一种实时迁移的动态GPU调度方法及系统与流程
本发明涉及gpu动态调度,尤其是一种实时迁移的动态gpu调度方法及系统。
背景技术:
1、gpu(graphics processing unit,图形处理器)最初是为了处理电脑图形显示而设计的,但在近年来,由于其并行计算能力强大的特点,被广泛应用于其他计算领域,尤其是深度学习。深度学习涉及较多的矩阵乘法和张量运算,gpu在处理这些运算上具有天然优势,gpu由多个流式多处理器构成,数据被分散到各个流式多处理器上进行并行运算从而提高模型训练和推理的速度。随着chatgpt的出现,生成式大模型受到了学术界和工业界的重视。然而,由于生成式大模型需要大量的训练样本,且参数量巨大,因此单个gpu并不能胜任其训练任务,因此在实际训练生成式大模型时,往往使用gpu集群进行训练。
2、目前在使用gpu集群进行生成式大模型训练时,模型参数被拆分并部署在了集群中的各个gpu中,这些参数隶属于模型的不同结构(或不同层),在模型训练时,不同参数之间是相互关联的,但不同参数之间更新复杂度存在不同。因此在不同的时刻或是不同的训练批次中,不同gpu之间的计算量是不相同的,即gpu占用率不同。若训练时的参数按照固定模式进行部署的,即模型参数部署完成后就一直在其所部署的gpu上进行参数更新。然而gpu的占用率会影响参数更新的时间,如gpu1的占用率为50%,gpu2的占用率为100%,那么gpu1的算力是冗余的,gpu1能在较短的时间内完成参数的更新,而gpu2为满负载,满负载意味着在参数更新时并不是所有参数同步进行更新,而是先进行一部分参数的更新,另外一部分参数更新则会滞后处理。从模型训练的整体训练时间来看,该种参数部署方法由于有参数更新滞后处理现象,与无参数更新滞后处理现象的参数部署方法相比较,其所花费的训练时间更长。可见,当部署自gpu集群上的参数无法进行动态调度时,会影响gpu集群之间的负载均衡,导致模型的训练时间较长。
技术实现思路
1、本发明的目的在于提供一种实时迁移的动态gpu调度方法及系统,旨在解决上述现有技术在使用gpu集群进行生成式大模型训练时,部署自gpu集群上的参数无法进行动态调度的问题。
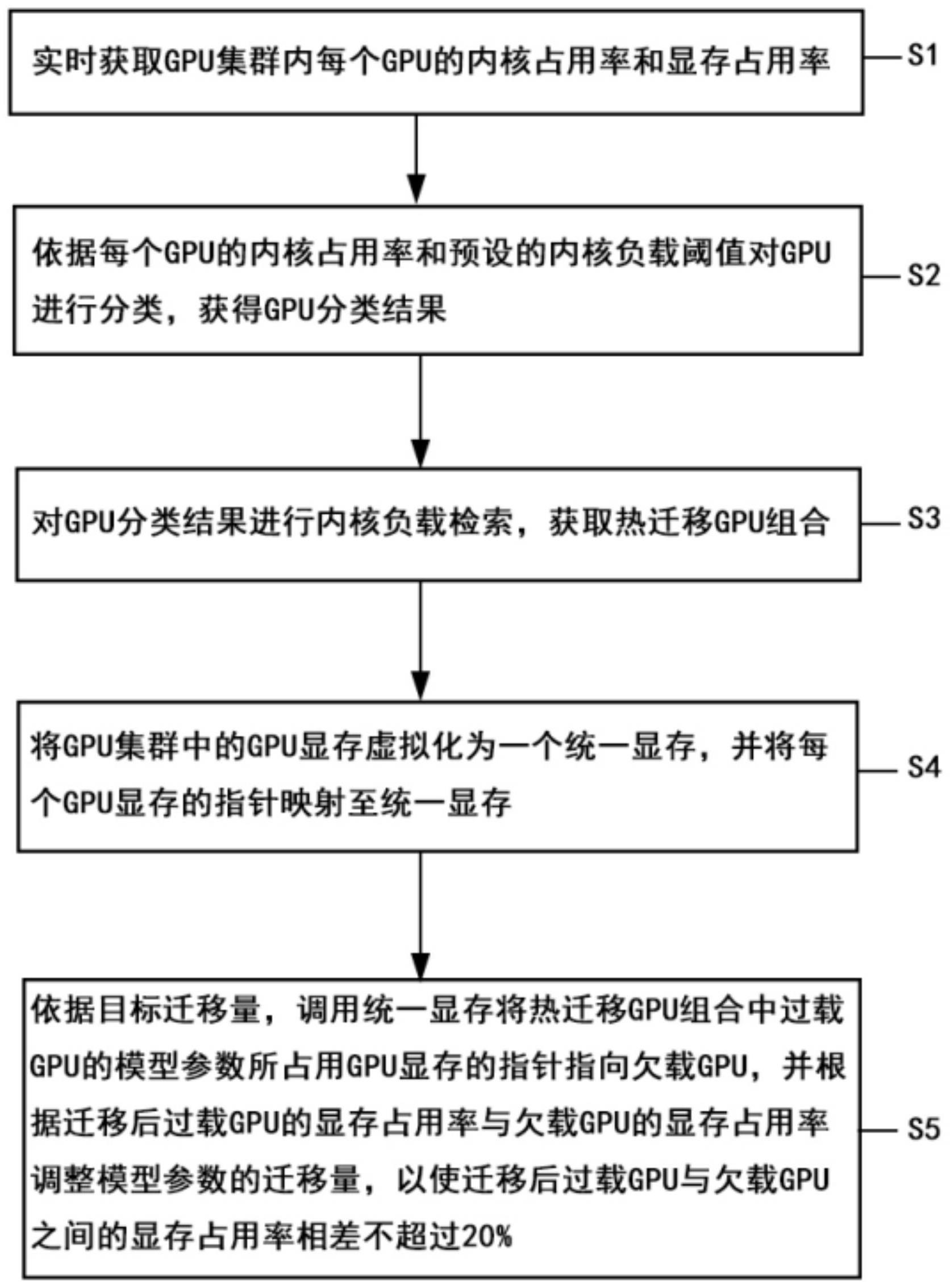
2、第一方面,本发明提供一种实时迁移的动态gpu调度方法,应用于生成式大模型训练,所述方法包括:
3、实时获取gpu集群内每个gpu的内核占用率和显存占用率;
4、依据每个gpu的内核占用率和预设的内核负载阈值对所述gpu进行分类,获得gpu分类结果;所述gpu分类结果包括过载gpu、负载均衡gpu和欠载gpu;
5、对所述gpu分类结果进行内核负载检索,获取热迁移gpu组合;所述热迁移gpu组合包括一个过载gpu和一个欠载gpu;
6、将所述gpu集群中的gpu显存虚拟化为一个统一显存,并将每个gpu显存的指针映射至所述统一显存;
