一种基于机器学习的市政污水的水质分类方法
本发明属于污水水质分析领域,特别涉及一种基于机器学习的市政污水的水质分类方法。
背景技术:
1、水质在世界范围内都存在问题。在人口稠密的地区,由于人类活动、城市化、工业化和废物处理,水质参数急剧恶化。水质评估当前面临着全球性挑战,且水质评估对维护水体健康和人体安全至关重要。水质差的水体,溶解氧含量低,不适宜水中生物生存,且极易影响周边环境和危害人体健康。然而水体情况复杂,评估水质指标的种类丰富多样,选择具有代表性的指标来进行水体质量评价显得格外重要。市政污水是城市运转和人们生活中产生的废水,收集的废水会在污水厂中进行处理,达标后再排入附近河流。而市政污水在未处理前可评估一个城市的水质情况,以此来推测该城市发展情况和人们日常生活中具体行为,这不仅对城市经济发展重要,也有益于促进人们对水体保护的意识。
2、然而市政污水水质等级评估,存在以下几个问题,导致水质评估过程难以实现。第一,需要采集全国各市中污水处理厂中进水端水样,然而这个过程成本大,周期长,对样品的处理和测定也需要十分谨慎;第二,市政污水中水质情况复杂,需要找到具有代表性的评价指标来反映水体情况;第三,传统方法不足以满足我们对市政污水水质评估的要求,且需要更好的方法从众多指标中找到最关键的几个指标以及其对应的影响比重。
3、近年来,随着人工智能技术的发展,数据处理和数据分析能力也在迅速提升,机器学习涉及人工智能,作为一门现代科学,可以应用于数据挖掘和预测分析。它的优势在于可以解决传统方法无法解决的复杂非线性关系数据的分析与处理问题,且能够通过利用大数据找到问题背后的规律。相同水质之间存在紧密联系,因此机器学习可以为评估市政污水水质等级提供技术支持。
技术实现思路
1、发明目的:本发明所要解决的技术问题是针对现有技术的不足,本发明从市政污水不同等级的水体之间存在紧密联系的角度出发,利用机器学习聚类算法和分类算法,来寻找出在一个等级上的相同水体,并且挖掘出影响相同水体聚集在一起或分离的关键指标,为市政污水水质等级评估提供一个参考和标准。
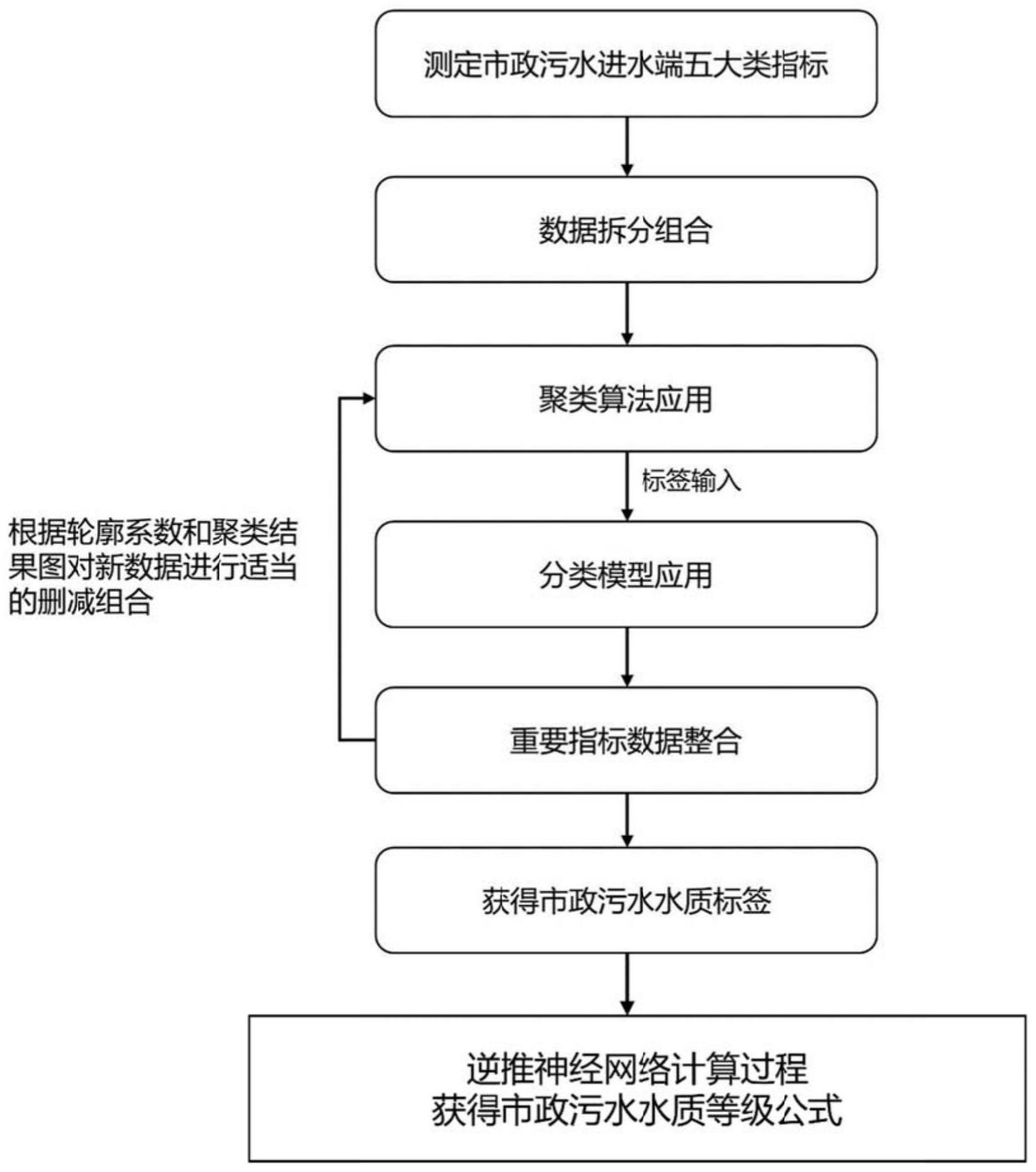
2、本发明具体提供了一种基于机器学习的市政污水的水质分类方法,包括以下步骤:
3、步骤1,建立市政污水数据库并对数据进行预处理;
4、步骤2,采用聚类算法对数据库中的数据进行处理;
5、步骤3,采用分类算法得到分类结果,分类结果按照准确度、召回率、f-1分数和精确度来评价,获取重要性排前3的指标;
6、步骤4,获取水质关键指标水质分类标签;
7、步骤5,对市政污水水质等级进行划分;
8、步骤6,将筛选出的关键指标数据和水质标签通过逆推神经网络的原理整理出市政污水水质等级公式。
9、步骤1包括:
10、步骤1-1,测定市政污水进水端五大类指标:常规指标、毒性指标、金属离子指标、ppcps和pfos;
11、步骤1-2,将市政污水数据按照五大类指标划分为五大类数据,然后将每一大类数据与别的一个或两个以上大类数据进行组合,得到数据库;
12、步骤1-3,采用当地污水处理厂测定指标的平均值来代替收集的数据中的缺失值、异常值或重复值。
13、步骤2包括:
14、步骤2-1,对数据库中的数据进行标准化和pca降维,标准化和pca降维采用python自带的pandas库来进行处理;
