一种档案智能分类与检索方法与流程
本发明涉及分类检索的,尤其涉及一种档案智能分类与检索方法。
背景技术:
1、随着信息技术的快速发展,高校信息化程度大幅提高,高校工作人员电子档案数量快极速膨胀,高校电子档案管理工作面临着巨大的挑战和机遇,需要更加高效、智能的管理模式来应对日益复杂的需求。传统高校档案管理模式主要是手工操作,难以保证信息的安全性和完整性,容易产生错误并且进行检索时也存在极大难度,难以满足高校信息化建设的现代化需求,其弊端也愈加突出,亟需一种智能化、自动化的电子档案管理方法。针对该问题,本发明提出一种档案智能分类与检索方法,通过人工智能技术实现电子档案的智能化理解和自适应分类检索,提高电子档案的智能化管理水平。
技术实现思路
1、有鉴于此,本发明提供一种档案智能分类与检索方法,目的在于:1)根据电子档案中不同候选词的句数以及间隔词数计算得到候选词间的位置距离,基于位置距离与窗口阈值的比较,建立候选词间的边关系,构建得到词图模型,并生成表示候选词位置重要性以及词频重要性的候选词位置特征,tfidf特征,根据所生成的特征,计算得到候选词之间的跳转概率,初始化概率转移矩阵,根据概率转移矩阵的迭代计算结果,确定候选词的重要性权重,作为候选词的初始得分,计算候选词重要性的量化;2)根据候选词在词图模型中的节点度数,确定候选词在k核子图中的所属层级,其中节点度数越高则表示候选词与其他候选词的关联程度越高,所属层级越高,并利用平均信息熵特征过滤掉出现次数多但信息量不多的候选词,实现电子档案中关键词的确定,根据电子档案关键词进行档案分类并支持基于关键词的档案快速检索。
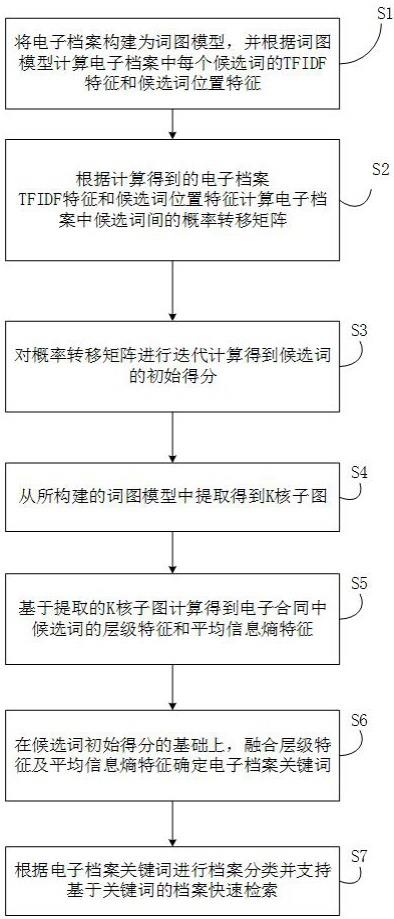
2、实现上述目的,本发明提供的一种档案智能分类与检索方法,包括以下步骤:
3、s1:将电子档案构建为词图模型,并根据词图模型计算电子档案中每个候选词的tfidf特征和候选词位置特征;
4、s2:根据计算得到的电子档案tfidf特征和候选词位置特征计算电子档案中候选词间的概率转移矩阵;
5、s3:对概率转移矩阵进行迭代计算,得到候选词的初始得分;
6、s4:从所构建的词图模型中提取得到k核子图;
7、s5:基于提取的k核子图计算得到电子合同中候选词的层级特征和平均信息熵特征;
8、s6:在候选词初始得分的基础上,融合层级特征及平均信息熵特征确定电子档案关键词;
9、s7:根据电子档案关键词进行档案分类并支持基于关键词的档案快速检索。
10、作为本发明的进一步改进方法:
11、可选地,所述s1步骤中将电子档案构建为词图模型,包括:
12、将电子档案构建为词图模型,其中第i份电子档案的词图模型构建流程为:
13、s11:对电子档案进行分句分词处理,其中分句分词处理结果为:
14、<mi>{</mi><msubsup><mi>x</mi><mi>i</mi><mi>j</mi></msubsup><mi>=(</mi><msubsup><mi>x</mi><mi>i</mi><mi>j</mi></msubsup><mi>(1),</mi><msubsup><mi>x</mi><mi>i</mi><mi>j</mi></msubsup><mi>(2),...,</mi><msubsup><mi>x</mi><mi>i</mi><mi>j</mi></msubsup><mi>(</mi><msub><mi>r</mi><mi>j</mi></msub><mi>),...,</mi><msubsup><mi>x</mi><mi>i</mi><mi>j</mi></msubsup><mi>(</mi><msub><mi>num</mi><mi>j</mi></msub><mi>))|j∈[1,j],</mi><msub><mi>r</mi><mi>j</mi></msub><mi>∈[1,</mi><msub><mi>num</mi><mi>j</mi></msub><mi>]}</mi>
15、其中:
16、表示电子档案中第j个句子的分词处理结果,表示电子档案的句子总数;
17、表示分词处理结果中的第个词语,表示分词处理结果中的词语总数;
18、在本发明实施例中,利用标点符号对电子档案进行分句处理,利用jieba分词工具对电子档案的每个句子进行分词处理,并去除分词处理后的停用词,得到分句分词处理结果,其中停用词包括语气词、介词等;