7、依据目标迁移量,调用所述统一显存将所述热迁移gpu组合中过载gpu的模型参数所占用gpu显存的指针指向所述欠载gpu,并根据迁移后过载gpu的显存占用率与欠载gpu的显存占用率调整模型参数的迁移量,以使迁移后所述过载gpu与所述欠载gpu之间的显存占用率相差不超过20%。
8、进一步地,所述实时获取gpu集群内每个gpu的内核占用率和显存占用率,包括:
9、在生成式大模型训练时,利用cuda内置的占用率评估函数实时监测并记录所述gpu集群中每个gpu的内部参数;
10、依据记录的内部参数对每个gpu的内核占用情况进行评估,获得每个gpu的内核占用率;
11、实时统计每个gpu上与显存使用相关的api数量,并根据所述api数量对每个gpu的显存占用情况进行评估,获得每个gpu的显存占用率。
12、进一步地,还包括:
13、若所述gpu上部署的模型参数未发生变动,则gpu实时的内核占用率沿用初始获得的内核占用率。
14、进一步地,所述依据每个gpu的内核占用率和预设的内核负载阈值对所述gpu进行分类,获得gpu分类结果,包括:
15、预先设置内核负载阈值;所述内核负载阈值包括第一内核负载阈值和第二内核负载阈值,且第一内核负载阈值大于第二内核负载阈值;
16、将每个gpu的内核占用率与第一内核负载阈值和第二内核负载阈值进行比较,若gpu的内核占用率高于第一内核负载阈值,则确定gpu为过载gpu;若gpu的内核占用率低于第二内核负载阈值,则确定gpu为欠载gpu;若gpu的内核占用率位于第一内核负载阈值和第二内核负载阈值之间,则确定gpu为负载均衡gpu。
17、进一步地,所述依据目标迁移量,调用所述统一显存将所述热迁移gpu组合中过载gpu的模型参数迁移至所述欠载gpu,并根据迁移后过载gpu的显存占用率与欠载gpu的显存占用率调整模型参数的迁移量,以使迁移后所述过载gpu与所述欠载gpu之间的显存占用率相差不超过20%,包括:
18、按照目标迁移量确定所述热迁移gpu组合中过载gpu需要迁移的模型参数,调用所述统一显存将过载gpu需要迁移的模型参数所占用的显存的指针指向所述欠载gpu在所述统一显存中的地址,完成过载gpu的模型参数迁移;
19、迁移完成后分别获取过载gpu的显存占用率和欠载gpu的显存占用率,并将过载gpu的显存占用率和欠载gpu的显存占用率进行比较,判断迁移后过载gpu与欠载gpu之间的显存占用率相差是否超过20%,若相差超过20%,则增加或减少所述过载gpu的模型参数的迁移量;若相差不超过20%,则确定过载gpu与欠载gpu之间显存占用状况为均衡状态,完成模型参数迁移。
20、进一步地,所述对所述gpu分类结果进行内核负载检索,获取热迁移gpu组合之后,还包括:
21、若获取到多个迁移gpu组合,则将多个热迁移gpu组合依次存入线性表。
22、进一步地,还包括:
23、循环读取所述线性表中的热迁移gpu组合,并基于读取的热迁移gpu组合,依据目标迁移量,调用所述统一显存将过载gpu的模型参数迁移至所述欠载gpu;根据迁移后过载gpu的显存占用率与欠载gpu的显存占用率调整模型参数的迁移量,以使迁移后所述过载gpu与所述欠载gpu之间的显存占用率相差不超过20%;
