基于机器视觉的场景预测性拟合方法和系统
本发明涉及机器视觉,特别涉及一种基于机器视觉的场景预测性拟合方法和系统。
背景技术:
1、机器视觉是以机器替代人类眼睛和大脑执行观察、测量、分析、判断的任务,其是当前人工智能技术发展的一个重要分支,在制造工业、道路交通、物流运输、建筑工程、机器人、视频安全监控乃至智慧家庭等领域都具备广泛的应用前景。
2、机器视觉是一项综合性工程,包括光学成像、图像信息分析处理、目标识别、自动控制等软硬件技术相互结合。当前,机器视觉系统在效率、精确度以及对各种光线环境适应性方面,都已经远远胜于人类自身。机器视觉对于单一目标或预设类型的多种目标识别,以及对目标特征的提取分析判断和自动控制响应方面,也都已经趋于成熟。
3、然而,在制造工厂、交通道路、物流仓储场地、建筑工地、室内空间等应用环境中,往往面临着高动态性和综合性场景,这些场景往往包含多类型目标和非预设类型目标,且面临着各个目标的位置和空间形态呈现高动态性变化的情况。
4、在针对这些高动态性和综合性场景应用机器视觉技术时候,往往存在目标未识别率、漏识别率或误判率高、时间延迟大的问题,进而导致对于当前场景无法做出实时、正确的判断和自动控制响应。例如,道路交通领域,基于机器视觉的自动驾驶目前比较成熟的应用仍然局限于高速公路、主干道等目标比较单一、稳定的简单场景,而在机动车、非机动车、行人、动植物、各类设施等目标混杂且高度变化的非主干道路、社区内部道路等场景下则基本无法应用。又例如,对于标准化程度高的制造工厂、物流仓储场地或建筑工地,存在类型简单、固定且分布规则有序的各类目标的场景下,各种基于机器视觉的自动化控制设备和智能机器人易于应用,但对于非标准化的场景,由于各类目标的类型多样且不明确、分布规则无序性和变化性大,则现有技术中还难以提供基于机器视觉实现自动响应控制的实用解决方案。
技术实现思路
1、本发明提供一种基于机器视觉的场景预测性拟合方法和系统。面向包含多类型目标和非预设类型目标且各个目标的位置和空间形态呈现高动态性变化的场景,本发明能够有效提升在以上场景下基于机器视觉实现目标识别、分析、判断的效率和准确率;进而,本发明执行适应以上场景特征的自主性的响应控制,提高了在以上场景下基于机器视觉实现的各种自动化功能的可靠性与稳定性。
2、本发明提供一种基于机器视觉的场景预测性拟合方法,包括以下步骤:
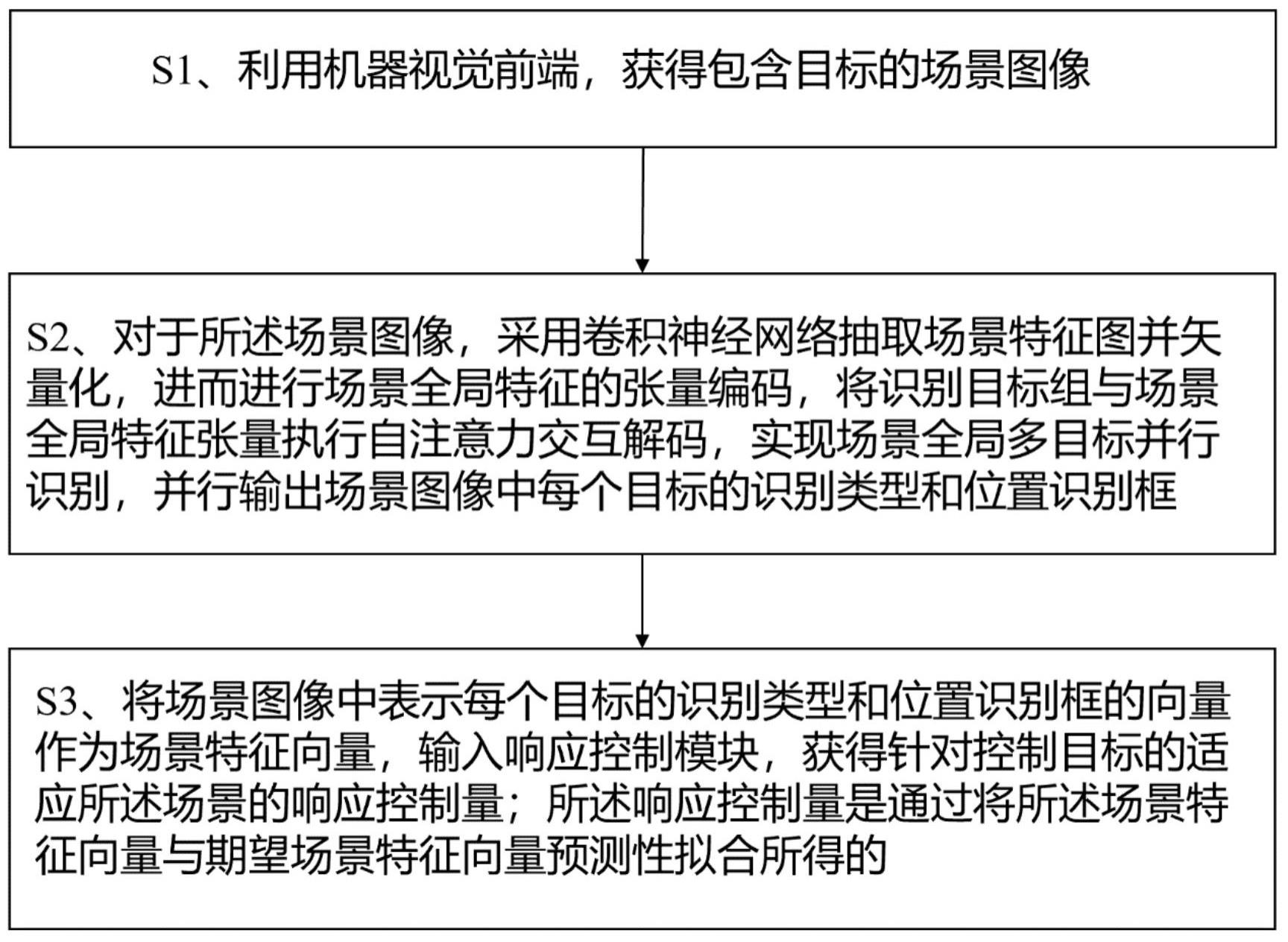
3、步骤s1,利用机器视觉前端,获得包含目标的场景图像;
4、步骤s2,对于所述场景图像,采用卷积神经网络抽取场景特征图并矢量化,进而进行场景全局特征的张量编码,将识别目标组与场景全局特征张量执行自注意力交互解码,实现场景全局多目标并行识别,并行输出场景图像中每个目标的识别类型和位置识别框;
5、步骤s3,将场景图像中表示每个目标的识别类型和位置识别框的向量作为场景特征向量,输入响应控制模块,获得针对控制目标的适应所述场景的响应控制量;所述响应控制量是通过将所述场景特征向量与期望场景特征向量预测性拟合所得的。
