基于随机Transformer模型的有模型深度强化学习方法
本发明涉及强化学习,具体涉及一种基于随机transformer模型的有模型深度强化学习方法。
背景技术:
1、强化学习是一种机器学习方法,其旨在使智能体通过与环境进行交互来学习最优的行为策略。与传统的监督学习和无监督学习方法不同,强化学习关注的是通过试错和奖励信号的反馈来学习正确的行为,从而使智能体能够在不断变化的环境中做出自适应的决策。近年来,随着相关研究的进一步深入与计算能力的发展,深度强化学习在多个领域中取得了更加广泛的成功。深度强化学习结合了深度神经网络的强大表示学习能力和强化学习的决策优化能力,使得智能体能够从原始环境数据中学习到高层次的抽象特征,并在复杂任务中相比传统方法取得了突破性的性能提升。由deepmind团队开发的alphago就是一个典型的例子,其通过结合深度神经网络与蒙特卡罗树搜索,一举战胜了当时的围棋世界冠军李世石。alphago的成功为近十年间兴起的人工智能浪潮起到了重要的推进作用。
2、有模型强化学习算法首先构造出一个真实环境的仿真模型,随后利用这一模型生成的轨迹来进行策略提升,相比于无模型算法其样本效率取得了显著的提升。dreamer算法(hafner d,lillicrap t p,norouzi m,et al.mastering atari with discrete worldmodels[c]//international conference on learning representations.2021)是这一框架下近年来的典型算法,其在在atari游戏、deepmind control、minecraft等多个环境中展示了强大的能力。dreamer使用循环神经网络作为其序列模型,循环神经网络的数据具有前后依赖关系,这一设计使得其难以并行,无法充分发挥现代显卡的并行加速能力,从而导致训练速度较慢。当可供世界模型进行训练的数据增多时,如在离线强化学习的情景下,循环神经网络的速度劣势将会被进一步凸显。
3、最近的一些方法,如iris(micheli v,alonso e,fleuret f.transformers aresample-efficient world models[c]//the eleventh international conference onlearning representations.2023)、twm(robine j,m,uelwer t,etal.transformer-based world models are happy with 100k interactions[c]//theinternational conference on learning representations.2023)在世界模型中使用transformer作为其序列模型,这种结构近年来在各种序列建模和生成任务中展现出了优越的性能,其中的自注意力机制克服了长依赖关系遗忘的问题,并可以被高度并行化从而在现代显卡上提高运行效率。iris采用vq-vae(van den oord a,vinyals o,et al.neuraldiscrete representation learning[j].advances in neural information processingsystems,2017,30)作为图像编码器,将输入图像映射为4×4的隐空间上的词向量,并使用空间-时间transformer结构来捕捉单张图像内部的和多张图像之间的动力学关系。词向量这一表达源于自然语言处理领域,相比与直接使用文字的原始编码,用一个含有文字语义信息的词向量来对其进行表示更有利于建模,序列模型以词向量作为输入,iris则沿用了这一说法。然而,空间-时间transformer结构中需要对大量词向量进行自注意力操作,这会导致训练速度显著变慢。twm采用将观测、动作和奖励视为地位相同的输入词向量。这里观测是图像,动作和奖励都是标量,而自注意力机制需要利用向量点积来求相似度,这种跨越不同类型的数据的自注意力操作可能会对性能产生负面影响。与此同时,在这种输入模式下,每向序列模型增加一个时间步的数据,都需要增加三个词向量,而自注意力机制相对于词向量数目的复杂度是o(n2)的,这也使得其训练速度相对较慢。
4、上述列举的有模型强化学习算法可以在多项任务中提升强化学习的样本效率,但仍存在一些问题,主要表现在如下两个方面:
