基于差分和多尺度全卷积注意力网络的时序动作检测方法
本发明属于深度学习,涉及一种基于差分和多尺度全卷积注意力网络的时序动作检测方法。
背景技术:
1、时序动作检测任务旨在预测未修剪视频中的动作实例边界以及视频中每个动作实例的类别。随着移动设备和互联网的快速发展,视频数量不断激增,时序动作检测广泛应用于视频推荐、智能监控、人机交互等领域。
2、受到目标检测思想的启发,时序动作检测方法也得到了较快发展。现有时序动作检测主要包括全监督和弱监督两种方法。弱监督方法由于仅提供视频级别的类别标签,缺少动作的时间位置信息,因而性能受到一定的限制。相对弱监督方法,全监督方法由于在训练过程中有动作的时间位置标签和类别标签作为监督,所以性能更优越,本发明是一种全监督时序动作检测方法,但由于动作的多样性、背景的复杂性以及动作边界的模糊性等原因,准确的时序动作检测仍然是一个亟待解决的问题,故研究高效准确的时序动作检测有着重要意义。
技术实现思路
1、本发明的目的是提供一种基于差分和多尺度全卷积注意力网络的时序动作检测方法,采用该方法能够提高视频定位和动作识别的精度。
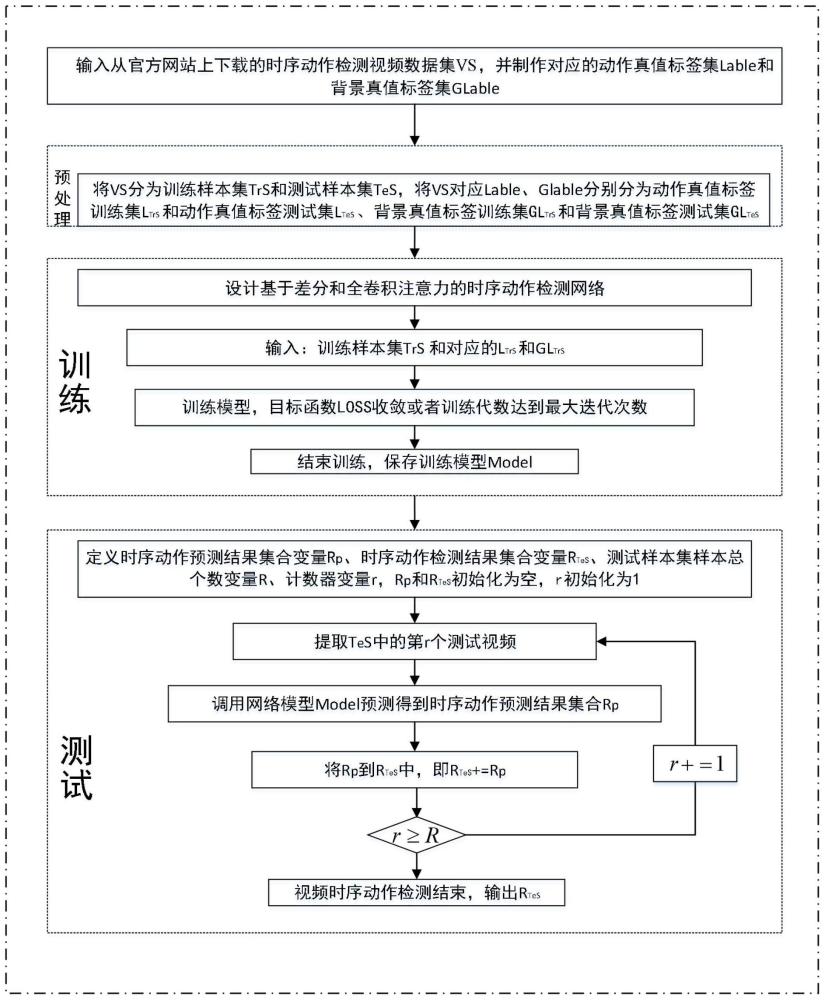
2、本发明所采用的技术方案是,基于差分和多尺度全卷积注意力网络的时序动作检测方法,具体包括如下步骤:
3、步骤1,从官网上下载时序动作检测视频数据集vs,把vs分为训练视频集trs和测试视频集tes,并制作对应真值标签;
4、步骤2,构建基于差分和多尺度全卷积注意力网络结构;
5、步骤3,设计基于差分和多尺度全卷积注意力网络的损失函数;
6、步骤4,训练网络模型model;
7、步骤5,在测试视频集tes上进行模型model测试,得到视频的动作检测结果,并对检测结果进行评价。
8、本发明的特点还在于:
9、步骤1的具体过程为:
10、步骤1.1,从时序动作检测官方网站上下载动作视频集vs={v1,…,vm,…,vm}和对应的动作真值标签集label={y1,...,ym,...,ym},vm和ym表示vs中的第m个视频和其动作标签,1≤m≤m,m表示vs中视频的总个数,w,h,tm分别对应vm中图像的宽、高和时长,表示ym中第hm个动作实例标签,1≤hm≤hm,hm表示ym中的动作实例总个数,其中分别表示的起始时间,终止时间和动作类别,把vs按n:r个数比例划分为训练视频trs和测试视频tes,表示trs中的第n个视频,表示tes中的第r个视频,n+r=m,把label按trs和tes划分为动作真值标签训练集ltrs和动作真值标签测试集ltes,表示ltrs中的第n个动作真值标签,表示ltes的第r个动作真值标签;
11、步骤1.2,制作背景真值标签glabel={g1,...,gm,...,gm},gm表示vs中的第m个视频的背景标签,把glabel按trs和tes划分为背景真值标签训练集gltrs和背景真值标签测试集gltes,
12、步骤1.2中背景标签gm的制作过程为:
13、步骤1.2.1,定义背景标签gm、背景区域变量集合时间位置变量和时间位置区域变量并初始化:
14、
15、其中,0<n<tm;
16、步骤1.2.2,获取gm的背景区域集合由gm对应的动作标签ym得到表示gm中第hm个背景,hm表示gm中的背景总个数,和分别表示的起始时间和终止时间,则
17、步骤1.2.3,计算和的重叠度即将得到的最大重叠度作为的标签值,记为
18、步骤1.2.4,更新背景真值标签gm,
