基于SQL的通用大数据导出方法及系统与流程
本发明涉及移动通信,具体地说是一种基于sql的通用大数据导出方法及系统。
背景技术:
1、随着移动通信的应用越来越广泛,在移动资源领域,大数据导出存在线程占用大、内存消耗高、效率处理慢、文件存储不安全以及无通用支撑能力的缺点,不能满足用户大数据导出的应用需求。
2、sql语言,是结构化查询语言(structured query language)的简称。sql语言是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。sql语言是高级的非过程化编程语言,允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式,所以具有完全不同底层结构的不同数据库系统可以使用相同的结构化查询语言作为数据输入与管理的接口。sql语言语句可以嵌套,这使他具有极大的灵活性和强大的功能。
3、故如何利用sql语句进行大数据导出,保证导出服务的一致性,提高开发效率,同时保证内存占用、处理效率及文件存储是目前亟待解决的技术问题。
技术实现思路
1、本发明的技术任务是提供一种基于sql的通用大数据导出方法及系统,来解决如何利用sql语句进行大数据导出,保证导出服务的一致性,提高开发效率,同时保证内存占用、处理效率及文件存储的问题。
2、本发明的技术任务是按以下方式实现的,一种基于sql的通用大数据导出方法,该方法是基于游标方式查询数据,逐行读取数据库查询结果,并逐行写入到excel文件中,当达到设定数量是,将当前结果写入到一个excel文件中,再继续读取下一批数据,重复读取及写入数据的过程直到查询结果全部处理完成;同时,根据指定的文件大小,自动分割成多个excel文件,并将所有文件打包成zip文件,再通过feign的方式对完共享。
3、作为优选,该方法具体如下:
4、s1、通过调用getexcelwriter和getexcelwritesheet方法获取excelwri ter和writesheet对象,用于写入数据到excel文件;
5、s2、使用jdbctemplate.query方法执行sql查询,并通过rowcallbackha ndler处理每一行的结果集;
6、s3、在processrow方法中,将结果集转换为map数据,并添加到resultlist中;
7、s4、每当resultlist的大小达到fetchsize时,表示达到了需要分割的大小阈值,将文件分割成多个excel文件;
8、s5、判断resultlist中是否还有剩余的数据:
9、若有,则执行步骤s6;
10、s6、检查并开启新的写入文件;
11、s7、将剩余的数据写入新的excel文件中;
12、s8、关闭最后一个excelwriter对象;
13、s9、调用zipexcelfiles方法将所有excel文件打包成zip文件。
14、更优地,步骤s5中的将文件分割成多个excel文件具体如下:
15、s501、更新当前文件大小curfilesize,若超过预定的文件大小filesize,则需要开启新的写入文件;
16、s502、关闭当前的excelwriter对象,并通过getexcelwriter方法获取新的excelwriter对象;
17、s503、获取新的writesheet对象;
18、s504、将resultlist中的数据写入excel文件中;
19、s505、清空resultlist,准备接收下一批数据。
20、一种基于sql的通用大数据导出系统,该系统包括:
21、对象获取模块,用于通过调用getexcelwriter和getexcelwritesheet方法获取excelwriter和writesheet对象,用于写入数据到excel文件;
22、查询及处理模块,用于使用jdbctemplate.query方法执行sql查询,并通过rowcallbackhandler处理每一行的结果集;
23、转换及添加模块,用于在processrow方法中,将结果集转换为map数据,并添加到resultlist中;
24、分割模块,用于当resultlist的大小达到fetchsize时,表示达到了需要分割的大小阈值,将文件分割成多个excel文件;
25、判断模块,用于判断resultlist中是否还有剩余的数据:
26、检查及开启模块,用于检查并开启新的写入文件;
27、写入模块,用于将剩余的数据写入新的excel文件中;
28、关闭模块,用于关闭最后一个excelwriter对象;
29、打包模块,用于调用zipexcelfiles方法将所有excel文件打包成zip文件。
30、作为优选,所述分割模块包括:
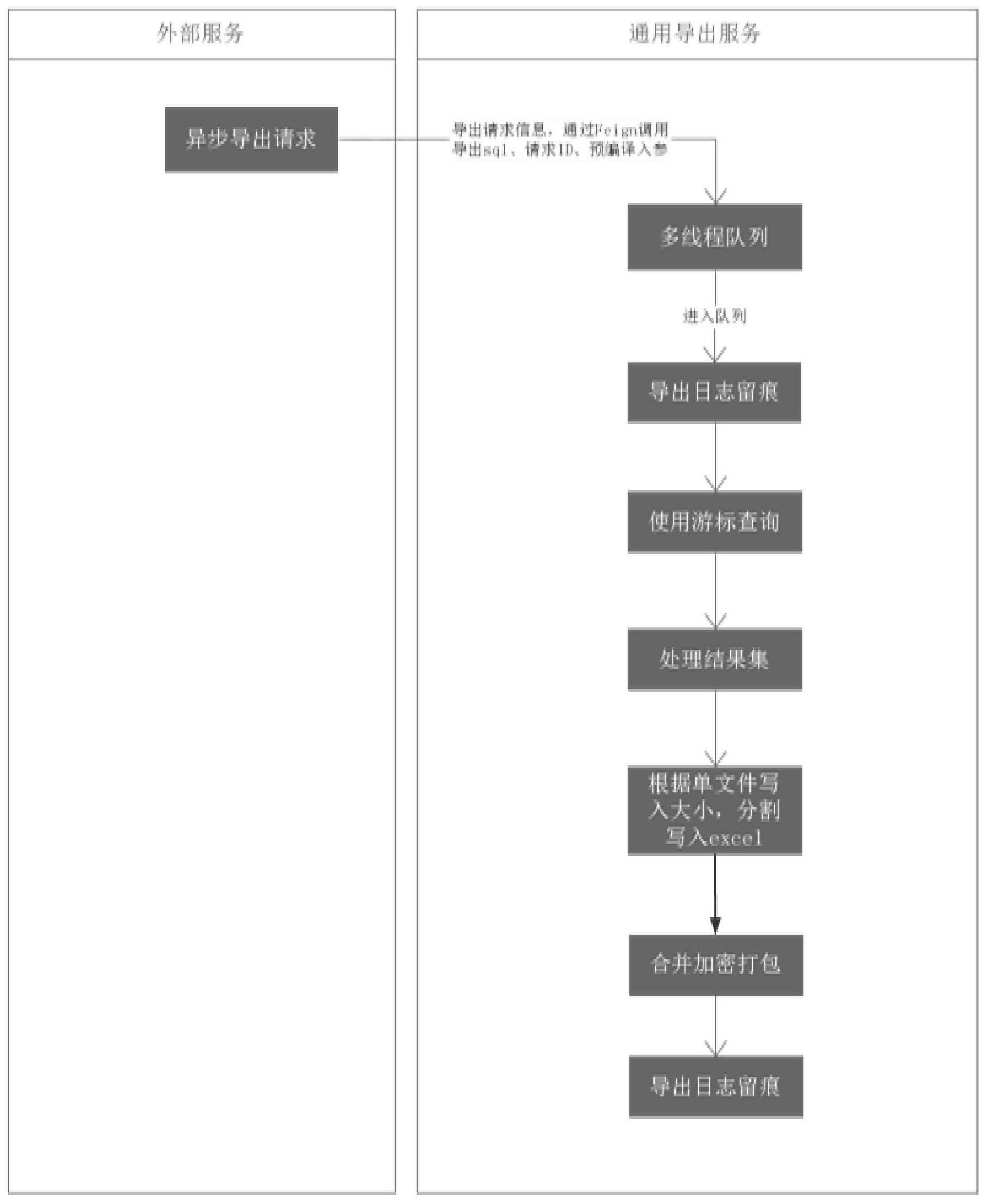
31、更新子模块,用于更新当前文件大小curfilesize,若超过预定的文件大小filesize,则需要开启新的写入文件;
32、关闭子模块,用于关闭当前的excelwriter对象,并通过getexcelwriter方法获取新的excelwriter对象;
33、获取子模块,用于获取新的writesheet对象;
34、写入子模块,用于将resultlist中的数据写入excel文件中;
35、清空子模块,用于清空resultlist,准备接收下一批数据。
36、更优地,该系统的工作过程具体如下:
37、(1)外部服务发送异步导出请求到通用导出服务;
38、(2)外部服务导出请求信息,通过feign调用导出sql、请求id及预编译入参,通用导出服务开启多线程队列;
39、(3)多线程进入队列,通用导出服务导出日志留痕;
40、(4)通用导出服务使用游标查询;
41、(5)通用导出服务获取处理结果集;
42、(6)通用导出服务根据单文件写入大小,分割写入excel;
43、(7)通用导出服务合并加密打包;
44、(8)通用导出服务导出日志留痕。
45、一种电子设备,包括:存储器和至少一个处理器;
46、其中,所述存储器上存储有计算机程序;
