基于大模型增强的垂直领域小样本知识抽取方法和系统
本技术涉及人工智能领域,特别是一种基于大模型增强的垂直领域小样本知识抽取方法和系统。
背景技术:
1、随着大数据和人工智能技术的快速发展,知识抽取已成为自然语言处理和信息检索领域的关键任务之一。知识抽取旨在从非结构化或半结构化的文本数据中抽取结构化知识形成知识图谱,以便于计算机处理和理解。此外,构建的知识图谱还可以广泛应用于信息检索、推荐系统、知识问答等领域。因此,对现实世界中的文本数据进行准确、高效的知识抽取是一个很重要的问题。
2、然而,当前的知识抽取方案在小样本场景下还存在一些不足。一方面是泛化能力的不足,传统的基于规则和基于模式的知识抽取方法对于特定任务和领域可能具有较好的性能,但在处理多样化和不断变化的数据时,其泛化能力有限,需要人工频繁地更新规则和模式。另一方面是依赖大量标注数据,基于机器学习的知识抽取方法,尤其是深度学习方法,通常需要大量的标注数据进行训练。然而,在许多实际应用场景中,例如制造业、航空航天、医疗、教育等领域,高质量的标注数据很难获得,限制了这些方法的广泛应用。
3、因此,亟需一种垂直领域小样本知识抽取方法。
技术实现思路
1、鉴于上述问题,本技术实施例提供了一种基于大模型增强的垂直领域小样本知识抽取方法和系统,以便克服上述问题或者至少部分地解决上述问题。
2、本技术实施例第一方面,提供了一种基于大模型增强的垂直领域小样本知识抽取方法,所述方法包括:
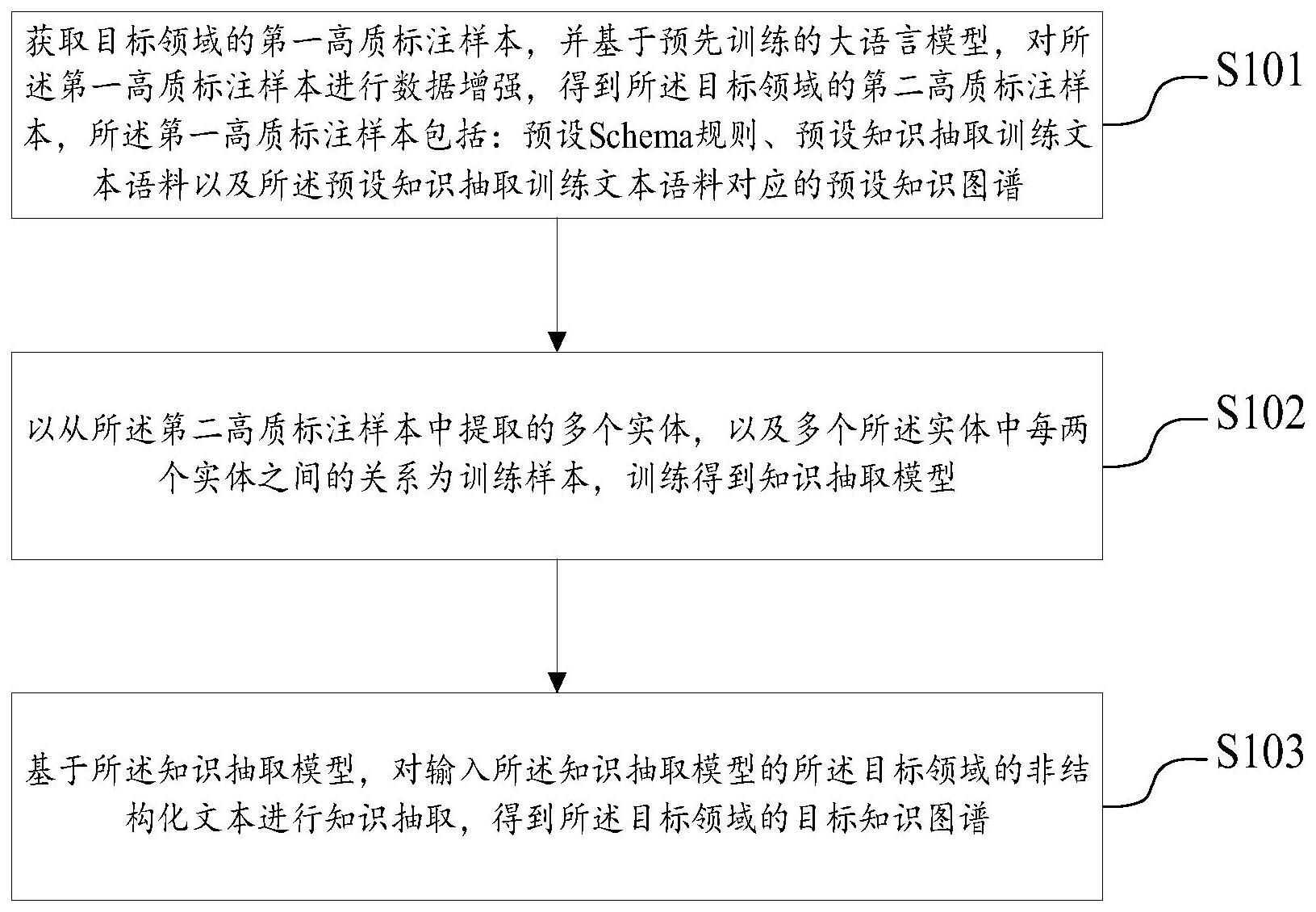
3、获取目标领域的第一高质标注样本,并基于预先训练的大语言模型,对所述第一高质标注样本进行数据增强,得到所述目标领域的第二高质标注样本,所述第一高质标注样本包括:预设schema规则、预设知识抽取训练文本语料以及所述预设知识抽取训练文本语料对应的预设知识图谱;
4、以从所述第二高质标注样本中提取的多个实体,以及多个所述实体中每两个实体之间的关系为训练样本,训练得到知识抽取模型;
5、基于所述知识抽取模型,对输入所述知识抽取模型的所述目标领域的非结构化文本进行知识抽取,得到所述目标领域的目标知识图谱。
6、可选地,所述基于预先训练的大语言模型,对所述第一高质标注样本进行数据增强,得到所述目标领域的第二高质标注样本,包括:
7、通过将所述第一高质标注样本输入所述大语言模型,得到第一目标知识图谱;
