一种跨语言场景下的日志收集方法与流程
本发明涉计算机,尤其涉及一种跨语言场景下的日志收集方法。
背景技术:
1、日志是指系统所指定对象的某些操作和其操作结果按时间有序的集合。每个日志文件由日志记录组成,每条日志记录描述了一次单独的系统事件。通常情况下,系统日志是用户可以直接阅读的文本文件,日志文件中的记录可提供以下用途:监控系统资源;审计用户行为;对可疑行为进行告警;确定入侵行为的范围;为恢复系统提供帮助;生成调查报告;为打击计算机犯罪提供证据来源。
2、由于网络中不同的操作系统、应用软件、网络设备和服务产生不同语言的日志文件,即使相同的服务如iis也可采用不同格式的日志文件记录日志信息。国际上还没有形成标准的日志格式,各系统开发商和网络设备生产商往往根据各自的需要制定自己的日志格式,使得计算机系统针对跨语言形成的日志的格式和存储方式千差万别,因此,针对跨语言场景下的日志的处理技术的开发尤为迫切。
3、公开号为cn103714179a的中国专利申请,一种系统日志的多语言支持方法和系统从接收的系统日志中提取日志格式以及日志格式参数;根据当前系统的语言环境,在存储的日志格式在每种语言环境下的格式化字符串中找到与接收日志格式对应的格式化字符串;将与接收日志格式对应的格式化字符串与所述日志格式参数进行组合,得到当前系统语言环境支持的系统日志,可见,所述存在问题如下:没有对系统产生的日志代码进行匹配语言种类的判定和修正,导致针对跨语言场景下的日志转化的正确率不足。
技术实现思路
1、有鉴于此,本发明提供一种跨语言场景下的日志收集方法,用以克服现有技术中没有对系统产生的日志代码进行匹配语言种类的判定和修正,导致针对跨语言场景下的日志转化的正确率不足的问题。
2、为实现上述目的,本发明提供一种跨语言场景下的日志收集方法,包括:
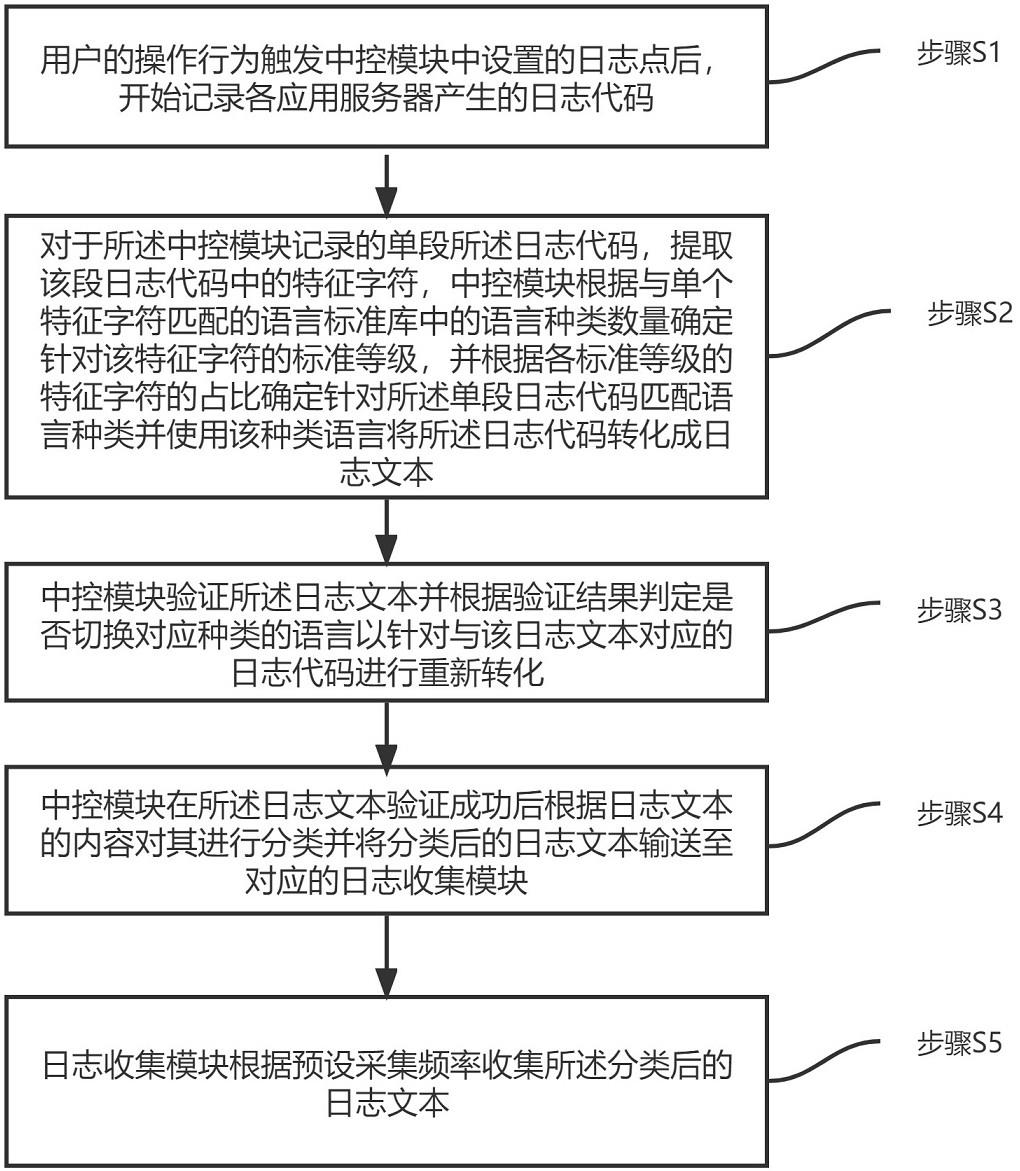
3、步骤s1,用户的操作行为触发中控模块中设置的日志点后,开始记录各应用服务器产生的日志代码;
4、步骤s2,对于所述中控模块记录的单段所述日志代码,提取该段日志代码中的特征字符,中控模块根据与单个特征字符匹配的语言标准库中的语言种类数量确定针对该特征字符的标准等级,并根据各标准等级的特征字符的占比确定针对单段日志代码匹配语言种类并使用匹配的语言种类将所述日志代码转化成日志文本;
5、步骤s3,所述中控模块验证所述日志文本并根据验证结果判定是否切换对应种类的语言以针对与该日志文本对应的日志代码进行重新转化;
6、步骤s4,所述中控模块在所述日志文本验证成功后根据日志文本的内容对其进行分类并将分类后的日志文本输送至对应的日志收集模块;
7、步骤s5,所述日志收集模块根据预设采集频率收集所述分类后的日志文本。
8、进一步地,在所述步骤s2中,所述中控模块将单段所述日志代码中提取的各特征字符依次与所述语言标准库中的第i类语言的标准字符进行比对,设定i=1...n,n为语言标准库中语言种类的总数,对于单个特征字符,中控模块根据该特征字符匹配语言标准库中语言种类数量确定针对该特征字符标准等级的判定方式,其中,
9、第一特征字符判定方式为所述中控模块判定所述特征字符为针对第i类语言的一级特征字符;所述第一特征字符判定方式满足所述特征字符仅与所述第i类语言匹配;
