一种自适应尺度网格和扩散强度的密度峰值聚类方法
本发明涉及数据集聚类,尤其涉及一种自适应尺度网格和扩散强度的密度峰值聚类方法。
背景技术:
1、聚类分析是一种无监督的学习方法,其目的是按照特定的标准,将数据划分到不同的簇中,探索数据的隐含信息,作为一种数据分析方法,聚类分析被广泛的应用于数据分析,图像处理,生物信息学,模式识别,机器学习等领域;目前在数据集聚类过程中,采用密度峰值聚类算法,即dpc算法,但采用密度峰值聚类算法进行数据集聚类时,无法处理更高维度的数据聚类。
技术实现思路
1、本发明的目的在于提供一种自适应尺度网格和扩散强度的密度峰值聚类方法,能够获得处理更高维度的数据聚类的效果。
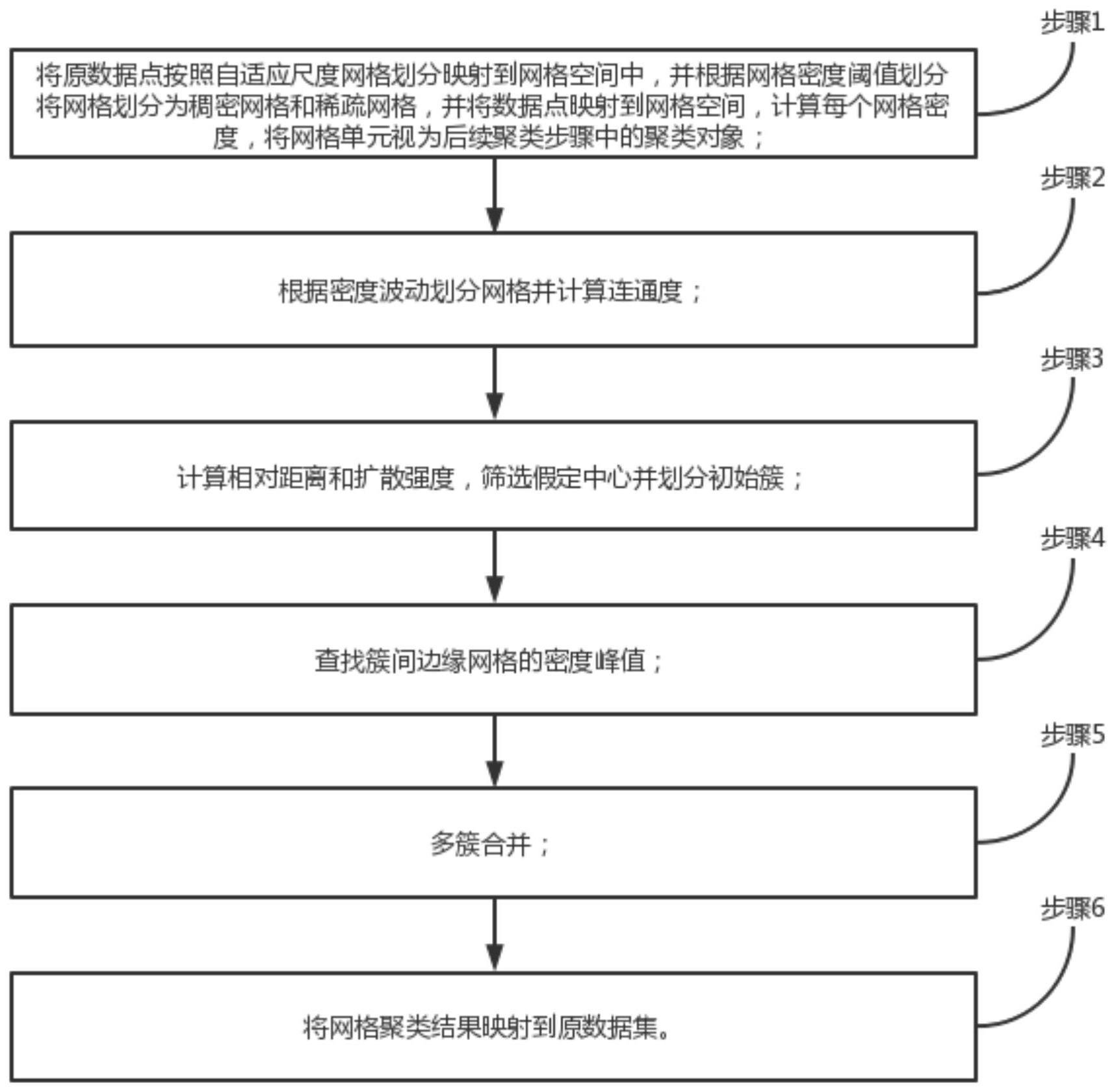
2、为实现上述目的,本发明采用的一种自适应尺度网格和扩散强度的密度峰值聚类方法,包括如下步骤:
3、步骤1,将原数据点按照自适应尺度网格划分映射到网格空间中,并根据网格密度阈值划分将网格划分为稠密网格和稀疏网格,并将数据点映射到网格空间tg,计算每个网格密度,将网格单元视为后续聚类步骤中的聚类对象;
4、步骤2,根据密度波动划分网格并计算连通度;
5、步骤3,计算相对距离和扩散强度,筛选假定中心并划分初始簇;
6、步骤4,查找簇间边缘网格的密度峰值;
7、步骤5,多簇合并;
8、步骤6,将网格聚类结果映射到原数据集。
9、其中,在步骤2,根据密度波动划分网格并计算连通度的步骤中:
10、将ρg<θ记为稀疏网络,反之则记为稠密网格,计算每个稠密网格的连通度hg和全局连通分支数ω。
11、其中,在步骤3,计算相对距离和扩散强度,筛选假定中心并划分初始簇的步骤中:
12、采用d维空间中的切比雪夫距离来计算网格obi的相对距离δi,其中obip是该网格的p维坐标:
13、
14、
15、计算每个网格的中心度后将其降序排列并开始遍历查找,若在网格i周围δi的半径范围内,γi>γj(j≠i),该网格即为假定中心;非中心网格再根据最近邻且γ值最高的网格划分到该中心代表的簇中,执行该步骤直到剩余网格全部划分完毕。
16、其中,在步骤4,查找簇间边缘网格的密度峰值的步骤中,按照以下条件,查找各簇之间的边缘网格:
17、找出簇c中网格i,在其δi范围内存在属于其他簇c’的网格j;
18、i是簇c中离j网格最近的网格;
19、一对簇c和c’之间的边缘网格密度峰值记为ρcc′。
20、其中,在步骤5,多簇合并的步骤中:
21、通过簇间边缘网格的密度峰值来判断是否需要合并该簇,若簇间的边缘网格密度峰值越高则说明两簇的相似度越高;若该网格所在簇c的密度峰值在一定密度波动范围,则认为该簇应该被合并邻近的簇c’中,即满足以下公式:
22、
23、对所有簇的ρcc′从高到低进行这项置信度判断,标记非聚类簇,并将其归并到距离最近的聚类c’中。
