一种融合多种外部语义特征的中文司法领域命名实体识别方法
本发明属于自然语言处理中命名实体识别领域,涉及中文司法领域的命名实体识别,具体是一种融合多种外部语义特征的中文司法领域命名实体识别方法。
背景技术:
1、随着智能移动终端的普及,国内互联网用户数量迅速增长。中国互联网络信息中心发布了第50次中国互联网发展状况统计报告,报告显示,截至2022年6月,中国网民规模为10.51亿;当人们在互联网上获取信息、搜索内容以及与信息互动时,会产生大量的文本数据。为了提高中文文本的处理速度,中文自然语言处理领域的许多应用都需要中文命名实体识别的支持,包括智能推荐、问答系统、文本理解和文本生成等任务。
2、中文命名实体识别的任务主要从原始文本中识别实体,并将检测到的实体分类到预定义的类别中,如“人名”、“地名”、“组织”和其他专有名词。对于中文命名实体识别,主流的方法是建立基于词汇的模型,这些模型结合了外部词汇信息对输入文本进行语义增强从而识别文本中的实体类型。其中最典型的方法是lattice lstm(zhang,y.;yang,j.chinesener using lattice lstm.in proceedings of the 56th annual meeting of theassociation for computational linguistics(volume 1:long papers),associationfor computational linguistics,melbourne,australia,15–20july 2018;pp.1554–1564.),它将词汇知识输入到lstm网络的状态中,从而构建一种栅格方式将词汇知识引入到中文命名实体识别模型中。但该方法受构造方法的限制,词汇表示只能添加到最后一个单词,且栅格结构无法并行计算。为了解决这一问题,sui等人提出了一种基于协同图的词汇知识(sui,d.;chen,y.;liu,k.;zhao,j.;liu,s.leverage lexical knowledge forchinese named entity recognition via collaborative graph network.inproceedings of the 2019conference on empirical methods in natural languageprocessing and the 9th international joint conference on natural languageprocessing(emnlp-ijcnlp),hong kong,china,3–7november 2019;pp.3830–3840.),通过大尺寸自动分割文本进行预训练和图卷积来实现词汇的自动构建。同年,ding等人提出了一种基于图神经网络并结合多个词典的命名实体识别方法(ding,r.;xie,p.;zhang,x.;lu,w.;li,l.;si,l.a neural multi-digraph model for chinese ner withgazetteers.in proceedings of the 57th annual meeting of the association forcomputational linguistics,florence,italy,28july–2august 2019;pp.1462–1467.),使模型能够自动学习词典的特征,有助于缓解虚假匹配的问题。