19、s12:从电子档案的分句分词处理结果中提取名词作为电子档案的候选词,则电子档案的去重后候选词集合为:
20、<mi>{</mi><msub><mi>x</mi><mi>i</mi></msub><mi>(m)|m∈[1,</mi><msub><mi>m</mi><mi>i</mi></msub><mi>]}</mi>
21、其中:
22、表示电子档案中的第个候选词,表示电子档案的候选词总数;
23、s13:将候选词作为词图模型的节点,并计算不同节点之间的位置距离,若两个节点之间的位置距离小于预设的窗口阈值,则两个节点之间存在边,否则不存在边,其中候选词与之间的位置距离为:
24、
25、其中:
26、表示以自然常数为底的指数函数;
27、表示候选词与之间的位置距离,<msup><mi>m</mi><mi>'</mi></msup><mi>∈[1,</mi><msub><mi>m</mi><mi>i</mi></msub><mi>]</mi>,且;
28、表示电子档案分句分词处理结果中候选词与之间的词语数目;
29、表示候选词在电子档案分句分词处理结果中的出现句数,<mi>l(</mi><msub><mi>x</mi><mi>i</mi></msub><mi>(m))</mi><mi>∈</mi><mi>[1,j]</mi>,即候选词在第个句子出现;表示候选词在电子档案分句分词处理结果中的出现句数,<mi>l(</mi><msub><mi>x</mi><mi>i</mi></msub><mi>(</mi><msup><mi>m</mi><mi>'</mi></msup><mi>))</mi><mi>∈</mi><mi>[1,j]</mi>;
30、在本发明实施例中,同一候选词可能在电子档案中的不同位置重复出现,因此选取使得位置距离达到最小的两个候选词位置,计算得到两个候选词的位置距离;
31、s14:将节点以及节点之间的边信息构成词图模型,则电子档案所构成的词图模型为:
32、其中:
33、表示电子档案所构成的词图模型,包括个候选词节点信息,以及候选词节点之间的边信息;
34、,表示不同候选词在词图模型之间的边信息;
35、若小于预设的窗口阈值,,表示候选词与在词图模型中存在边,否则表示候选词与在词图模型中不存在边。
36、可选地,所述s1步骤中根据词图模型计算电子档案中每个候选词的tfidf特征和候选词位置特征,包括:
37、根据所构建的词图模型计算得到电子档案中每个候选词的tfidf特征和候选词位置特征,其中电子档案中第个候选词的tfidf特征和候选词位置特征计算公式为:
38、
39、<mi>dis(</mi><msub><mi>x</mi><mi>i</mi></msub><mi>(m)</mi><mi>)=</mi><mfrac><mstyle displaystyle="true"><munder><mo>∑</mo><mo><msup><mi>m</mi><mi>'</mi></msup><mi>∈[1,</mi><msub><mi>m</mi><mi>i</mi></msub><mi>],</mi><msup><mi>m</mi><mi>'</mi></msup><mi>≠</mi><mi>m</mi></mo></munder><mrow><mi>α(</mi><msub><mi>x</mi><mi>i</mi></msub><mi>(m),</mi><msub><mi>x</mi><mi>i</mi></msub><mi>(</mi><msup><mi>m</mi><mi>'</mi></msup><mi>))</mi><mi>dis</mi><mi>(</mi><msub><mi>x</mi><mi>i</mi></msub><mi>(m),</mi><msub><mi>x</mi><mi>i</mi></msub><mi>(</mi><msup><mi>m</mi><mi>'</mi></msup><mi>))</mi></mrow></mstyle><mstyle