24、所述线性表循环读取完毕后,实时获取所述gpu集群内每个gpu的内核占用率,并依据预设的内核负载阈值判断所述gpu集群内是否还存在过载gpu,若还存在过载gpu,则生成新的线性表,并循环读取新的线性表,完成过载gpu的模型参数迁移。
25、第二方面,本发明还提供一种实时迁移的动态gpu调度系统,包括:
26、监测模块,用于实时获取模型训练时gpu集群内每个gpu的内核占用率和显存占用率;
27、分类模块,用于依据每个gpu的内核占用率和预设的内核负载阈值对所述gpu进行分类,获得gpu分类结果;所述gpu分类结果包括过载gpu、负载均衡gpu和欠载gpu;
28、检索模块,用于对所述gpu分类结果进行内核负载检索,获取热迁移gpu组合;所述热迁移gpu组合包括一个过载gpu和一个欠载gpu;
29、迁移模块,用于将所述gpu集群中的gpu显存虚拟化为一个统一显存,并将每个gpu显存的指针映射至所述统一显存,以及依据目标迁移量,调用所述统一显存将所述热迁移gpu组合中过载gpu的模型参数所占用gpu显存的指针指向所述欠载gpu,以使迁移后所述过载gpu与所述欠载gpu之间的显存占用率相差不超过20%。
30、进一步地,所述监测模块具体包括内核监测子单元和显存监测子单元;其中,
31、所述内核监测子单元用于利用cuda内置的占用率评估函数实时监测并记录所述gpu集群中每个gpu的内部参数,并依据记录的内部参数对每个gpu的内核占用情况进行评估,获得每个gpu的内核占用率;
32、显存监测子单元用于实时统计每个gpu上与显存使用相关的api数量,并根据所述api数量对每个gpu的显存占用情况进行评估,获得每个gpu的显存占用率。
33、进一步地,所述检索模块还用于将内核负载检索获得的多个热迁移gpu组合依次存入线性表。
34、本发明的有益效果体现在,通过本发明提供的一种实时迁移的动态gpu调度方法,在生成式大模型训练时,先实时获取gpu集群内每个gpu的内核占用率和显存占用率;并依据每个gpu的内核占用率和预设的内核负载阈值对gpu进行分类,确定gpu内核的负载状态,从而判断出gpu是否过载。同时进一步以gpu对的形式对gpu分类结果进行内核负载检索,获取热迁移gpu组合,得到gpu集群中的过载gpu和欠载gpu;更进一步地,将gpu集群中的gpu显存虚拟化为一个统一显存,并将每个gpu显存的指针映射至所述统一显存,使得gpu集群中的所有gpu都可访问统一显存,从而保证模型训练过程不会被中断;最后结合gpu的内核占用率和显存占用率,依据目标迁移量,调用统一显存将热迁移gpu组合中过载gpu的模型参数所占用gpu显存的指针指向欠载gpu,把过载gpu的模型参数动态迁移调度到欠载gpu上进行参数更新,从而实现gpu集群整体的动态负载均衡,缩短了生成式大模型训练的时间,提高了gpu集群的整体利用率。
- 还没有人留言评论。精彩留言会获得点赞!