3、这些方法都需要构建词典资源,并且词典的质量直接影响到命名实体的识别效果。另一种典型的方法是meng等人提出的glyce网络(meng,y.;wu,w.;wang,f.;li,x.;nie,p.;yin,f.;li,m.;han,q.;sun,x.;li,j.glyce:glyph-vectors for chinesecharacterrepresentations.in proceedings of the advances in neural informationprocessing systems;curran associates,inc.:red hook,ny,usa,2019;volume32.),该网络通过cnn网络对汉字图片进行特征提取,得到汉字的字形信息,并通过图像分类的方式将字形信息和字符信息融合,最后进行命名实体的识别。类似的,wu等人(wu,s.;song,x.;feng,z.mect:multi-metadata embedding based cross-transformer for chinesenamed entity recognition.in proceedings of the 59th annual meeting of theassociation for computational linguistics and the 11th international jointconference on natural language processing(volume 1:long papers),virtualevent,1–6august 2021;association for computational linguistics:stroudsburg,pa,usa,2021;pp.1529–1539.)通过cnn提取汉字的部首,然后通过cross-transformer模块和随机注意力机制将部首和字符信息融入模型中,以提高中文命名实体识别的准确性。但这些模型主要通过cnn对单个汉字进行字形信息的提取,字形和上下文之间的交互知识被忽略。
4、在上述工作中,中文命名实体识别达到了较高的准确率,但是对于复杂语境下的数据集效果仍然比较差,且模型结构较为复杂。本文提出的模型基于通用的bilstm-crf网络结构,通过建立一个低耦合的自适应嵌入层引入汉字部首等字形信息和多种分词等语义知识,对输入进行字形增强和词汇增强,从而提升中文命名实体识别的准确率。
技术实现思路
1、针对现有技术中存在的不足,本发明提供一种融合多种外部语义特征的中文司法领域命名实体识别方法。这种方法构建了司法标注语料,并通过多种外部语义特征对命名实体识别模型的输入进行增强,在对“案发地点、地名、人名、组织机构名、罪名、法条以及刑期”七类实体的识别上,能获得较高的f1值和识别准确率。
2、实现本发明目的的技术方案是:
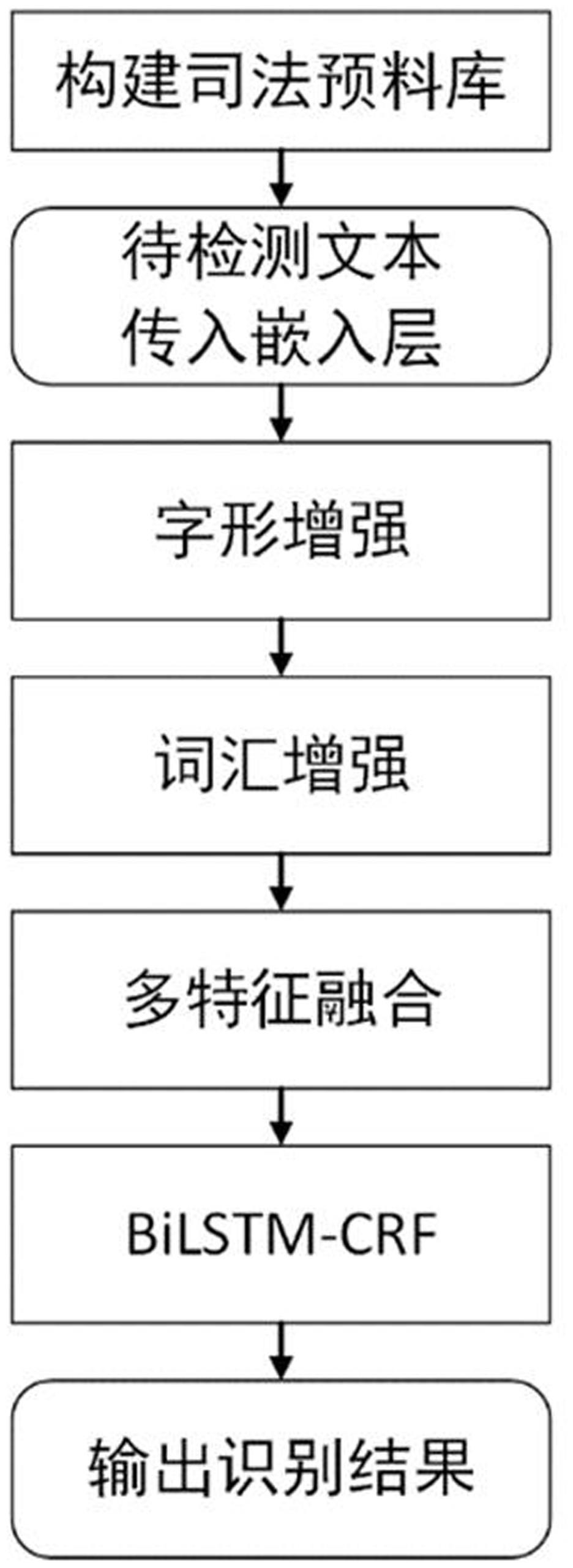
3、一种融合多种外部语义特征的中文司法领域命名实体识别方法,包括如下步骤:
4、1)构建司法语料库,首先对原始数据进行序列标注,将标注后的司法语料数据集按6:2:2的比例划分为训练集、验证集和测试集;
5、2)在数据集的全局层面构建无向字形图,利用字形图对模型嵌入层的输入数据进行字形增强;
6、3)对模型嵌入层的输入数据进行多词汇增强;
7、4)将步骤2)和步骤3)得到的两种外部语义特征增强后的输入通过门控机制进行特征融合,然后输入到bilstm-crf网络对司法领域的命名实体进行识别。
8、进一步的,步骤1)中原始数据为公开的司法裁判文书,通过构建动态词典,对司法裁判文书的七种实体类型进行序列标注,得到标注后的司法语料库,其中实体类型分别为:案发地点、地名、人名、组织机构名、罪名、法条以及刑期,标注的标签为bio格式,具体标注方法为:对于每个字符,定义m为其实体类型的标签,则b-m表示命名实体的开始,i-m即命名实体的其余部分,o则为非命名实体字符。
9、进一步的,步骤2)中字形增强的方法为:
10、2.1)构造汉字拆解字典,格式为:“字符+部首1+部首2……”;
11、2.2)将数据集中每一个字符和部首映射成一个one-hot向量作为字形图的初始节点表示,从而构建数据集层面的全局特征矩阵其中n为数据集中所有不同字符和部首的数量;
12、2.3)构造邻接矩阵用以表示字形图的边,利用汉字拆解字典和长度为l的滑动窗口对数据集进行共现统计,并通过公式(1)计算出不同节点之间的权重,
13、
14、公式(1)中pmi(i,j)为节点互信息,反映了两个节点i,j之间的关联程度,当pmi>0时,表示两个字符之间具有强语义相关性,当pmi<0时,表示两个字符之间几乎没有语义相关性,最后在权重大于0的节点之间添加边,得到所有边构成的集合为:其中(i,j)为节点i,j之间的边,ε为所有节点构成的边的集合;