displaystyle="true"><munder><mo>∑</mo><mo><msup><mi>m</mi><mi>'</mi></msup><mi>∈[1,</mi><msub><mi>m</mi><mi>i</mi></msub><mi>],</mi><msup><mi>m</mi><mi>'</mi></msup><mi>≠</mi><mi>m</mi></mo></munder><mrow><mi>α(</mi><msub><mi>x</mi><mi>i</mi></msub><mi>(m),</mi><msub><mi>x</mi><mi>i</mi></msub><mi>(</mi><msup><mi>m</mi><mi>'</mi></msup><mi>))</mi></mrow></mstyle></mfrac>
40、其中:
41、表示候选词在电子档案分句分词处理结果中出现的次数;
42、表示电子档案分句分词处理结果中的词语总数;在本发明实施例中,
43、;
44、n表示电子档案总份数;
45、表示存在候选词语的电子档案份数;
46、表示候选词的tfidf特征;
47、表示候选词的候选词位置特征。
48、可选地,所述s2步骤中计算电子档案中候选词间的概率转移矩阵,包括:
49、根据计算得到的电子档案tfidf特征和候选词位置特征计算电子档案中候选词间的概率转移矩阵,其中电子档案的概率转移矩阵计算流程为:
50、计算得到电子档案中候选词经由词图模型跳转到候选词的跳转概率
51、:
52、
53、
54、其中:
55、表示候选词的跳转权值;
56、根据跳转概率生成电子档案的概率转移矩阵:
57、
58、
59、其中:
60、表示电子档案中候选词的概率转移矩阵;
61、表示电子档案的概率转移矩阵。
62、可选地,所述s3步骤中对概率转移矩阵进行迭代计算,得到候选词的初始得分,包括:
63、对概率转移矩阵进行迭代计算得到候选词的初始得分,其中电子档案中候选词的初始得分计算流程为:
64、s31:根据电子档案的概率转移矩阵生成电子档案中每个候选词的权重,其中候选词的权重为:
65、
66、其中:
67、表示电子档案中候选词的权重;
68、表示阻尼系数,将设置为0.8;
69、s32:构成电子档案中个候选词的权重矩阵:
70、
71、s33:设置权重矩阵的当前迭代次数为t,t的初始值为0,则权重矩阵的第t次迭代结果为;
72、s34:对权重矩阵进行迭代,其中权重矩阵的迭代公式为:
73、
74、若小于预设的迭代阈值,则终止迭代,将作为最终权重矩阵,最终权重矩阵的第m列的元素值即为电子档案中候选词的初始得分;
75、否则令,返回步骤s34。
76、可选地,所述s4步骤中从词图模型中提取得到k核子图,包括:
77、从所构建的词图模型中提取得到k核子图,其中词图模型中的k核子图提取流程为:
78、s41:初始化k=0,初始化集合,将词图模型存储到集合中,并初始化集合,集合为空;
79、s42:对集合中的所有词图模型节点进行遍历,筛选得到节点度数小于k的词图模型节点,并将所筛选得到词图模型节点存储到集合中,作为k核子图中的第k个层级节点;
80、将所筛选得到的词图模型节点以及节点所连接的边从集合中递归删除;
81、s43:若小于k,则令,返回步骤s42。在本发明实施例中,节点度数即为节点所连接的边数。
82、可选地,所述s5步骤中基于k核子图计算得到电子合同中候选词的层级特征和平均信息熵特征,包括:
83、基于所提取的k核子图计算得到电子合同中候选词的层级特征和平均信息熵特征,其中电子档案中候选词的层级特征和平均信息熵特征的计算流程为:
84、获取电子档案中候选词所对应节点在k核子图中的层级特征:
85、
86、其中:
87、表示词图模型中与候选词所对应节点存在边的节点集合,,e表示节点集合中的任意节点;
88、表示计算节点在k核子图中的层级数;
89、获取电子档案中候选词的平均信息熵特征:
90、
91、其中:
92、表示候选词在电子档案分句分词处理结果中出现的次数;
93、n表示电子档案总份数;
94、表示候选词在所有电子档案分句分词处理结果中出现的次数。
95、可选地,所述s6步骤中在候选词初始得分的基础上,融合层级特征及平均信息熵特征确定电子档案关键词,包括:
96、基于候选词初始得分,融合层级特征及平均信息熵特征确定电子档案关键词,其中电子档案中关键词的确定流程为:
97、计算电子档案中候选词的关键词得分:
98、
99、其中:
100、表示电子档案中候选词的关键词得分;
101、表示电子档案中候选词的初始得分;
