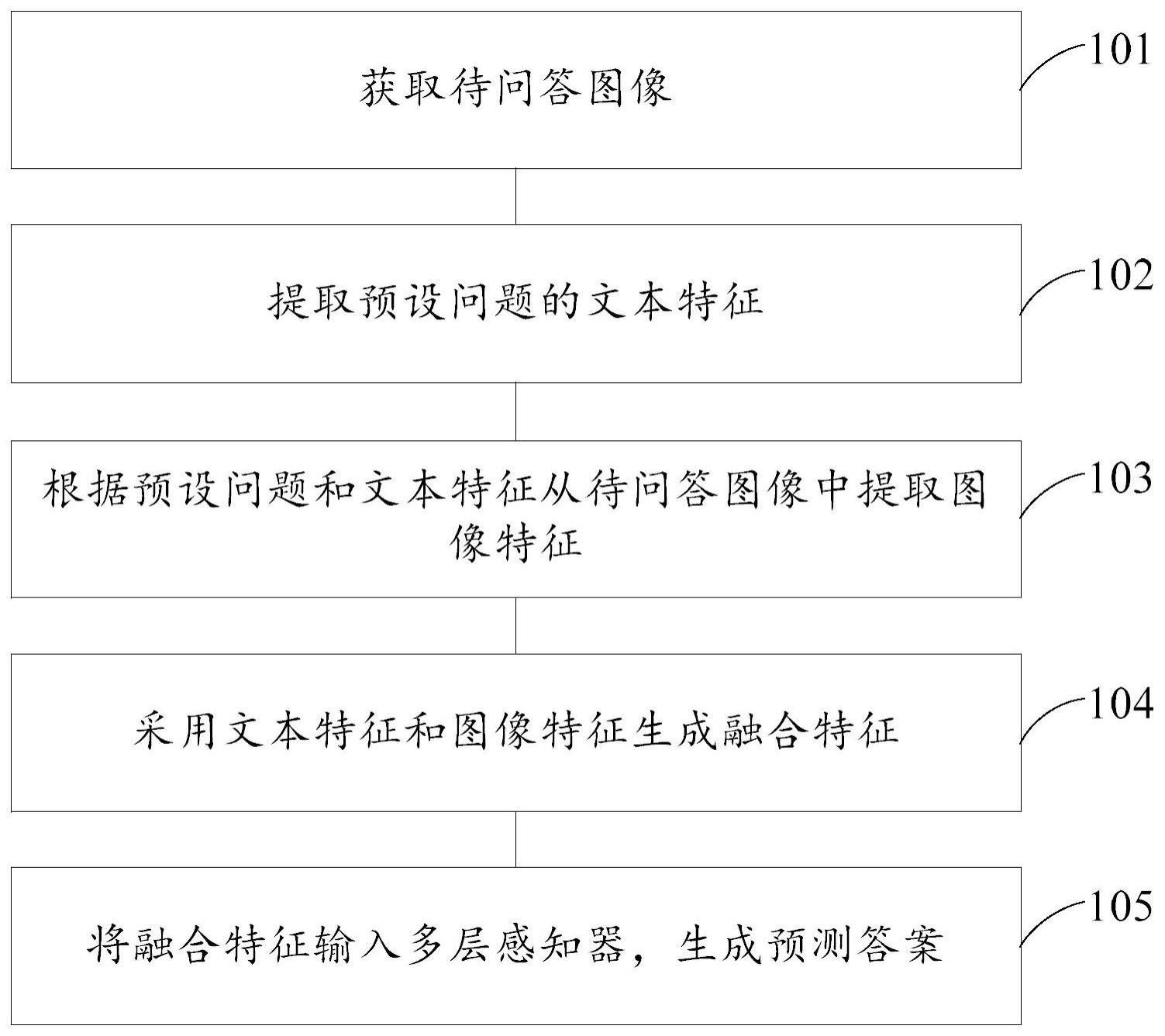
2、本发明提供了一种注意力视觉问答方法,包括:
3、获取待问答图像;
4、提取预设问题的文本特征;
5、根据所述预设问题和所述文本特征从所述待问答图像中提取图像特征;
6、采用所述文本特征和所述图像特征生成融合特征;
7、将所述融合特征输入多层感知器,生成预测答案。
8、可选地,所述文本特征包括单词级特征、短语级特征和问题级特征;所述提取预设问题的文本特征的步骤,包括:
9、从所述预设问题中提取单词;
10、将所述单词嵌入到预设向量空间中,得到单词向量,将所述单词向量作为单词级特征;
11、计算所述单词向量的内积,得到短语级特征;
12、通过lstm对所述短语级特征进行编码,得到问题级特征。
13、可选地,所述图像特征包括对象注意特征、二元关系注意特征和三元关系注意特征;所述根据所述预设问题和所述文本特征从所述待问答图像中提取图像特征的步骤,包括:
14、从所述待问答图像中提取所述预设问题的显著图像区域;
15、获取所述显著图像区域的视觉特征;
16、采用所述视觉特征和所述文本特征,生成所述显著图像区域的对象注意特征;
17、对所述显著图像区域进行编码,得到所述显著图像区域中各对象的编码向量;
18、采用所述编码向量生成各所述对象间的二元关系注意特征和三元关系注意特征。
19、可选地,所述采用所述视觉特征和所述文本特征,生成所述显著图像区域的对象注意特征的步骤,包括:
20、采用所述视觉特征和所述文本特征生成多模态特征;
21、生成所述显著图像区域的重要性权重;
22、采用所述多模态特征和所述重要性权重生成对象注意特征。
23、可选地,所述融合特征包括第一融合特征、第二融合特征和第三融合特征;所述采用所述文本特征和所述图像特征生成融合特征的步骤,包括:
24、融合所述单词级特征和所述对象注意特征,生成第一融合特征;
25、融合所述短语级特征和所述二元关系注意特征,生成第二融合特征;
26、融合所述问题级特征和所述三元关系注意特征,生成第三融合特征。
27、本发明提供了一种注意力视觉问答装置,包括:
28、待问答图像获取模块,用于获取待问答图像;
29、文本特征提取模块,用于提取预设问题的文本特征;