15、2.4)利用动态注意力机制计算其他节点对该字符的重要性分数,首先通过公式(2)计算邻居节点j的特征对于节点i的重要性分数e(hi,hj),
16、e(hi,hj)=atleakyrelu(w·[hi‖hj]) (2)
17、其中,和是可学习的参数,hi和hj分别为节点i,j的字符表示,leakyrelu为损失函数,随后通过公式(3)对这些重要性分数进行归一化计算出邻居节点j的特征对于节点i的注意力得分αij,
18、
19、其中,为节点i所有邻居节点构成的集合,最后通过公式(4)对邻居节点进行加权求和并进行层归一化,得到最终的节点i的部首表示ei,
20、
21、进一步的,步骤3)中多词汇增强的步骤为:
22、3.1)利用三个不同的标记器对输入的文本序列s={c1,c2,…,cn}进行分词,其中ci为字符,得到三组不同的分割结果:
23、
24、
25、
26、其中w为划分出的潜在词,所有的分词结果构成潜在词集合wall=sj∪ss∪st;
27、3.2)对文本序列的每个字符ci,匹配所有相关的潜在词wci,并根据该字符在潜在词中的位置,将所有潜在词分为四类wb,wm,we,ws,用以表示该潜在词的位置信息,即wb={w|w∈wci∧ci处于w的开头位置},wm={w|wci∧ci处于w的中间位置},we={w|w∈wci∧ci处于w的末尾位置},ws={w|w∈wci∧ci=w};
28、3.3)利用公式(8)和公式(9)计算文本序列中每个字符所占的重要性分数,
29、
30、[k,q]=ec·is[wk,wq] (9)
31、其中,ac为注意力矩阵,ec为预训练的字符级嵌入,is为输入序列s的索引矩阵,将ac按列划分得到每个字符的注意力表示ac=[a1c,a2c,...,anc],其中aic为第i个字符的注意力得分,根据多个标记器获得的分割结果,对于潜在词wi,j={ci,...,cj},对其注意力得分进行组合得到由于不同潜在词的长度不同,利用公式(10)将不同长度的潜在词聚合为统一维度的注意力表示,
32、
33、其中,为潜在词wi,i+l的聚合注意力,l是潜在词的长度,maxpooling为最大池,meanpooling为平均池,是一个可训练的权重参数,用以平衡最大池和平均池;
34、3.4)利用长度为l的滑动窗口统计每个潜在词在训练集中出现的概率p(wi,i+l)作为每个潜在词的权重,通过公式(11)对同类别中所有词语的注意力表示进行加权求和,得到该类别的特征向量,
35、
36、其中,t∈{wb,wm,we,ws},最后,通过公式(12)将四个类别的特征向量拼接到每个字符的字符表示中:
37、进一步的,步骤4)中特征融合方法为:
38、4.1)利用公式(13)对字形增强和词汇增强后的字符表示做线性转换后再连接得到贡献度r,
39、
40、其中,为经过词汇增强后的输入序列,为经过字形增强后的输入序列,σ为sigmoid函数,然后利用公式(14)所示的门控机制对词汇特征和字形特征动态加权得到特征融合后的字符级表示o,
41、
42、其中,o=[o1,…,oi,…,on]是门控机制的输出,是一个全1的矩阵,⊙为逐元素的乘法运算,为向量连接操作;最后将o输入到bilstm-crf网络,在识别过程中,最高概率值所对应的标签序列即为最优的命名实体识别结果。
43、本发明方法与现有方法相比,具有如下优点:
44、1.本发明通过构建动态词典对司法裁判文书进行标注,减少了手动标注数据的人工和时间成本,并且有利于司法语料库的扩充。
45、2.本发明中的字形增强能提高模型对类别信息的推理能力,提高了司法文本中构结构复杂且频次低的“案发地点”实体类别的识别能力。
46、3.本发明通过引入多种词汇信息进行词汇增强,提高了司法文本中大量形式相近的“法条”和“罪名”实体类别的识别能力。
47、4.本发明通过多种外部语义特征增强,减少了对司法标注语料的依赖,针对有限的司法标注语料,提高了对司法领域命名实体的识别准确率和f1指标。
- 还没有人留言评论。精彩留言会获得点赞!