基于深度强化学习的动态作业车间调度优化方法及系统
本发明涉及动态作业车间调度,特别是涉及基于深度强化学习的动态作业车间调度优化方法及系统。
背景技术:
1、本部分的陈述仅仅是提到了与本发明相关的背景技术,并不必然构成现有技术。
2、作业车间调度问题(jssp)是一个复杂的组合优化问题,同时,该问题在制造业中有着十分重要的应用,合理的调度可以有效利用现有的生产资源,减少生产时间,提高生产效率。在解决作业车间调度问题jssp时,通常是先假定一个静态的生产环境,所有的加工信息都已事先知道,然后制定一个确定性的调度计划,在加工过程中不进行修改,但是,在实际生产中,这样的解决方法并不是有效的,因为在实际生产中,总是存在一些不可知的动态事件,例如,订单的插入、取消或修改,机器故障,加工时间的变化等等,这些都是需要考虑在内的,尤其是在当今现代化的工业生产中,更要去考虑一些动态的事件。因此动态作业车间调度问题(djssp)更加适合现代化的工业生产,解决动态作业车间调度问题对于推动制造业发展提高生产力具有十分重大的意义。
3、目前有多种求解djssp的方法,其中最常用的是基于调度规则的方法,该方法采用特定的优先级规则(例如,先进先出,最短加工时间等)来在请求时调度作业。基于调度规则的方法具有简单性、可解释性和低计算复杂性的优点,可以快速响应动态事件。然而,传统的手动设计调度规则的方式是一个繁琐耗时的过程,需要大量的领域知识和代码工作。此外,并不存在一种调度规则适用于所有情景。
4、元启发式算法,例如,遗传算法、模拟退火算法、禁忌搜索算法等方法在求解静态jssp时取得了不错的效果,虽然这些元启发式方法能获得高质量的调度方案,但是它们比较耗时,无法及时响应动态事件,因此,元启发式方法不适合直接去求解动态作业车间调度问题。
5、为了减少设计有效启发式算法的繁琐工作并减轻对专业知识的依赖,在过去的十年里,自动生成规则的方向已经得到了探索。在这个方向上,最流行的方法是基于遗传编程(gp)的超启发式方法,可以被定义为一种先进的自动搜索方法,它探索一个由低级启发式(例如规则)构成的搜索空间,以解决计算难题。尽管基于遗传编程gp的方法取得了良好的结果,但这些方法演化出的规则在整个调度过程中都是固定的,无法在面对不断变化的制造环境时自适应地解决问题。最近,深度强化学习(drl)在自动学习解决复杂调度问题的策略方面表现出了良好的性能。与遗传编程gp不同,深度强化学习drl方法是复杂的参数化技术,可以建立从环境状态到动作的端到端的映射,其中神经网络充当值或策略的表示。