30、图像特征提取模块,用于根据所述预设问题和所述文本特征从所述待问答图像中提取图像特征;
31、融合特征生成模块,用于采用所述文本特征和所述图像特征生成融合特征;
32、答案预测模块,用于将所述融合特征输入多层感知器,生成预测答案。
33、可选地,所述文本特征提取模块,包括:
34、单词提取子模块,用于从所述预设问题中提取单词;
35、单词级特征提取子模块,用于将所述单词嵌入到预设向量空间中,得到单词向量,将所述单词向量作为单词级特征;
36、短语级特征生成子模块,用于计算所述单词向量的内积,得到短语级特征;
37、问题级特征生成子模块,用于通过lstm对所述短语级特征进行编码,得到问题级特征。
38、可选地,所述图像特征包括对象注意特征、二元关系注意特征和三元关系注意特征;所述图像特征提取模块,包括:
39、显著图像区域提取子模块,用于从所述待问答图像中提取所述预设问题的显著图像区域;
40、视觉特征获取子模块,用于获取所述显著图像区域的视觉特征;
41、对象注意特征生成子模块,用于采用所述视觉特征和所述文本特征,生成所述显著图像区域的对象注意特征;
42、编码向量获取子模块,用于对所述显著图像区域进行编码,得到所述显著图像区域中各对象的编码向量;
43、二元关系注意特征和三元关系注意特征生成子模块,用于采用所述编码向量生成各所述对象间的二元关系注意特征和三元关系注意特征。
44、本发明还提供了一种电子设备,所述设备包括处理器以及存储器:
45、所述存储器用于存储程序代码,并将所述程序代码传输给所述处理器;
46、所述处理器用于根据所述程序代码中的指令执行如上任一项所述的注意力视觉问答方法。
47、本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质用于存储程序代码,所述程序代码用于执行如上任一项所述的注意力视觉问答方法。
48、从以上技术方案可以看出,本发明具有以下优点:本发明通过获取待问答图像;提取预设问题的文本特征;根据所述预设问题和所述文本特征从所述待问答图像中提取图像特征;采用所述文本特征和所述图像特征生成融合特征;将所述融合特征输入多层感知器,生成预测答案。从而提高了答案预测的准确性。
- 还没有人留言评论。精彩留言会获得点赞!