数据库字段识别方法、装置、计算机设备及存储介质与流程
本发明属于数据库处理方法,具体涉及数据库字段识别方法、装置、计算机设备及存储介质。
背景技术:
1、在通常的数据分类分级流程中,对于数据的识别需要定义好发现规则,如字段内容正则、字段名称正则等,对于匹配到的数据可以正常进行识别进而被发现,但是对于一些无匹配和无法匹配的数据,则需要人工去做修正和确认。实际情况中,这个需要修正和确认的量非常庞大,基于主观性的人工分类分级效率非常低下,很难做知识的积累和复用。因此,分类分级过程中的人工成本较高,字段识别效率也非常低。
技术实现思路
1、本发明提供一种数据库字段识别方法,实现减少分类分级过程中的人工成本,提高字段识别的效率。
2、为实现上述目的,本发明采用以下技术方案:数据库字段识别方法,包括:
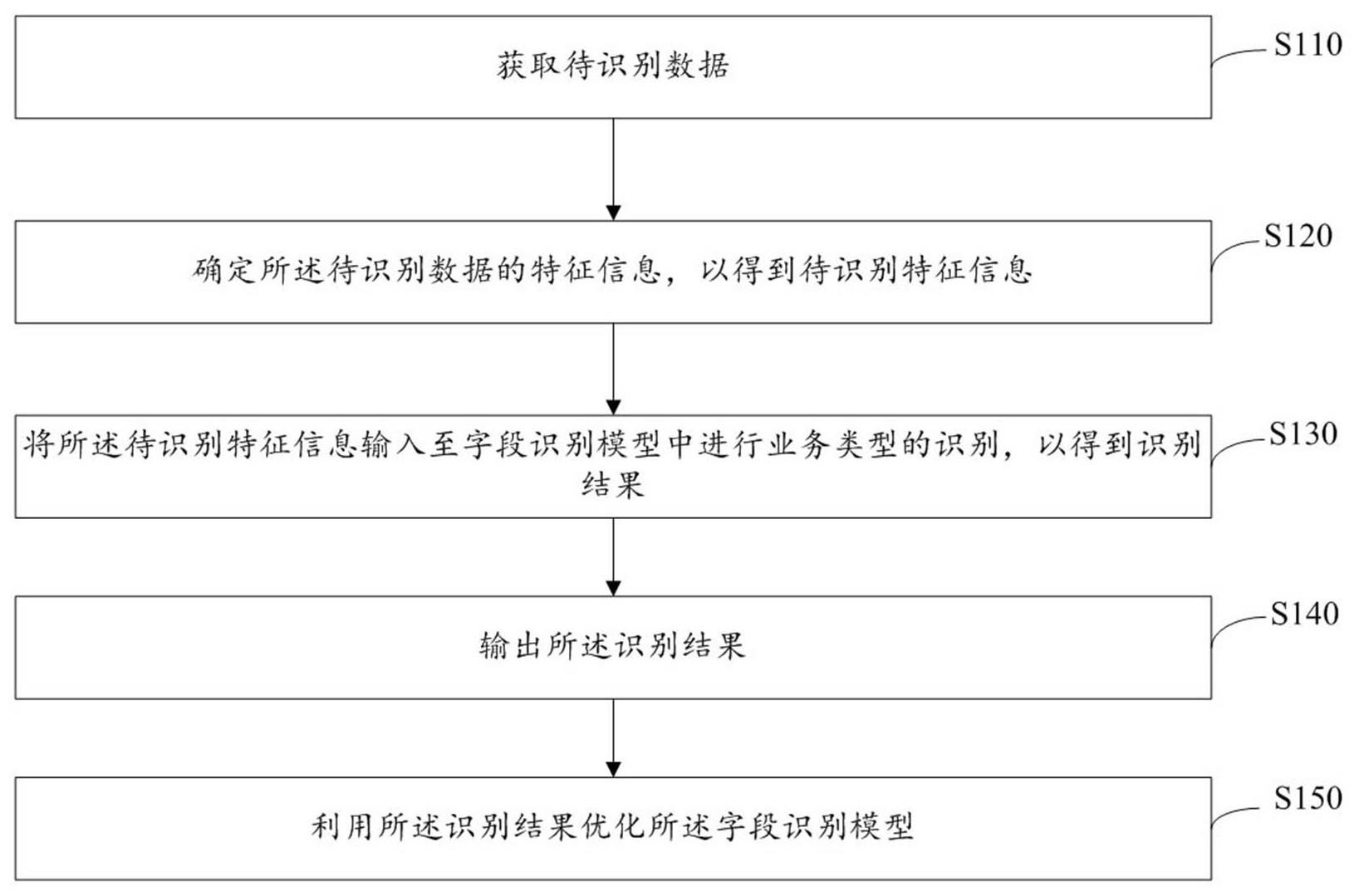
3、获取待识别数据;
4、确定所述待识别数据的特征信息,以得到待识别特征信息;
5、将所述待识别特征信息输入至字段识别模型中进行业务类型的识别,以得到识别结果;
6、输出所述识别结果;
7、利用所述识别结果优化所述字段识别模型;
8、其中,所述字段识别模型是通过带有业务类型的数据库数据所对应的特征信息作为样本集训练xgboost模型所得的;
9、所述确定所述待识别数据的特征信息,以得到待识别特征信息,包括:
10、对所述待识别数据进行清洗,以得到清洗结果;
11、对所述清洗结果进行特征计算,以得到原始特征;
12、将所述原始特征进行特征变换,以得到变换结果;
13、对所述变换结果进行特征降维,以得到待识别特征信息;
14、所述原始特征包含元数据维度原始特征和值维度原始特征,元数据维度原始特征包括列名称、列类型、列注释;所述值维度原始特征的个数为三百个;
15、所述数据库数据为表级统计数据,表级统计数据包括表级记录条数范围以及表包含的字段个数范围,采用范围的方式提取列位置信息和表级统计数据特征。
16、作为优选,所述将所述原始特征进行特征变换,以得到变换结果,包括:
17、采用词袋模型将所述原始特征进行特征变换,以得到变换结果。
18、作为优选,所述将所述原始特征进行特征变换,以得到变换结果,包括:
19、采用tf-idf将所述原始特征进行特征变换,以得到变换结果。
20、作为优选,所述利用所述识别结果优化所述字段识别模型,包括:
21、将识别结果以及对应的特征信息更新样本集,并重新训练所述字段识别模型。
22、作为优选,所述对所述变换结果进行特征降维,以得到待识别特征信息,包括:
23、采用pca、lda特征降维方法对所述变换结果进行特征降维,以得到待识别特征信息。
24、本发明还提供了数据库字段识别装置,包括:
25、数据获取单元,用于获取待识别数据;
26、特征确定单元,用于确定所述待识别数据的特征信息,以得到待识别特征信息;
27、识别单元,用于将所述待识别特征信息输入至字段识别模型中进行业务类型的识别,以得到识别结果;
28、输出单元,用于输出所述识别结果;
29、优化单元,用于利用所述识别结果优化所述字段识别模型;
30、其中,所述字段识别模型是通过带有业务类型的数据库数据所对应的特征信息作为样本集训练xgboost模型所得的;
31、所述特征确定单元包括清洗子单元、特征选择子单元、特征变换子单元以及特征降维子单元;
32、清洗子单元,用于对所述待识别数据进行清洗,以得到清洗结果;特征选择子单元,用于对所述清洗结果进行特征计算,以得到原始特征;特征变换子单元,用于将所述原始特征进行特征变换,以得到变换结果;特征降维子单元,用于对所述变换结果进行特征降维,以得到待识别特征信息;