因此,深度强化学习drl方法具有适应不同调度状态的能力,更加适合求解djssp。然而,大多数现有的工作集中在假设完全了解问题实例的静态问题上,这样难以应对具有随机作业到达的高度动态环境,例如,一些工作使用固定维度的向量或矩阵来表示状态,并采用多层感知器(mlp)或卷积神经网络(cnn)来提取状态特征,这些方法训练的策略无法解决不同规模的问题实例,因此不适用于动态问题。一些较新的方法利用图结构来捕捉不同调度状态中作业/操作与机器之间的复杂关系,并采用图神经网络(gnn)来设计端到端的调度策略,这些策略可以处理不同规模的问题实例,然而这些方法依旧无法处理作业随机到达的作业车间调度问题djssp,因为这些方法在构建图结构时需要用到所有作业的信息,在作业随机到达的作业车间调度问题djssp中,到达的总作业数量以及作业达到的时间都是未知的,但是,最近的一项工作通过扩展以往工作中图神经网络(gnn)的架构,只使用已到达的作业的操作来构建图,实现了作业车间调度问题djssp端到端的调度,然而受限于gnn网络结构的复杂性,此方法只能应用在小规模的问题上,无法扩展到大规模的实际应用中。在处理作业随机到达的作业车间调度问题djssp时最主流的drl方法是采用现有的调度规则或自己设计的调度流程作为动作来应对作业的随机到达,但是这样最终的调度效果会受到调度规则的效果的限制,也就是说drl训练效果的天花板受到了限制。
技术实现思路
1、为了解决现有技术的不足,本发明提供了基于深度强化学习的动态作业车间调度优化方法及系统;该方法可以处理任意规模的作业车间调度问题djssp,相较于基于图的深度强化学习drl方法,更适合处理大规模的作业车间调度问题djssp,并且可以突破优先级规则所带来的限制,具有十分重大的实际应用价值。
2、一方面,提供了基于深度强化学习的动态作业车间调度优化方法,包括:
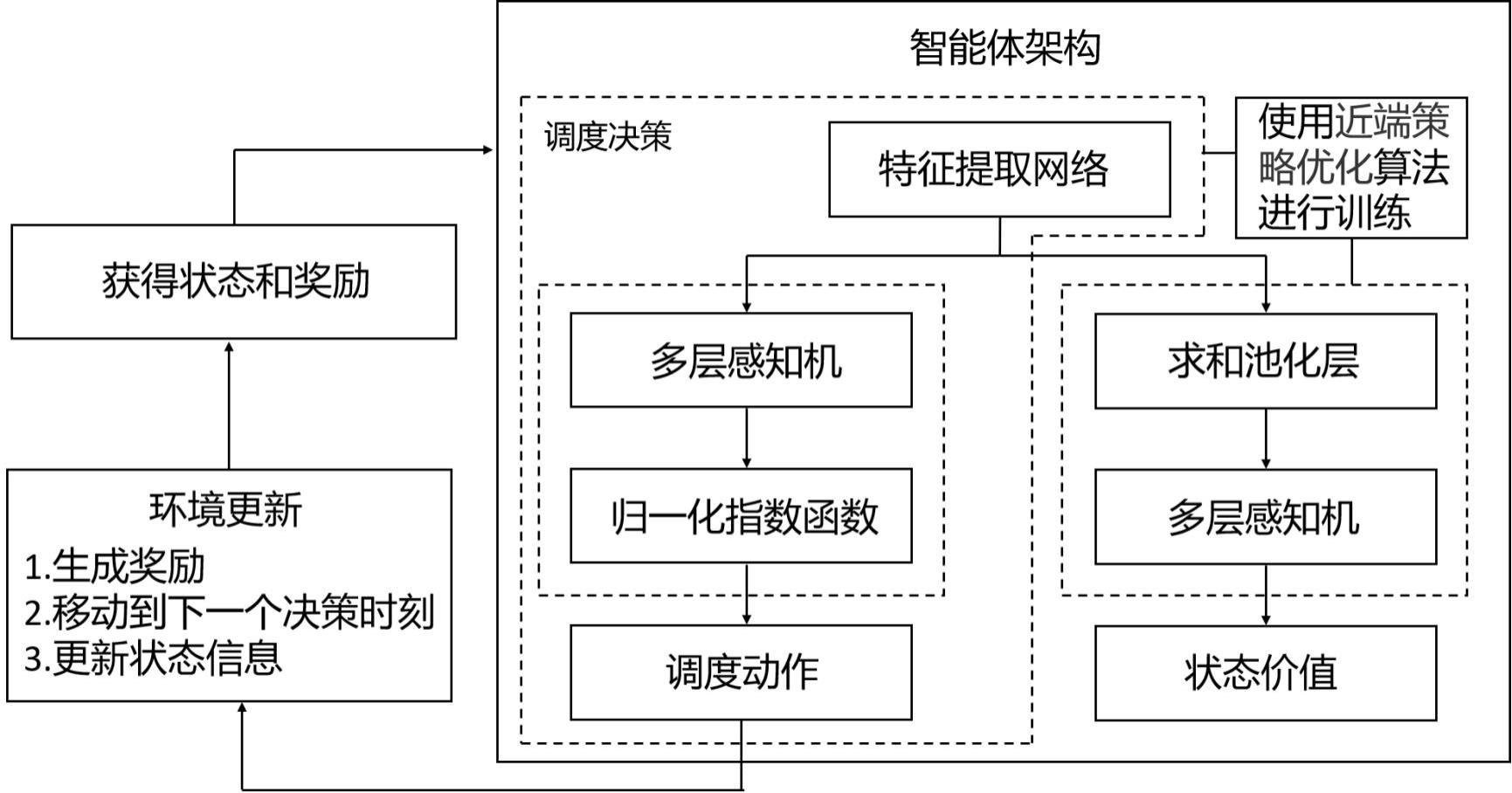
3、获取当前决策时刻的合法作业本身的作业特征,和合法作业当前操作完成后要访问的机器的机器特征,将所述作业特征和所述机器特征串联拼接后,组成一个合法作业的状态特征向量,将所有合法作业的状态特征向量进行拼接,得到状态矩阵;
4、将状态矩阵输入到训练后的智能体中,训练后的智能体输出每一个作业对应的被调度概率,选择概率最高的作业进行调度,完成在动态作业环境下的优化调度;
