一种基于模态交互多任务学习的多模态情感分析方法
本发明公开一种基于模态交互多任务学习的多模态情感分析方法,涉及自然语言处理。
背景技术:
1、随着信息时代的发展,用户在线上生成的内容越来越多,其中包含了文本、语音、图像模态等数据,分析和研究多模态数据的情感极性,对改善和提升信息时代的人与机器或者机器与机器交互环境起着重要作用。多模态情感分析近年来引起越来越多的关注,与单模态情感分析相比,多模态情感分析研究多个模态间的互相补充和增强,在处理社交媒体数据时,效果取得了显著的提升。
2、传统的情感分析方法仅使用某一种模态信息作为分析对象,如:基于文本的情感分析,基于语音的情感分析等。视频数据中的文本、语音和视觉模态源于多个异构源,三者差异较大。因此,如何将不同模态信息进行融合,充分利用其互补信息,是多模态情感分析的核心难点问题。此外,目前的多模态情感分析方法大多只专注于模态的融合方式,而忽略了并非所有模态信息都是有用的,可能对情感分析起到负面影响;而且目前大多数模型基于端到端的模型,导致模型相对复杂且开销时间大。
技术实现思路
1、本发明目的在于克服上述现有技术存在的缺陷而提供一种基于模态交互多任务学习的多模态情感分析方法,并且在多模态情感分析方面取得了理想的效果,能有效的提升多模态任务的效果。
2、为实现上述技术目的,达到上述技术效果,本发明是通过以下技术方案实现:
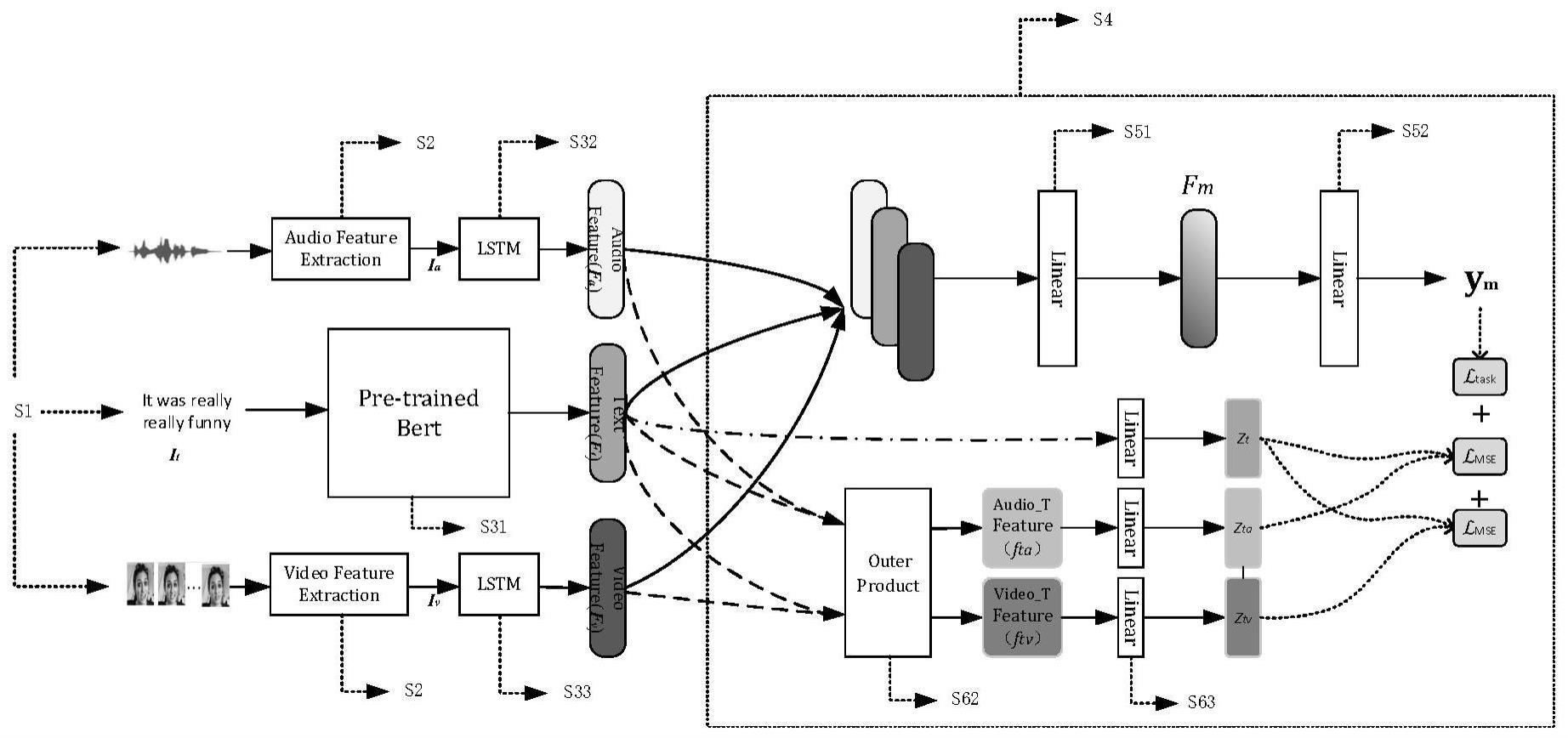
3、一种基于模态交互多任务学习的多模态情感分析方法,包括:对视频进行预处理;从预处理后的数据中分别获取文本、语音、视觉单模态原始特征;从三种单模态原始特征中分别进一步获取单模态特征表示;根据多模态数据以文本为主导模态的特点,构造基于神经网络模型的多任务学习框架:该模型由两个部分组成,分别为一个多模态任务和两个学习文本模态与非文本模态间信息的子任务。多模态任务采用了一种经典的多模态情感分析架构,包含了特征表示模块,特征融合模块和输出模块三个模块,特征表示模块获取单模态特征后,将三种单模态特征表示进行拼接并投影到一个低维空间,最后用多模态融合的特征表示来进行预测多模态情感;子任务部分将之前得到的单模态特征表示投影到一个新的特征空间中,将文本模态与非文本模态交互,学习文本模态于非文本模态的信息,进而有效提升多模态任务的效果
4、一种基于模态交互多任务学习的多模态情感分析方法,包括如下步骤:
5、s1、对视频进行预处理:从视频中得到相应文本;从视频中分离出音频,并对音频进行转录;对视频进行分帧处理、对视频帧进行人脸检测与对齐处理;