8、基于所述大语言模型,将所述第一目标知识图谱进行泛化处理,得到包含目标知识抽取信息的目标文本语料;
9、将所述目标文本语料与所述第一高质标注样本进行融合,得到所述第二高质标注样本。
10、可选地,所述通过将所述第一高质标注样本输入所述大语言模型,得到第一目标知识图谱,包括:
11、针对所述预设schema规则设定第一提示指令;
12、基于所述第一提示指令,引导所述大语言模型依据所述预设schema规则,对所述预设知识图谱进行扩充,得到所述第一目标知识图谱。
13、可选地,所述基于所述大语言模型,将所述第一目标知识图谱进行泛化处理,得到包含目标知识抽取信息的目标文本语料,包括:
14、针对所述知识抽取训练文本语料设定第二提示指令;
15、基于所述第二提示指令,引导所述大语言模型依据所述预设知识图谱,将所述第一目标知识图谱中的文本语料进行泛化处理,得到所述目标文本语料。
16、可选地,所述以从所述第二高质标注样本中提取的多个实体,以及多个所述实体中每两个实体之间的关系为训练样本,训练得到知识抽取模型,包括:
17、依据所述预设schema规则,从所述第二高质标注样本中提取出多个实体以及每两个实体之间的关系;
18、将每一个所述实体以及与其存在关系的实体进行组合,得到多个初始知识三元组,每一个所述初始知识三元组包括:头实体、关系以及尾实体;
19、采用多层感知机函数,对多个所述初始知识三元组中的关系正确性进行判定;
20、采用交叉熵损失函数对多个所述初始知识三元组中关系判定为正确的初始知识三元组进行训练,得到所述知识抽取模型。
21、可选地,所述基于所述知识抽取模型,对输入所述知识抽取模型的所述目标领域的非结构化文本进行知识抽取,得到所述目标领域的目标知识图谱,包括:
22、将多个目标句子输入所述知识抽取模型中,得到各个所述目标句子各自对应的目标知识三元组;
23、将所有的所述目标知识三元组进行融合,得到所述目标知识图谱。
24、可选地,在将所有的所述目标知识三元组进行融合,得到所述目标知识图谱之后,所述方法还包括:
25、针对所述预设知识抽取训练文本语料以及所述预设知识图谱设定第三提示指令;
26、基于所述第三提示指令,将所述预设知识图谱按照所述预设schema规则进行泛化处理,得到多个新增知识三元组;
27、利用所述预设schema规则对多个所述新增知识三元组进行校验,并将与所述预设schema规则不符的新增知识三元组进行纠错。
28、可选地,所述方法还包括:
29、将多个符合所述预设schema规则的新增知识三元组以及纠错后的新增知识三元组加入所述目标知识图谱中,以对所述目标知识图谱进行更新。
30、可选地,所述方法还包括:
31、以多个所述新增知识三元组以及多个所述新增知识三元组各自对应的预设知识抽取训练文本语料作为新的训练样本,对所述知识抽取模型进行参数更新。
32、本技术实施例第二方面,提供了一种用于实现如本技术实施例第一方面所述的基于大模型增强的垂直领域小样本知识抽取方法的系统,所述系统包括:
33、数据增强子系统,用于获取目标领域的第一高质标注样本,并基于预先训练的大语言模型,对所述第一高质标注样本进行数据增强,得到所述目标领域的第二高质标注样本,所述第一高质标注样本包括:预设schema规则、预设知识抽取训练文本语料以及所述预设知识抽取训练文本语料对应的预设知识图谱;
34、知识抽取模型训练子系统,用于以从所述第二高质标注样本中提取的多个实体,以及多个所述实体中每两个实体之间的关系为训练样本,训练得到知识抽取模型;
35、知识抽取模型推理子系统,用于基于所述知识抽取模型,对输入所述知识抽取模型的所述目标领域的非结构化文本进行知识抽取,得到所述目标领域的目标知识图谱。
36、本技术实施例的有益效果:
37、本技术实施例提供了一种基于大模型增强的垂直领域小样本知识抽取方法,所述方法包括:获取目标领域的第一高质标注样本,并基于预先训练的大语言模型,对所述第一高质标注样本进行数据增强,得到所述目标领域的第二高质标注样本,所述第一高质标注样本包括:预设schema规则、预设知识抽取训练文本语料以及所述预设知识抽取训练文本语料对应的预设知识图谱;以从所述第二高质标注样本中提取的多个实体,以及多个所述实体中每两个实体之间的关系为训练样本,训练得到知识抽取模型;基于所述知识抽取模型,对输入所述知识抽取模型的所述目标领域的非结构化文本进行知识抽取,得到所述目标领域的目标知识图谱。
38、(1)本技术实施例通过大语言模型将少量第一高质标注样本进行数据增强,获得数量较多的第二高质标注样本,降低了数据标注的人力成本需求;
39、(2)利用大语言模型将第二高质标注样本作为训练样本训练得到知识抽取模型,使得知识抽取模型拥有更强的可持续化学习能力以及泛化能力;
40、(3)通过大语言模型生成的知识抽取模型能够灵活应用于垂直领域的多种场景,具有较好的可扩展性。
- 还没有人留言评论。精彩留言会获得点赞!