10、第二特征字符判定方式为所述中控模块判定所述特征字符为针对第i类语言的二级特征字符;所述第二特征字符判定方式满足所述特征字符与包括所述第i类语言的多个种类语言匹配;
11、第三特征字符判定方式为所述中控模块判定所述特征字符为三级特征字符;所述第三特征字符判定方式满足所述特征字符与所述语言标准库中的全部种类语言匹配。
12、进一步地,所述中控模块在第一预设条件下根据各特征字符占比确定与单段所述日志代码匹配的语言种类的判定方式,其中:
13、第一判定方式为所述中控模块判定单段所述日志代码无匹配语言,并根据第一预设一级特征字符占比与一级特征字符占比的差值将该段日志代码分割成字符串的长度降低至对应值;所述第一判定方式满足单段所述日志代码中属于所述语言标准库中各类语言的所述一级特征字符占比均小于第一预设一级特征字符占比,且该段日志代码中的三级特征字符占比大于等于预设三级特征字符占比;
14、第二判定方式为所述中控模块判定单段所述日志代码匹配多种语言,中控模块统计该段日志代码中属于对应种类语言的二级特征字符数量,并根据各二级特征字符的占比确定针对该段日志代码匹配的语言种类的判定方式;所述第二判定方式满足所述语言标准库中存在多个种类语言,单段所述日志代码中属于上述各类语言的所述一级特征字符占比均大于等于所述第一预设一级特征字符占比并均小于第二预设一级特征字符占比,且该段日志代码中的三级特征字符占比小于预设三级特征字符占比;
15、第三判定方式为所述中控模块判定单段所述日志代码匹配单种语言,中控模块分别统计该段日志代码的语言中能够应用于对应种类语言的一级特征字符的数量并将数量最多的一级特征字符所属种类的语言作为用于该段日志代码的语言;所述第三判定方式满足所述语言标准库中存在若干种类语言,单段所述日志代码中属于上述语言的所述一级特征字符占比均大于等于所述第二预设一级特征字符占比,且该段日志代码中的三级特征字符占比小于预设三级特征字符占比;
16、所述第一预设条件满足所述中控模块完成对单段所述日志代码中全部特征字符标准等级的判定。
17、进一步地,在所述步骤s2中,所述中控模块将所述单段日志代码分割成多个具有预设长度的字符串,分别解析分割后的字符串,并滤除解析后的符号以及信号码元以完成该段日志代码中特征字符的提取,中控模块根据提取的特征字符生成针对该段日志代码的日志文本。
18、进一步地,所述中控模块在所述第二判定方式下根据所述第i类语言的二级特征字符与总特征字符的占比确定针对该段日志代码匹配语言的种类的判定方式,其中,
19、第一语言判定方式为所述中控模块判定选取对应的一级特征字符数量最高的语言将该单段日志代码转化成第一日志文本;所述第一语言判定方式满足单段所述日志代码中属于所述第i类语言的所述二级特征字符的占比小于预设二级特征字符占比;
20、第二语言判定方式为所述中控模块判定使用第i类语言将单段日志字符转化成第二日志文本;所述第二语言判定方式满足单段所述日志代码中属于所述第i类语言的所述二级特征字符的占比大于等于预设二级特征字符占比。
21、进一步地,所述中控模块设置有在第一判定方式下缩短所述单段日志代码分割的字符串的长度的若干长度的调节方式,其中,每种调节方式对缩短字符串的长度的调节大小不同。
22、进一步地,所述中控模块在所述第三判定方式下根据转化后的所述日志文本的准确率判定选用的语言种类与所述单段日志代码的匹配是否符合预设标准并在判定该类语言与该段日志代码的匹配不符合预设标准时重新统计该段日志代码中的二级特征字符并使用包含对应二级特征字符数量最多的语言将该段日志字符转化成第三日志文本,或,重新选取对应的一级特征字符数量次高的语言将该段日志字符转化成第四日志文本。