6、s2、从预处理后的数据中获取单模态原始特征:利用预先训练的工具包提取出音频特征和视频特征;
7、s3、基于单模态原始特征,进一步提取单模态特征表示,包含文本特征表示,音频特征表示,视频特征表示;
8、s4、根据多模态数据以文本为主导模态的特点,构造基于神经网络模型的多任务学习框架;
9、s5、多模态情感分析任务采用了一种经典的多模态情感分析架构,包含了特征表示模块,特征融合模块和输出模块三个模块,特征表示模块获取单模态特征后,将三种单模态特征表示进行拼接并投影到一个低维空间,最后用多模态融合的特征表示来进行预测多模态情感;
10、s6、子任务部分将之前得到的单模态特征表示投影到一个新的特征空间中,将文本模态与非文本模态交互,学习文本模态于非文本模态的信息,进而有效提升多模态任务的结果。
11、进一步地,所述步骤s3的具体包括以下步骤:
12、s31、对原始文本特征,使用预先训练的12层bert来提取文本的特征表示,根据经验,选择最后一层的第一个词向量作为整个句子的表示;
13、s32、对原始音频特征,使用一个单向长短时记忆神经网络来获取音频的特征表示,用最后的隐藏层向量作为全序列表示;
14、s33、对原始视频特征,使用一个单向长短时记忆神经网络来获取视频的特征表示,用最后的隐藏层向量作为全序列表示。
15、进一步地,所述文本特征表示、音频特征表示、视频特征表示具体为:
16、
17、其中,ft表示文本模态特征表示,为原始文本信息it经过bert提取的文本特征表示中选择的词向量;为文本模态特征表示提取过程中所用的权重参数;dt’为bert最后一层的维度;
18、
19、其中,fa表示音频模态特征表示,为原始的语音特征ia经过lstm获取音频的特征表示;为音频模态特征表示提取过程中所用的权重参数;da’为lstm的隐藏层维度;
20、
21、其中,fv表示视频模态特征表示,为原始的视觉特征iv经过lstm获取视频的特征表示;为视频模态特征表示提取过程中所用的权重参数;dv’为lstm的隐藏层维度。
22、进一步地,所述步骤s4的具体包括以下步骤:
23、多任务学习框架包括两个部分,分别为一个多模态任务和两个学习文本模态与非文本模态间信息的子任务:其中子任务结合了多模态数据以文本为主导模态的特点,学习文本模态与非文本模态间的信息,用于指导最终的多模态情感分析任务。
24、进一步地,所述步骤s5的具体包括以下步骤:
25、将所有单模态表示进行拼接并投影到一个低维空间:
26、
27、其中表示多模态融合的特征表示,为可学习的权重矩阵,表示偏移量;ft表示文本模态特征表示,fa表示音频模态特征表示,fv表示视频模态特征表示;