33、所述原始特征包含元数据维度原始特征和值维度原始特征,元数据维度原始特征包括列名称、列类型、列注释;所述值维度原始特征的个数为三百个。
34、作为优选,所述特征变换子单元,用于采用词袋模型将所述原始特征进行特征变换,以得到变换结果;
35、所述特征变换子单元,用于采用tf-idf将所述原始特征进行特征变换,以得到变换结果;
36、优化单元,用于将识别结果以及对应的特征信息更新样本集,并重新训练所述字段识别模型;
37、所述特征降维子单元,用于采用pca、lda特征降维方法对所述变换结果进行特征降维,以得到待识别特征信息。
38、本发明还提供了一种计算机设备,所述计算机设备包括存储器及处理器,所述存储器上存储有计算机程序,所述处理器执行所述计算机程序时实现上述的方法。
39、本发明还提供了一种存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述的方法。
40、本发明与现有技术相比的有益效果是:
41、本发明通过确定待识别数据的特征信息,并采用字段识别模型中进行业务类型的识别,且将识别的结果作为样本集持续优化字段识别模型,而且预测和训练的过程,基于特征工程的分类分级,基于模型本身实现了知识的积累和复用,很大程度上降低了对人的主观性依赖,实现减少分类分级过程中的人工成本,提高字段识别的效率。
技术特征:
1.数据库字段识别方法,其特征在于,包括:
2.根据权利要求1所述的数据库字段识别方法,其特征在于,所述将所述原始特征进行特征变换,以得到变换结果,包括:
3.根据权利要求1所述的数据库字段识别方法,其特征在于,所述将所述原始特征进行特征变换,以得到变换结果,包括:
4.根据权利要求1所述的数据库字段识别方法,其特征在于,所述利用所述识别结果优化所述字段识别模型,包括:
5.根据权利要求1所述的数据库字段识别方法,其特征在于,所述对所述变换结果进行特征降维,以得到待识别特征信息,包括:
6.根据权利要求2所述的数据库字段识别方法,其特征在于,所述数据库数据为表级统计数据,表级统计数据包括表级记录条数范围以及表包含的字段个数范围,采用范围的方式提取列位置信息和表级统计数据特征。
7.数据库字段识别装置,其特征在于,包括:
8.根据权利要求7所述的数据库字段识别装置,其特征在于,所述特征变换子单元,用于采用词袋模型将所述原始特征进行特征变换,以得到变换结果;
9.一种计算机设备,其特征在于,所述计算机设备包括存储器及处理器,所述存储器上存储有计算机程序,所述处理器执行所述计算机程序时实现如权利要求1至6中任一项所述的方法。
10.一种存储介质,其特征在于,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至6中任一项所述的方法。
技术总结
本发明公开了数据库字段识别方法、装置、计算机设备及存储介质。数据库字段识别方法包括:获取待识别数据;确定所述待识别数据的特征信息,以得到待识别特征信息;将所述待识别特征信息输入至字段识别模型中进行业务类型的识别,以得到识别结果;输出所述识别结果;利用所述识别结果优化所述字段识别模型;其中,所述字段识别模型是通过带有业务类型的数据库数据所对应的特征信息作为样本集训练XGBoost模型所得的。通过实施本发明的方法可实现减少分类分级过程中的人工成本,提高字段识别的效率。
技术研发人员:朱国耀,张浩,张立强,周杰
受保护的技术使用者:杭州美创科技股份有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!