15、步骤2-2,通过聚类算法对数据库中的数据进行聚类,按轮廓系数和聚类结果图来评价聚类效果;聚类效果图根据二维图进行综合评价;
16、步骤2-3,从根据每一大类指标进行组合的数据的聚类结果中,除了当前大类指标单独聚类结果,额外选择最好的两份组合聚类结果,作为初级分类标签。
17、步骤2-2中,通过聚类算法将数据库中的数据分为了k个簇,对于簇中的每个向量,分别计算它们的轮廓系数:
18、对于k个簇中的一个向量i:
19、计算i向量到同一簇内其他点不相似程度的平均值a(i)=average(x1);
20、计算i向量到其他簇的平均不相似程度的最小值b(i)=min(x2);
21、其中,x1表示i向量到所有i向量属于的簇中其它点的距离;x2表示i向量到一个不包含i向量的簇内的所有点的平均距离;
22、i向量轮廓系数为:
23、可见轮廓系数的值是介于[-1,1],越趋近于1代表内聚度和分离度都相对较优;
24、将所有向量的轮廓系数求平均,就是聚类结果总的轮廓系数;
25、对于聚类效果图,根据二维和三维图中簇与簇之间的距离、簇内散点的数量和不同簇间的散点交错程度来评价。
26、步骤2-3中,除了将组合数据中的最优聚类结果作为初级分类标签,还需要获取对应大类指标的单独聚类结果作为初级分类标签。
27、步骤3包括:
28、步骤3-1,使用机器学习中的分类算法对进行聚类后的数据进行处理;
29、步骤3-2,将分类结果进行分析,分类结果会得出所有指标的重要性,获取重要性排前y的指标,在大部分指标的分值均较低的情况下,选择重要性排前三的指标(在预实验中会有一两个指标的重要性几乎加起来达到1了,剩下的都是0.0001几的情况。这种情况就取前三);如果大部分指标的分值均较高,选择重要性排前五的指标。
30、步骤4包括:
31、步骤4-1,将步骤3得到的指标整合成一份新的数据;
32、步骤4-2,重复步骤2~步骤3,将整合得到的新的数据,再次进行聚类、分类算法,对整合的新的数据进行删减,最终选取最好的一类作为水质分类最终标签。
33、步骤4-1中,将重要性排前三的指标提出来,进行整合,如果有重复的指标则按同一个指标来处理。
34、步骤4-2中,对整合的新的数据进行删减时,每一大类指标最终保留至少一个指标。
35、步骤5包括:
36、步骤6-1,根据步骤4得到的结果,获得关键指标和水质标签,放入神经网络进行训练;
37、步骤6-2,通过逆推神经网络过程获得市政污水水质等级公式:
38、yn=(w1nx1+w2nx2+w3nx3+…+wnnxn+bn)
39、其中,yn为第n个水质标签(根据最终聚类结果有几类就有几个标签),xn为筛选出的第n个最终关键水质指标,wnn为筛选出的第n个最终关键水质指标的权重值,bn为神经网络中输入层与隐藏层之间神经元的偏移量,这些参数可通过python构建神经网络模型得出。。
40、有益效果:当前,水质评价与管控通常是基于对单一水质理化指标的控制,已经无法在新型污染物不断生成的复杂水环境中全面评价和指导污水水质提升。为进一步加强污水水质提升,迫切需要筛查关键的污水水质指标,并对污水水质影响因素进行分析。针对传统水质评价指标选择依赖于主观经验的问题,开展多维污水水质指标关联规律挖掘,建立数据驱动的水质指示性指标筛查方法,可为水质评价工作明确有效的指标体系,为污水管控工作提供目标导向与政策建议。
- 还没有人留言评论。精彩留言会获得点赞!