47、所述至少一个处理器执行所述存储器存储的计算机程序,使得所述至少一个处理器执行如上述的基于sql的通用大数据导出方法。
48、一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序可被处理器执行以实现如上述的基于sql的通用大数据导出方法。
49、本发明的基于sql的通用大数据导出方法及系统具有以下优点:
50、(一)本发明作为通用能力供其他服务调用,提升业务开发运维效率,保障了业务的稳定性;
51、(二)本发明基于spring cloud的开发架构,对外共享使用fegin方式,方便其他服务调用;
52、(三)本发明基于多线程技术实现,控制导出的并发数量,减少内存占用;
53、(四)本发明基于游标方式和分页方式结合在一起使用,通过游标方式查询数据库,一次性读取指定数量的结果集到内存中,并将结果集分页处理,这种方式可以将数据分批次处理,减少内存占用,提高处理效率;
54、(五)本发明使用多excel存储,合并加密打包方式,将大数据分割成多个excel,然后合并加密打包成zip包提供下载,解决了系统安全的问题;、
55、(六)外部服务可将查询sql语句传递给此服务,由此服务进行通用导出,保证了导出服务的一致性,提高了开发效率,保证了内存占用、处理效率和文件存储;
56、(七)本发明基于游标方式查询数据,并将结果写入excel文件中,同时支持按照指定大小分割成多个excel文件,并将所有文件打包成zip文件,并通过feign的方式对外共享,解决了在移动资源领域,大数据导出存在的线程占用大、内存消耗高、效率处理慢、文件存储不安全、无通用支撑能力的问题;
57、(八)本发明结合了游标方式查询数据和分页处理的优势,充分考虑了内存占用、性能和扩展性等方面的因素,适用于处理大数据量的场景,并提供了灵活的参数配置和多线程支持,能够有效提高数据处理效率和系统性能,有效支撑了移动资源领域大数据导出的业务场景,具体如下:
58、①内存占用较低:使用游标方式查询数据,通过逐行读取和处理结果集的方式,避免将所有结果集加载到内存中,从而降低了内存占用量,这对于大型数据集来说尤为重要,可以有效避免内存溢出的问题;
59、②高效处理大数据量:通过分批处理数据,每次读取一定数量的结果集并写入到excel文件中,可以有效减少对数据库和文件系统的压力,提高处理大数据量的效率;同时,将结果集按照指定大小分割成多个excel文件,可以更好地管理和操作大型数据集;
60、③支持多线程处理:由于使用了游标方式查询数据,可以将查询操作与结果处理操作分离,并发执行多个查询任务,实现并行处理,这样可以充分利用系统的多核处理能力,提高并发性能和响应速度;
61、④可扩展性和灵活性:通过在代码中设置合适的参数,如fetchsize、pagesize等,可以根据实际需求灵活调整数据的获取和处理方式;同时,代码结构清晰,易于扩展和修改,可以根据具体业务需求进行定制化的修改和优化。
- 还没有人留言评论。精彩留言会获得点赞!