5、1)智能体在部分环境下的表现仍然十分有限,取得的平均奖励和较低,和人类表现有较大差距;
6、2)计算效率较低,在实际部署时计算开销和能源消耗较大。
7、因此,如何提升智能体在多个环境下的表现效果,并降低训练成本和在显示环境中的部署难度,提升计算效率,是目前亟待解决的问题。
技术实现思路
1、有鉴于此,本发明提供了一种基于随机transformer模型的深度强化学习方法,能够是的智能体的泛化能力更强,最终达到提升智能体在多个环境下的表现的效果,同事降低了训练成本和在现实环境中的部署难度,即实现了计算效率的提高。
2、为达到上述目的,本发明提供的基于随机transformer模型的有模型深度强化学习方法,包括如下步骤:
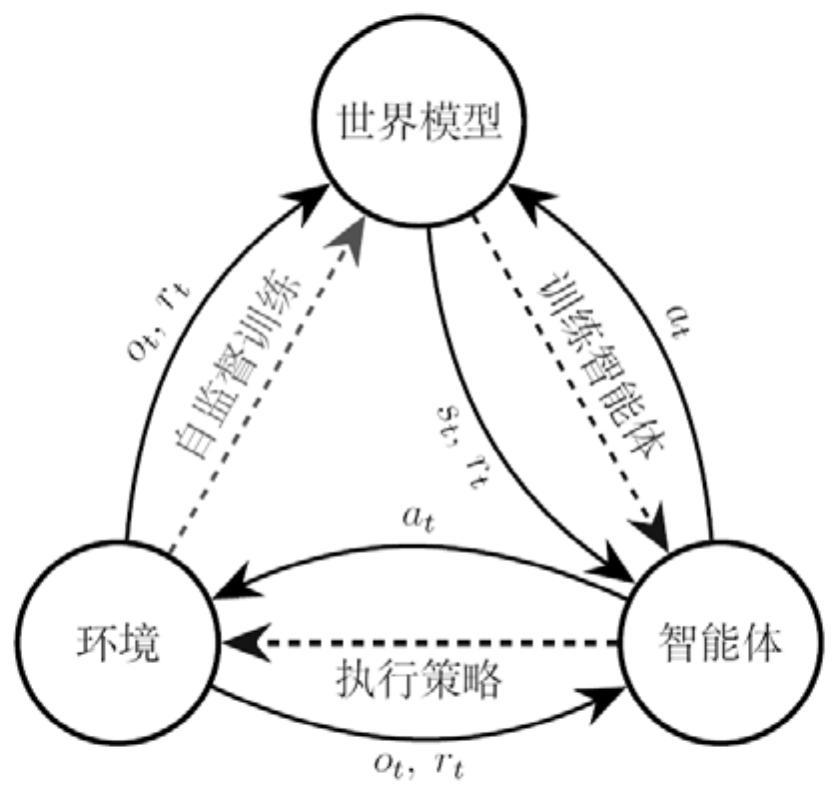
3、步骤1:在环境模型与智能体模型之间构建世界模型,智能体模型将每一时间步的智能体动作输入至世界模型,环境模型将观测的高维环境数据输入至世界模型;
4、世界模型包括变分自编码器、动作混合器、序列模型、动力学预测器、奖励预测器以及持续标志预测器;构建世界模型具体采用如下步骤:
5、利用变分自编码器将高维环境数据编码为低维隐空间上的随机变量,记为隐变量;其中高维环境数据指维数在1000维以上的环境数据,低维指维数或小于1000维;
6、动作混合器为第一多层感知机,用于将隐变量和智能体动作进行拼接操作得到状态向量;
7、序列模型为transformer模型,以状态向量作为序列模型的输入,序列模型输出对应的含历史信息的语义状态;
8、动力学预测器为第二多层感知机,以语义状态作为输入,对下一时间步的先验概率分布进行预测,获得下一时间步的先验概率分布估计,并作为动力学预测器的输出;
9、奖励预测器为第三多层感知机,以语义状态作为输入,对当前时间步的环境奖励进行预测,获得当前时间步的环境奖励,并作为奖励预测器的输出;
10、持续标志预测器为第四多层感知机,以语义状态作为输入,对当前时间步的环境持续标志进行预测,获得当前时间步的环境持续标志,并作为持续标志预测器的输出;;
11、步骤2:针对世界模型以端到端的方式进行自监督训练后,以自回归的方式生成预测的轨迹数据;
12、步骤3:基于步骤2生成的预测的轨迹数据,对智能体进行训练。
13、进一步地,步骤一中,利用变分自编码器将高维环境数据编码为低维隐空间上的随机变量,具体采用如下步骤:
14、变分自编码器为分类分布的变分自编码器,包含编码器qφ和解码器pφ,其中编码器qφ的输入为高维的环境观察数据ot,编码器qφ的输出为低维隐空间上的随机变量其中是由n个分类分布组成的随机分布,其中每个分类分布包含m个类别,故其logit及概率用n×m的矩阵来表示。
15、对进行随机采样,随机采样是指从中随机采样一个隐变量zt来表示原始观察ot,随机采样的隐变量zt作为解码器pφ的输入
16、解码器pφ执行与编码器qφ相反的操作后获得重建后的环境数据。
17、优选地,序列模型为transformer模型,以状态向量作为序列模型的输入,序列模型输出对应的含历史信息的语义状态,具体包括如下步骤:
18、序列模型的输入为:编码后的隐变量zt和智能体动作at通过一个多层感知机mφ与拼接操作合成到一个状态et中;序列模型fφ以et序列作为输入。
19、序列模型fφ输出对应的含历史信息的语义状态ht。
20、序列模型为带后续掩码的transformer结构,后续掩码只允许et和之前的信息e1,e2,...,et进行自注意力操作,即序列模型fφ的输出ht不包含未来的信息。
21、优选地,步骤2中,针对世界模型以端到端的方式进行自监督训练,具体为:使用adam优化器以梯度下降的方式进行训练。
22、优选地,述步骤3中,对智能体进行训练,具体为:在训练时同样采用adam优化器,以梯度下降的方式进行优化。
23、有益效果:
24、本发明首先使用分类分布的变分自动编码器实现高维,减少了累积的自回归预测误差,增强了世界模型的鲁棒性,同时引入了一定的随机性,使得智能体的泛化能力更强,最终达到提升智能体在多个环境下的表现的效果;随后采用transformer作为序列模型,增强了序列建模的能力,提高了轨迹生成的质量,从而提升了智能体的表现;同时每个时间步的信息被聚合至单个状态中,这进一步加快了训练速度,降低了训练成本和在现实环境中的部署难度,即实现了计算效率的提高。
- 还没有人留言评论。精彩留言会获得点赞!