23、进一步地,所述中控模块在第一准确率比对条件下重新统计该段日志代码中的二级特征字符并使用包含对应二级特征字符数量最多的语言将该段日志字符转化成第三日志文本,以及在第二准确率比对条件下重新选取对应的一级特征字符数量次高的语言将该段日志字符转化成第四日志文本。
24、进一步地,所述第一准确率比对条件满足所述转化后的日志文本的准确率小于第一预设准确率,以及第二准确率比对条件满足所述转化后的日志文本的准确率大于所述第一预设准确率且小于第二预设准确率。
25、进一步地,所述日志文本的分类包括:应用程序、安全、升级、系统、转发事件、应用程序以及服务日志。
26、与现有技术相比,本发明的有益效果在于,本发明通过中控模块记录的单段所述日志代码,提取该段日志代码中的特征字符,中控模块根据与单个特征字符匹配的语言标准库中的语言种类数量确定针对该特征字符的标准等级,并根据各标准等级的特征字符的占比确定针对所述单段日志代码匹配语言种类并使用该种类语言将所述日志代码转化成日志文本,从而解决了针对跨语言场景下的日志转化的正确率不足的问题,保证了日志的顺利收集和后处理。
27、进一步地,本发明的中控模块将单段所述日志代码中提取的各特征字符依次与所述语言标准库中的第i类语言的标准字符进行比对确定了针对单段日志代码中单个字符等级的判定方式,本发明将日志代码的每个特征字符进行划分,将每个字符对应不同的语言的种类数,从而为选取正确的识别语言提供了可行性基础。
28、进一步地,本发明的中控模块在完成特征字符标准等级划分后,根据各特征字符占比确定与单段所述日志代码匹配的语言种类的判定方式,从而精准的确定了日志代码匹配的语言种类。
29、进一步地,中控模块将所述单段日志代码分割成多个具有预设长度的字符串,分别解析分割后的字符串,并滤除解析后的符号以及信号码元以完成该段日志代码中特征字符的提取,保证了提取的有效性。
30、进一步地,本发明的中控模块根据第i类语言的二级特征字符与总特征字符的占比确定了选取对应的一级特征字符数量最高的语言将该单段日志代码转化成第一日志文本或使用第i类语言将该单段日志字符转化成第二日志文本,从而准确的将日志代码转化成相应的可读的日志文本。
31、进一步地,当中控模块判定单段所述日志代码无匹配语言时,中控模块通过不通的调节方式将字符串的长度对应的缩短,从而重新调整字符串的分割长度,以解决单段所述日志代码无匹配语言的问题。
32、进一步地,中控模块根据转化后的日志文本的准确率判定选用的语言种类与所述单段日志代码的匹配是否符合预设标准并在判定该类语言与该段日志代码的匹配不符合预设标准时重新选取语言。
33、进一步地,中控模块确定了重新统计该段日志代码中的二级特征字符并使用包含对应二级特征字符数量最多的语言将该段日志字符转化成第三日志文本和重新选取对应的一级特征字符数量次高的语言将该段日志字符转化成第四日志文本,从而提高了转化的日志文本的正确率。
34、进一步地,本发明对第一准确率比对条件和第二准确率比对条件划定了取值范围,从而保证了语言选择的准确性,进而解决针对跨语言场景下的日志转化的正确率不足的问题,保证了日志的顺利收集和后处理。
- 还没有人留言评论。精彩留言会获得点赞!