28、最后用多模态融合的特征表示fm来进行预测多模态情感:
29、
30、其中,ym为最终的多模态情感预测结果,表示可学习的权重矩阵,表示偏移量。
31、进一步地,所述步骤s6的具体包括以下步骤:
32、为了避免不同模态之间的维度差异带来的影响,直接将之前得到的单模态特征表示投影到一个新的特征空间中;
33、在三种单模态特征表示的维度上增加一个额外的常数1,目的是使两种单模态特征表示外积后所生成的融合特征不仅包含两种模态交互的信息,还包含单模态特征表示的信息:
34、ft∈[ft 1]t
35、fv∈[fv 1]t
36、fa∈[fa 1]t
37、其中,ft、fv、fa为在投影的三种单模态特征表示的维度上增加一个额外的常数1的特征;ft表示文本模态特征表示,fa表示音频模态特征表示,fv表示视频模态特征表示;
38、把文本模态特征ft分别与语音模态特征fa、视觉模态特征fv外积:
39、
40、
41、其中,表示外积操作,表示文本模态分别与视觉模态和音频模态外积后的结果;
42、外积融合后经过几个线性层以方便后面的学习过程:
43、
44、
45、
46、其中,表示可学习的权重矩阵;均表示偏移量;
47、最后通过损失函数降低的学习方式学习文本特征与非文本特征之间的信息,提高本方法所对应的多模态情感分析模型的整体性能;
48、本方法所对应的多模态情感分析模型的整体学习方法是通过将总损失函数结果最小化来实现的:
49、l=ltask+2αlmse
50、其中,α是子任务每个损失函数对总损失函数所占的权重,ltask表示多模态任务损失,lmse表示文本模态zt与两融合模态ztv、zta之间的损失函数,公式如下:
51、
52、
53、其中,n为训练样本的数量,表示第i个批次的多模态情感真实结果,为第i个批次的多模态情感预测结果,k∈(tv,ta),表示第i个批次的融合模态ztv和zta,表示第i个批次的文本模态。
54、与现有技术相比,本发明具有以下有益效果:
55、一、本发明通过从视频中提取三种单模态特征;并将三种模态在特征表示的维度上增加一个额外的常数1,目的是使两种模态特征外积后所生成的融合特征不仅包含两种模态交互的信息,还包含单模态特征的信息;结合多模态数据以文本为主导模态的特点,将文本模态特征表示与音频模态特征表示、视频模态特征表示两两外积融合进行多任务学习,提高了模型的泛化性和情感分析的准确性。
56、二、本发明模型多任务部分和子任务部分都采用了典型的框架,不仅能够有效减少时间开销和节省计算资源,同时使模型能够很好地适应于不同地视频场景。
- 还没有人留言评论。精彩留言会获得点赞!