19、步骤1.2.5,判断n是否大于等于tm,如果是,则第m个视频的背景真值标签gm制作成功,否则,n+=1,返回步骤1.2.3。
20、步骤2中,用于时序动作检测的差分和多尺度全卷积注意力网络结构包括输入模块、特征提取模块、级联差分注意力模块、多尺度全卷积注意力模块和预测模块,具体过程为:
21、步骤2.1,输入模块,从trs中提取第n个视频对进行采样得到长度为t的视频序列f作为网络结构的输入层,f∈rw×h×t,采样机制为:设中视频帧的总个数为tn,如果tn≥t,那么从中每隔帧采样一帧;反之,那么在中补(t-tn)个全是0的帧图像,其中integer(·)为取整函数;
22、步骤2.2,特征提取模块,将f作为输入送入基干网络i3d中,提取i3d输出前一层的特征作为f的深度特征x0,x0∈rt×d,t,d分别表示特征的时序长度和维度;
23、步骤2.3,级联差分注意力模块,把x0作为两路输入和送入级联差分注意力模块输出增强后的动作特征和背景特征
24、步骤2.4,多尺度全卷积注意力模块包括1个输入层、1个特征层、1个全卷积注意力层,把作为输入送入多尺度全卷积注意力模块,经过特征层后为d′为特征维度,再把送入全卷积注意力层,输出为mutia,mutia∈rt×d;
25、步骤2.5,预测模块由两路预测分支组成,一路把步骤2.3得到的经过全连接层得到背景分类分数pb,pb∈rt,另一路把步骤2.4得到的mutia经过分类头和回归头分别得到分类结果p和回归结果其中,p∈rt×class,p={p1,...,pt,...pt},pt和是时刻t的分类结果和定位结果,pt∈rclass,0<t≤t,和是时刻t定位的动作开始和结束时间,class为动作类别个数,分类头和回归头均为3组串联的1d卷积和激活组合层。
26、步骤2.3中,级联差分注意力模块包括两个差分注意力模块级联,每个差分注意力模块由输入层、特征层、差分注意力层组成,第一个差分注意力模块的输入层数据为特征层输入数据和输出数据分别为和差分注意力层的输入和输出数据分别为和第二个差分注意力模块的输入层数据为特征层输入数据和输出数据分别为和差分注意力层的输入和输出数据分别为和
27、步骤2.3中,差分注意力层的处理过程为:
28、1)把差分注意力模块中特征层的输出和作为差分注意力层的输入,其中
29、2)定义查询向量qa,值向量va、vb和键向量kb;
30、3)给qa、va、vb和kb赋值:
31、4)求qa和kb的相关度a(qa,kb):
32、
33、5)计算差分注意力层的输出xa,xb,
34、xa=a(qa,kb)va (2)
35、xb=a(qa,kb)vb (3)。
36、步骤2.4中,全卷积注意力层的具体过程为:
37、1)定义查询、键和值特征序列变量分别为q、k和v,给q、k、v赋值:
38、2)设置尺度变量sw、最大尺度变量sw、多尺度全卷积注意力结果集合变量aw、滑动窗大小变量lw和最大滑动窗大小变量maxlw,并初始化为sw=1,sw=t/2,lw=1,maxlw=t/2,aw=null;
39、3)按lw在q中提取对应sw尺度的特征子序列集
40、4)分别以中的各个子序列为卷积核,在k上进行卷积操作,得到sw尺度下的卷积结果集合这里其中conv(*,*)为卷积操作函数,两个参数分别对应卷积数据和卷积核,
41、5)归一化卷积结果集合得到sw尺度下的全卷积注意力结果
42、6)更新多尺度全卷积注意力结果集合aw,