24、其中,在步骤6,将网格聚类结果映射到原数据集的步骤中:
25、将数据点对应的网格单元标记为该网格所属的簇类,建立数据与网格空间的查找表,将tg中的簇类记录到数据集聚类结果表中。
26、本发明的一种自适应尺度网格和扩散强度的密度峰值聚类方法,将原数据点按照自适应尺度网格划分映射到网格空间中,并根据网格密度阈值划分将网格划分为稠密网格和稀疏网格,并将数据点映射到网格空间tg,计算每个网格密度,将网格单元视为后续聚类步骤中的聚类对象;根据密度波动划分网格并计算连通度;计算相对距离和扩散强度,筛选假定中心并划分初始簇;查找簇间边缘网格的密度峰值;多簇合并;将网格聚类结果映射到原数据集;通过利用自适应尺度网格划分将数据集映射到网格空间;定义自适应划分尺度和密度波动公式,用单个网格单元密度代替所含数据点的局部密度;定义扩散强度计算网格中心度;设计中心网格筛选方案和分配策略得到聚类结果;相较于原dpc算法,本方法依据网格划分优势和新的簇分配策略可以处理更高维度的数据聚类,无需再预设截断距离等参数;降低时间复杂度,提升聚类速度;同时解决原欧式距离存在的高维失效问题。
技术特征:
1.一种自适应尺度网格和扩散强度的密度峰值聚类方法,其特征在于,包括如下步骤:
2.如权利要求1所述的自适应尺度网格和扩散强度的密度峰值聚类方法,其特征在于,在步骤2,根据密度波动划分网格并计算连通度的步骤中:
3.如权利要求1所述的自适应尺度网格和扩散强度的密度峰值聚类方法,其特征在于,在步骤3,计算相对距离和扩散强度,筛选假定中心并划分初始簇的步骤中:
4.如权利要求1所述的自适应尺度网格和扩散强度的密度峰值聚类方法,其特征在于,在步骤4,查找簇间边缘网格的密度峰值的步骤中,按照以下条件,查找各簇之间的边缘网格:
5.如权利要求1所述的自适应尺度网格和扩散强度的密度峰值聚类方法,其特征在于,在步骤5,多簇合并的步骤中:
6.如权利要求1所述的自适应尺度网格和扩散强度的密度峰值聚类方法,其特征在于,在步骤6,将网格聚类结果映射到原数据集的步骤中:
技术总结
本发明涉及数据集聚类技术领域,具体涉及一种自适应尺度网格和扩散强度的密度峰值聚类方法;将原数据点按照自适应尺度网格划分映射到网格空间中,并根据网格密度阈值划分将网格划分为稠密网格和稀疏网格,并将数据点映射到网格空间T<subgt;g</subgt;,计算每个网格密度,将网格单元视为后续聚类步骤中的聚类对象;根据密度波动划分网格并计算连通度;计算相对距离和扩散强度,筛选假定中心并划分初始簇;查找簇间边缘网格的密度峰值;多簇合并;将网格聚类结果映射到原数据集;通过上述方式,能够获得处理更高维度的数据聚类的效果。
技术研发人员:王玥洋,佘堃,刘书舟,于钥
受保护的技术使用者:电子科技大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!