102、表示电子档案中候选词的融合层级特征;
103、表示电子档案中候选词的平均信息熵特征;
104、选取关键词得分最高的候选词作为电子档案的类别,并选取关键词得分最高的5个候选词作为电子档案的关键词。
105、可选地,所述s7步骤中根据电子档案关键词进行档案分类并进行基于关键词的档案快速检索,包括:
106、根据关键词得分最高的候选词对电子档案进行分类,并将电子档案的关键词作为电子档案的检索词,通过查询检索词进行电子档案的快速检索。
107、为了解决上述问题,本发明提供一种电子设备,所述电子设备包括:
108、存储器,存储至少一个指令;
109、通信接口,实现电子设备通信;及
110、处理器,执行所述存储器中存储的指令以实现上述所述的档案智能分类与检索方法。
111、为了解决上述问题,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一个指令,所述至少一个指令被电子设备中的处理器执行以实现上述所述的档案智能分类与检索方法。
112、相对于现有技术,本发明提出一种档案智能分类与检索方法,该技术具有以下优势:
113、首先,本方案提出一种词语重要性量化方式,根据计算得到的电子档案tfidf特征和候选词位置特征计算电子档案中候选词间的概率转移矩阵,其中电子档案的概率转移矩阵计算流程为:
114、计算得到电子档案中候选词经由词图模型跳转到候选词的跳转概率
115、:
116、
117、
118、其中:表示候选词的跳转权值;根据跳转概率生成电子档案的概率转移矩阵:
119、
120、
121、其中:表示电子档案中候选词的概率转移矩阵;表示电子档案的概率转移矩阵。对概率转移矩阵进行迭代计算得到候选词的初始得分,其中电子档案中候选词的初始得分计算流程为:根据电子档案的概率转移矩阵生成电子档案中每个候选词的权重,其中候选词的权重为:
122、
123、其中:表示电子档案中候选词的权重;表示阻尼系数,将设置为0.8;构成电子档案中个候选词的权重矩阵:
124、
125、设置权重矩阵的当前迭代次数为t,t的初始值为0,则权重矩阵的第t次迭代结果为;对权重矩阵进行迭代,其中权重矩阵的迭代公式为:
126、
127、若小于预设的迭代阈值,则终止迭代,将作为最终权重矩阵,最终权重矩阵的第m列的元素值即为电子档案中候选词的初始得分。本方案根据电子档案中不同候选词的句数以及间隔词数计算得到候选词间的位置距离,基于位置距离与窗口阈值的比较,建立候选词间的边关系,构建得到词图模型,并生成表示候选词位置重要性以及词频重要性的候选词位置特征,tfidf特征,根据所生成的特征,计算得到候选词之间的跳转概率,初始化概率转移矩阵,根据概率转移矩阵的迭代计算结果,确定候选词的重要性权重,作为候选词的初始得分,计算候选词重要性的量化。
128、同时,本方案提出一种电子档案关键词确定方法,从所构建的词图模型中提取得到k核子图,其中词图模型中的k核子图提取流程为:初始化k=0,初始化集合,将词图模型存储到集合中,并初始化集合,集合为空;对集合中的所有词图模型节点进行遍历,筛选得到节点度数小于k的词图模型节点,并将所筛选得到词图模型节点存储到集合中,作为k核子图中的第k个层级节点;将所筛选得到的词图模型节点以及节点所连接的边从集合中递归删除;若小于k,则令。基于所提取的k核子图计算得到电子合同中候选词的层级特征和平均信息熵特征,其中电子档案中候选词的层级特征和平均信息熵特征的计算流程为:
129、获取电子档案中候选词所对应节点在k核子图中的层级特征:
130、
131、其中:表示词图模型中与候选词所对应节点存在边的节点集合,,e表示节点集合中的任意节点;表示计算节点在k核子图中的层级数;获取电子档案中候选词的平均信息熵特征:
132、
133、其中:表示候选词在电子档案分句分词处理结果中出现的次数;n表示电子档案总份数;表示候选词在所有电子档案分句分词处理结果中出现的次数。本方案根据候选词在词图模型中的节点度数,确定候选词在k核子图中的所属层级,其中节点度数越高则表示候选词与其他候选词的关联程度越高,所属层级越高,并利用平均信息熵特征过滤掉出现次数多但信息量不多的候选词,实现电子档案中关键词的确定,根据电子档案关键词进行档案分类并支持基于关键词的档案快速检索。
- 还没有人留言评论。精彩留言会获得点赞!