43、7)判断lw是否大于等于maxlw,如果是,进入步骤8),否则,sw+=1,lw+=lw,返回步骤3);
44、8)对aw进行卷积处理得到t×d维的mutia,即mutia=conv(aw,3)。
45、步骤3中,总损失loss由背景分类损失lb和动作预测损失lfca组成,lfca由动作分类损失lc和动作定位损失lr组成:
46、loss=lb+lfca (4)
47、
48、
49、
50、
51、其中,lb和lfca分别表示第n个训练视频的背景分类损失和动作预测损失,pbn和分别表示的背景分类分数和背景真值标签,lbl是二元逻辑回归损失函数,和lrtn分别表示在t时刻的分类损失和回归损失,λ和t+分别表示平衡系数和正样本的总数,和分别表示在t时刻的分类预测结果和动作真值标签,lfocal是焦点损失函数,表示在t时刻的定位预测结果,lgiou是giou损失函数,n是训练样本中的视频总个数,t是视频长度。
52、步骤4的具体过程为:
53、步骤4.1,输入训练样本集trs、动作真值标签训练集ltrs和背景真值标签训练集gltrs;
54、步骤4.2,设置网络模型训练参数,即设置学习率变量lr、训练迭代最大次数变量max_iter、每批次数据大小变量batch_size、目标损失函数最小变化值δminloss、训练迭代次数变量step,初始化step=1;
55、步骤4.3,按照设置的训练参数进行网络训练,当目标损失函数变化小于等于δminloss或者step≥max_iter时,网络训练结束,保存网络模型model;否则step=step+1,使用adam优化器来反向修正网络模型中各网络层的权重系数,继续训练。
56、步骤5的具体过程为:
57、步骤5.1,输入测试样本集tes、动作真值标签测试集ltes和训练好的网络模型model;
58、步骤5.2,定义时序动作预测结果集合变量rp、时序动作检测结果集合变量rtes、测试样本集tes的样本总个数变量r、测试样本个数计数器变量r,rp和rtes初始化为空,即rp=null,rtes=null,r初始化为1,r=1;
59、步骤5.3,把测试样本集tes中第r个视频送入model输出时序动作预测结果集合rp;
60、步骤5.4,将rp追加到rtes中,即rtes+=rp;
61、步骤5.5,判断当前测试视频个数r是否大于等于r,如果是,测试结束,输出rtes,否则r=r+1,返回步骤5.3;
62、步骤5.6,对所有测试视频的预测结果通过计算平均精度均值map进行评价得到评价结果sa,计算公式如(9)所示:
63、sa=map(rtes,ltes) (9)
64、其中,map(*,*)为平均精度均值计算函数,rtes和ltes分别表示测试样本集tes的时序动作检测结果集和对应的动作真值标签测试集。
65、本发明的有益效果是,为了提升时序动作检测的性能,本发明提出了一种新的多尺度全卷积注意力模块,把不同尺度的动作片段特征作为卷积核,在视频序列中进行全卷积操作,可以得到视频序列中不同长度的动作注意力分数,从而增强动作特征;本发明提出了级联差分注意力模块,使用差分注意力机制加强动作和背景之间的差异,增强动作特征的同时抑制背景特征。在此基础上,本发明将级联差分注意力模块和全卷积注意力模块串联起来,设计了一个端到端的时序动作检测网络,可以实现从视频输入直接到动作定位和识别结果。
- 还没有人留言评论。精彩留言会获得点赞!