6、优选的是,所述步骤s2具体包括:
7、步骤s2a、构造由样本场景图像和目标标签成对组成的训练集合,并构造初始化的卷积神经网络,将所述样本场景图像输入卷积神经网络进行训练,由所述卷积神经网络抽取样本场景图像的场景特征图并矢量化;
8、步骤s2b、构造并初始化用于对场景全局特征进行张量编码的编码器以及将识别目标组与场景全局特征张量执行自注意力交互解码的解码器;并将场景特征图输入所述编码器,获得场景全局特征的张量编码,再将识别目标组与场景全局特征张量执行自注意力交互解码;
9、步骤s2c,构造并初始化进行场景全局多目标并行识别的目标类型识别模型和目标位置框识别模型;再将识别目标组的目标预测解码特征输入所述目标类型识别模型和目标位置框识别模型,并行输出场景图像中每个目标的识别类型和位置识别框;
10、步骤s2d、针对训练集合的样本场景图像,目标类型识别模型和目标位置框识别模型输出的n个目标识别类型和位置识别框的集合,与该训练集合的目标标签的偏差计算损失函数,并获得对模型参数的估计;
11、步骤s2e、完成训练后,针对机器视觉前端提供的场景图像,采用所述卷积神经网络抽取场景特征图并矢量化,进而进行场景全局特征的张量编码,将识别目标组与场景全局特征张量执行自注意力交互解码,实现场景全局多目标并行识别,并行输出场景图像中每个目标的识别类型和位置识别框。
12、优选的是,所述步骤s2a中,所述样本场景图像和目标标签成对组成的训练集合表示为:
13、其中是训练集合的训练样本总量, 是训练样本的第张样本场景图像,是该图像的图像高度,是该图像的图像宽度;是训练集合的第张样本场景图像中最多个目标类型和目标位置框定位向量共同构成的目标标签,是预先设定的一个整数,且该整数显著大于样本场景图像中可能存在的目标个数;其中 ,是第个样本场景图像中第个目标的目标类型,<msubsup><mi>b</mi><mi>j</mi><mi>i</mi></msubsup><mi>∈</mi><msup><mi>[0,1]</mi><mn>4</mn></msup>是第个样本场景图像中第个目标的目标位置框的中心点坐标、框高度值和框宽度值构成的4维向量。
14、优选的是,所述步骤s2a中,所述初始化的卷积神经网络是由预训练resnet模型的卷积层结构以及全卷积网络构成的,该预训练resnet模型的卷积层结构表示为,其中是预训练resnet模型卷积层所有参数构成的参数张量,为输入该卷积神经网络的场景图像;该全卷积网络表示为,其中参数张量初始化为,且 ,表示所述卷积神经网络所生成的低分辨率的场景特征图。
15、优选的是,所述步骤s2a中,将样本场景图像作为场景图像,输入初始化的卷积神经网络,得到低分辨率的场景特征图;所述场景特征图进行矢量化,使用个 的卷积核拼接(concate)成的,将特征图降维成通道数为的新的高水平特征图,即