5、其中,训练后的智能体,包括:特征提取网络、策略网络和价值网络;训练后的智能体的特征提取网络,对状态矩阵进行特征提取,提取出状态特征向量; 训练后的智能体的策略网络,对状态特征向量进行处理,输出每一个作业对应的被调度概率。
6、另一方面,提供了基于深度强化学习的动态作业车间调度优化系统,包括:
7、获取模块,其被配置为:获取当前决策时刻的合法作业本身的作业特征,和合法作业当前操作完成后要访问的机器的机器特征,将所述作业特征和所述机器特征串联拼接后,组成一个合法作业的状态特征向量,将所有合法作业的状态特征向量进行拼接,得到状态矩阵;
8、调度模块,其被配置为:将状态矩阵输入到训练后的智能体中,训练后的智能体输出每一个作业对应的被调度概率,选择概率最高的作业进行调度,完成在动态作业环境下的优化调度;
9、其中,训练后的智能体,包括:特征提取网络、策略网络和价值网络;训练后的智能体的特征提取网络,对状态矩阵进行特征提取,提取出状态特征向量; 训练后的智能体的策略网络,对状态特征向量进行处理,输出每一个作业对应的被调度概率。
10、再一方面,还提供了一种电子设备,包括:
11、存储器,用于非暂时性存储计算机可读指令;以及
12、处理器,用于运行所述计算机可读指令,
13、其中,所述计算机可读指令被所述处理器运行时,执行上述第一方面所述的方法。
14、再一方面,还提供了一种存储介质,非暂时性存储计算机可读指令,其中,当非暂时性计算机可读指令由计算机执行时,执行第一方面所述方法的指令。
15、再一方面,还提供了一种计算机程序产品,包括计算机程序,所述计算机程序当在一个或多个处理器上运行的时候用于实现上述第一方面所述的方法。
16、上述技术方案中的一个技术方案具有如下优点或有益效果:
17、首先,使用合法作业的信息来表征状态,即使用一个维度可变的矩阵来表征状态,这样的状态表征方式使得本发明可以轻松应对随机动态到达的作业。然后,再将这些合法作业的信息依次通过网络,得到这些合法作业的得分,然后再使用softmax函数进而得到这些合法作业的概率分布,即动作的概率分布。
18、然后,将合法的作业作为动作,突破了传统深度强化学习(drl)将调度规则作为动作的限制,具有更高的训练天花板。
19、最后,使用近端策略优化(ppo)算法来对智能体进行训练。本发明所公开的方法可以处理任意规模的动态作业车间调度问题,并且相比于以调度规则作为动作的drl方法具有更高的训练天花板,可以更好的发挥出drl的优势。
- 还没有人留言评论。精彩留言会获得点赞!