16、符号表示图像与卷积核之间的卷积运算,;将特征图和位置编码参数相加, 该位置编码参数初始化为,然后将两者之和求出的张量中的的平面形状拉直,从而将形状更改,并转置成为的张量,作为场景全局特征张量编码的编码器的输入,记为,即
17、。
18、优选的是,步骤s2b中,初始化用于编码器和解码器的参数张量,编码器的参数 和解码器的共同组成所述参数张量 ;并且,初始化解码器中用于识别目标组的参数张量 ;将矢量化后的所述输入自注意力机制的编码器,得到和同样形状的场景全局特征编码, 即,
19、, 是编码器的参数张量;将 和识别目标组的参数张量 通过交叉注意力机制的解码器,得到对识别目标组中的n个目标预测解码特征, 即 ,
20、 是n个目标预测解码特征 所组成的张量,是解码器的参数张量。
21、优选的是,所述步骤s2c中,初始化用于每个目标类型识别模型中的参数张量,以及初始化目标位置框识别模型的中的参数张量;将n个目标预测解码特征分别通过目标类型识别模型和目标位置框识别模型,得到场景图像中含n个识别类型和位置识别框的集合 , 即。
22、优选的是,步骤s2e中,针对机器视觉前端提供的场景图像,并行输出的每个目标的识别类型和位置识别框表示为:
23、是该场景图像包含的第个目标属于所有可能的识别类别的概率值构成的向量,则是第个目标的位置识别框定位的向量。
24、优选的是,步骤s3中,所述响应控制模块通过循环滚动优化,对期望场景特征的期望场景特征向量和所述场景特征向量进行预测性拟合的比例系数赋值,从而生成拟合场景特征向量yd:
25、其中,λ表示预测性拟合的预测强度,用来表示预测性拟合相对于当前场景提前的时间周期的数量,为在预测强度λ条件下的第k个周期的拟合场景特征向量输出值,为第k+1-i个周期的期望场景特征向量的参考值,为第k+1-i个周期的实际的场景特征向量;为拟合的比例系数,通过循环滚动的取值,可得、、中的比重,基于循环滚动优化后的这三个参数,获得用于计算响应控制量的拟合场景特征向量yd。
26、本发明提供的一种基于机器视觉的场景预测性拟合系统,其特征在于,包括:
27、机器视觉前端,用于获得包含目标的场景图像;
28、目标识别模块,用于对于所述场景图像,采用卷积神经网络抽取场景特征图并矢量化,进而进行场景全局特征的张量编码,将识别目标组与场景全局特征张量执行自注意力交互解码,实现场景全局多目标并行识别,并行输出场景图像中每个目标的识别类型和位置识别框;
29、响应控制模块,用于将场景图像中表示每个目标的识别类型和位置识别框的向量作为场景特征向量,获得针对控制目标的适应所述场景的响应控制量;所述响应控制量是通过将所述场景特征向量与期望场景特征向量预测性拟合所得的。
30、本发明基于所述响应控制量,能够适应高动态性、多类型目标场景实现自主响应控制,提供对目标类型的准确识别率,提高响应的自适应性,从而,提高了在以上场景下基于机器视觉实现的各种自动化功能的可靠性与稳定性。
- 还没有人留言评论。精彩留言会获得点赞!